2023년 AI 기술 트렌드 둘러보기 #1 | AI Trends
🤖 2023년 10월의 AI 기술 동향과 주요 뉴스, 논문, 글, 사례를 정리했습니다.

KEYWORDS
인공지능 트렌드, 딥러닝 트렌드, 2023 인공지능 트렌드, 2023 인공지능 기술 트렌드, 최근 인공지능 동향, Recent AI Trend, AI Issue, AI News, Top AI Paper
💡 News
WGA와 AMPTP가 계약 합의하여 146일간의 작가 파업을 종결 1
- 작가 노동조합인 WGA가 AMPTP와의 새로운 3년 계약을 통해 AI 사용을 제한하는 협정을 진행했습니다.
- 이 계약으로 작가와 스튜디오 모두 일정 제약 내에서 AI를 사용할 수 있게 됐으며, 작가들은 스튜디오의 동의하에 AI 도구를 활용할 수 있지만, 텍스트 생성기를 사용할 의무는 없으며 스튜디오는 AI 사용을 명시해야 합니다.
생성 AI로 비디오 공유 2
- 유튜브가 2023년 말이나 2024년 초에 Gen AI를 도입하며 비디오 제작자들에게 주제 아이디어, 배경, 음악 제안, 오디오 번역 등을 제공할 예정입니다.
- TikTok은 AI 생성 콘텐츠에 대해 명확하게 라벨을 붙일 것을 요구하고 있습니다.
LinkedIn이 임베딩 기술을 활용하여 구직자들을 위한 매칭을 개선 3
- LinkedIn은 임베딩 기반 검색 및 추천 기능을 통해 회원 및 고객에게 보다 관련성 높은 결과물을 제공하고 있습니다.
- 이 기술은 회원 프로필 정보를 효율적으로 활용하여 맞춤형 추천과 검색 기능을 지원하고 임베딩을 활용한 검색 시스템은 유사한 의미를 가진 데이터를 서로 가깝게 배치하여 검색 효율성을 높입니다.
- 이를 지원하기 위해 LinkedIn은 새로운 인프라 구성 요소를 개발하고 다중 작업 학습 모델을 도입했습니다.
앱 및 기기 전반에 걸친 Meta AI의 새로운 기술 소개 4
- Meta AI를 활용한 새로운 업그레이드를 통해 페이스북, 인스타그램, 메신저, 왓츠앱에 채팅 인터페이스, 이미지 생성기, 유명인과의 연계 기능을 선보였습니다.
- LLaMa 2와 이미지 생성기를 활용하여, 실제 유명인들의 얼굴을 딴 챗봇을 만들고 있으며, Meta AI는 질문에 답하고 이미지를 생성하는데 활용됩니다.
- Emu 이미지 생성기는 다양한 프롬프트에 따라 이미지를 생성하거나 수정하고, 이를 스티커 형태로 공유할 수 있도록 합니다.
Large Language Models (in 2023) 5
- OpenAI ChatGPT 핵심 엔지니어 중 한 명이 최근 서울대학교에서 열린 Large Language Models (in 2023)에 대한 발표에서 좋은 내용을 공유했습니다.
- LLM의 능력이 점점 더 올라감에따라 관점 전환의 필요성을 강조하며 여러 시스템에 걸친 효율적인 행렬곱, Transformer Scaling의 기술적 복잡성에 대해 언급했습니다.
- Maximum likelihood 목적 함수를 잠재적인 bottleneck으로 식별하고 보다 표현력이 풍부한 신경망을 통해 학습하는 방식을 강조했습니다.
조니 아이브와 OpenAI의 ‘인공지능의 아이폰’ 6
- 애플의 조니 아이브와 OpenAI가 협력하여 약 10억 달러의 투자를 받아, 스크린에 의존하지 않는 혁신적인 인공지능 기기를 개발하는 계획을 진행 중입니다.
인공지능이 근무시간 단축을 야기함 7
- JPMorgan Chase의 CEO Jamie Dimon은 인공지능의 혜택에 대해 긍정적이며 이미 은행 내 수천 명의 직원들이 활용 중이라며, 이 기술이 근무시간을 줄여줄 것이라 예측합니다.
- 인공지능의 영향으로 전 세계에 약 3억 개의 직업이 영향을 받을 수 있다고 보고되었으며, AI는 노동 생산성을 향상시키고 세계 GDP를 최대 7%까지 높일 수 있다는 분석 결과도 있습니다.
Microsoft Fabric과 Databricks 8
- Vantage는 Microsoft Fabric과 Databricks 간의 가격 분석을 진행했습니다.
- Microsoft는 Synapse (데이터 웨어하우스 및 노트북), Power BI, Spark 및 약간의 머신러닝 기능을 통합한 거대한 플랫폼을 구축하여 모든 업무 관리를 간소화했습니다.
- Databricks는 다양한 워크플로, 컴퓨팅 및 저장소를 명확히 분리하여 각각을 다루고 있어 더욱 심층적인 분석이 가능합니다.
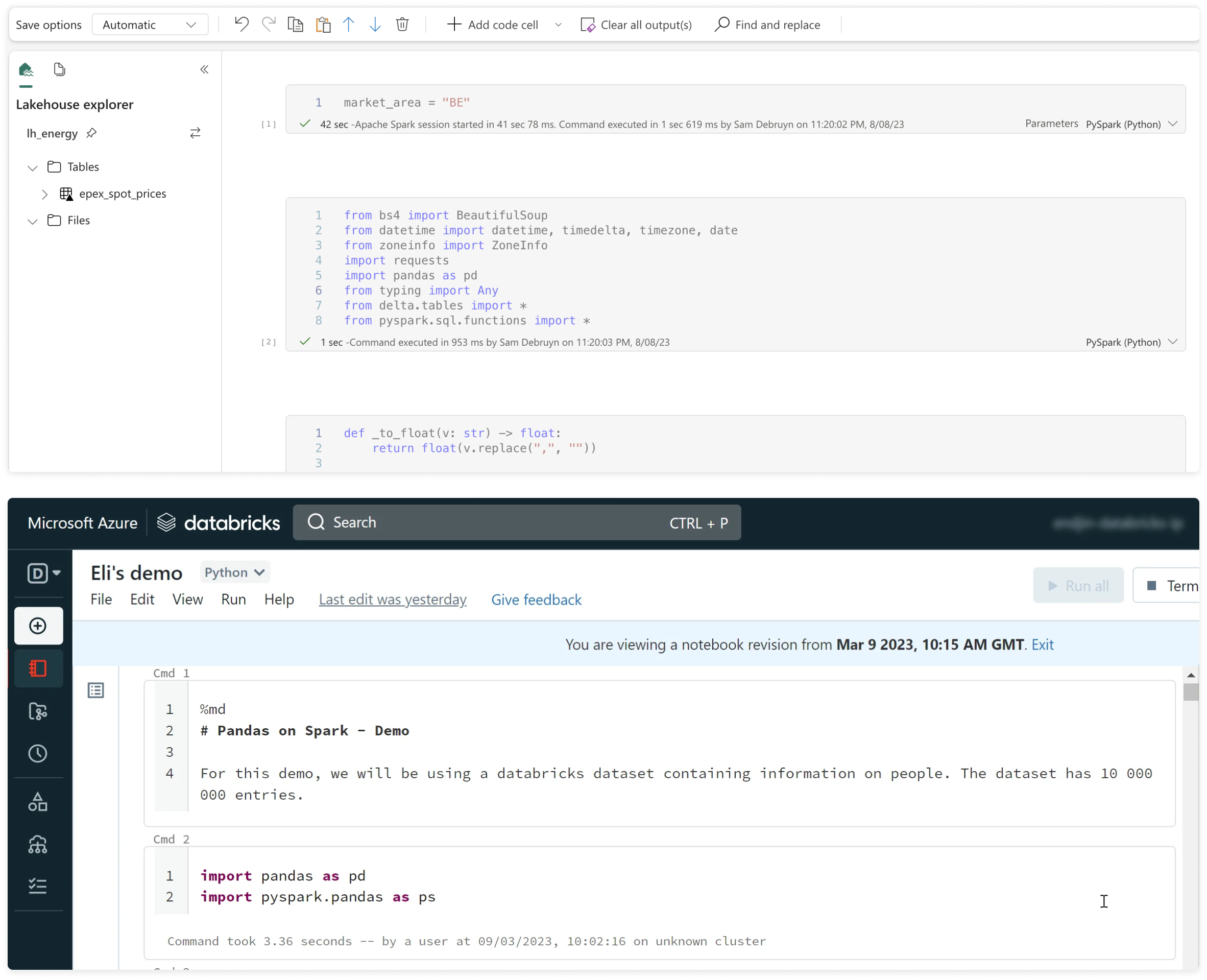 Notebook UI in Fabric vs Databricks
Notebook UI in Fabric vs Databricks
Confluent의 관리형 Apache Flink 서비스와 생성적 AI 기능 9
- Confluent는 Kafka 로드맵 과 Flink를 클라우드 서비스로 발표했습니다.
- 이는 Confluent가 Immerok을 인수한 결과입니다.
머신러닝을 활용한 날짜 형식 식별 10
- Dropbox의 자동화된 네이밍 규칙 도구를 소개하며, 파일명에서 날짜 구성요소를 기계학습을 통해 정확히 식별하여 효율적인 파일 관리를 제공하는 방법을 설명합니다.
- 사람들이 다양한 형식으로 날짜를 표기할 때 발생하는 복잡성을 극복하기 위해 광범위한 데이터를 학습시켜 모델을 향상시키고, 파일명 내 날짜의 위치를 식별하기 위해 Inside-Outside-Beginning 태깅을 활용하는 방식으로 다양한 날짜 포맷을 다루고 있습니다.
State of AI Report 2023 11
- 세계를 놀라게 한 GPT-4, 독점 모델 성능을 모방하려는 노력, 생명 과학 분야의 언어 모델 및 확산 모델을 통해 주도되는 실제 혁신과 같은 주요 동향을 논의합니다.
- NVIDIA가 주도하는 급성장하는 컴퓨팅 산업, 기술 가치 평가 침체 속에서 발생하는 생성 AI 스타트업의 증가, AI에 관해 현재 진행 중인 글로벌 안전 논쟁을 강조하며 최첨단 모델에 대한 강력한 평가의 필요성을 강조합니다.
Pixel 8 와 Pixel 8 Pro 12
- 구글의 Pixel 8과 Pixel 8 Pro가 출시되었고 두 장치 모두 사진과 비디오 편집을 위한 AI 기반 도구를 갖추고 있습니다.
마이크로소프트의 AI 비용 급증에 대비해 오픈AI에 대한 의존성을 줄이는 방안 13
- Microsoft 는 Windows, Microsoft 365, GitHub를 포함한 회사의 주력 제품을 보완하는 AI 기반 도구 제품군을 제공합니다.
- Copilot으로 알려진 이 라인은 OpenAI 모델을 기반으로 하며 비용을 관리하기 위해 Microsoft 개발자는 더 작은 모델이 더 큰 모델의 출력을 모방하도록 훈련되는 knowledge distillation와 기타 기술을 사용하고 있습니다.
Meta가 AI를 위해 맞춤형 실리콘을 개발하는 방법 14
- Meta의 첫 번째 AI 추론 가속기인 MTIA v1을 설계하고 개발하는 과정에 대해 이야기합니다.
- 이는 Meta의 AI 실리콘 팀이 소프트웨어 개발자가 보다 관련성 높은 콘텐츠와 더 나은 사용자 경험을 제공할 수 있는 AI 모델을 만들 수 있도록 인프라의 계산 효율성을 향상시키는 데 중점을 두고 있습니다.
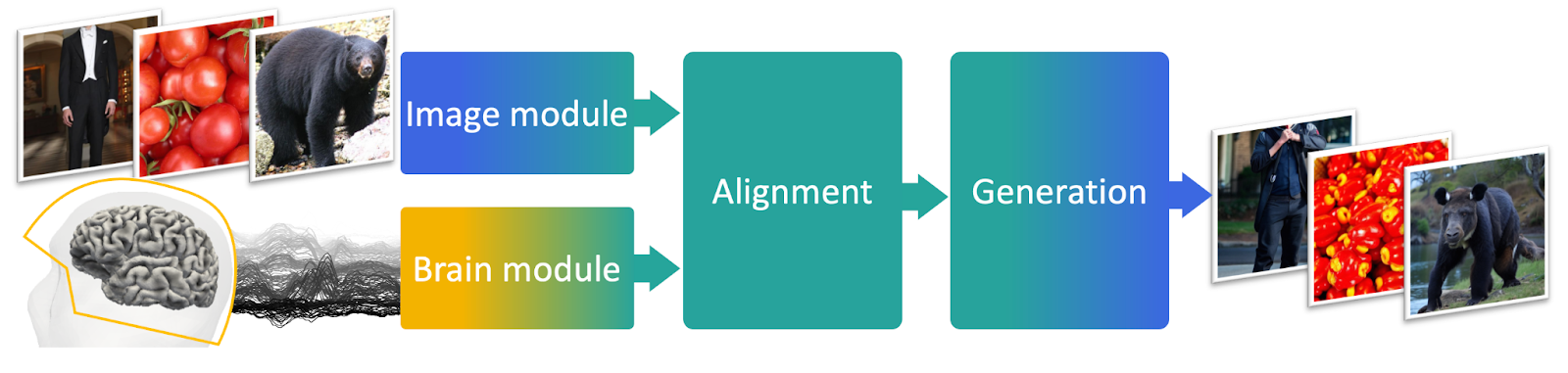
뇌 활동에서의 이미지의 실시간 해석 15
- Meta가 발표한 연구에서 MEG 기술을 활용하여 뇌 활동으로부터 이미지를 실시간으로 해독하는 AI 시스템을 소개합니다.
- 이 시스템은 뇌 활동을 통해 각 순간 뇌가 지각하는 이미지를 재구성하여 인간 지능의 기초를 이해하는 데 중요한 도구로 활용될 수 있습니다
Fuyu-8B: AI 에이전트를 위한 멀티모달 구조 16
- Adept.ai는 이미지와 텍스트를 모두 기본적으로 이해하도록 설계된 Fuyu-8B라는 이름으로 HuggingFace에서 사용할 수 있는 다중 모드 기반 모델을 출시했습니다.
- 기존 멀티모달 모델과 달리 Fuyu-8B는 별도의 이미지 인코더가 없는 단순한 아키텍처를 자랑하므로 임의의 이미지 해상도를 지원하고 빠른 응답 시간을 제공할 수 있습니다.
AI가 생성한 글에 대한 위험성 17
- 인공지능이 생산하는 책들이 야생 식물을 포함한 정보를 부정확하게 제공하여 위험한 정보를 전달한다는 우려가 있습니다.
- 이에 대한 대응책으로 책임 있는 자체 반성을 통해 인공지능이 정보를 검색하고 반영하는 새로운 프레임워크가 도입되었습니다.
📰 Papers
Lerf: Language embedded radiance fields 18
- CLIP과 같은 모델의 언어 임베딩을 NeRF로 전이하여 다양한 특성을 기반으로 3D 공간에서 자연어를 사용하여 위치를 정확히 기술할 수 있게 합니다.
- NeRF는 언어 필드를 학습하여 다양한 언어 쿼리에 대한 3D relevancy 맵을 추출할 수 있는 잠재력을 발휘합니다.
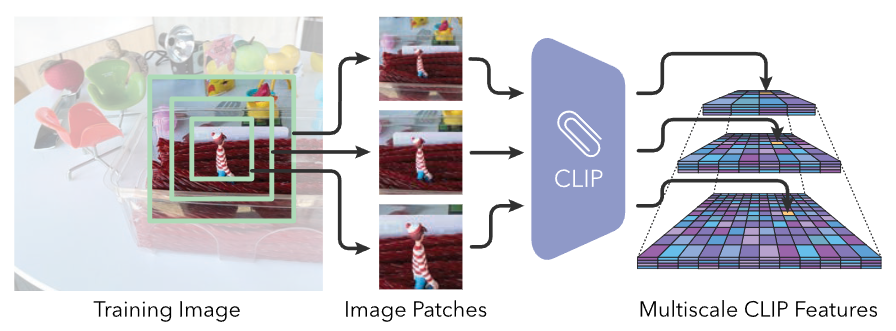 Multiscale CLIP Preprocessing
Multiscale CLIP Preprocessing
TADA: 텍스트로 애니메이션 생성 19
- TADA는 텍스트 설명을 기반으로 고품질 3D 아바타를 만들어내는 방법이며, 기존의 방식들 보다 Texture와 Geometry 품질이 뛰어납니다.
- 2D diffusion 모델 animatable parametric body 모델을 결합하여 사용하고, SDS를 통해 텍스트로부터 높은 품질의 3D 아바타를 생성합니다.
Doppelgangers: 유사 구조물 이미지의 차이를 인식 20
- 두 이미지 쌍이 동일한 3D 표면을 나타내는지를 결정하는 시각적 명확화 (Visual Disambiguation) 기법을 소개합니다.
- 비슷한 구조의 이미지 쌍을 포함하는 Doppelgangers 데이터셋을 소개하고, 로컬 키포인트의 공간 분포와 일치를 입력으로 받는 네트워크 아키텍처를 설계합니다.
WavJourney: 대규모 언어 모델을 활용한 작곡 21
- 텍스트로 오디오 스토리를 만드는 WavJourney는 LLM을 활용하여 구조화된 스크립트를 생성하고, 이를 컴퓨터 프로그램으로 변환/실행 하여 오디오를 생성합니다.
Gen-2: 생성적 AI를 위한 다음 단계 22
- Gen-2는 텍스트, 이미지 또는 비디오 클립을 활용하여 새로운 비디오를 생성할 수 있는 Multi-modal AI 시스템입니다.
더 많은 데이터, 더 큰 편향성 23
- 대용량 데이터셋을 사용하는 것이 모델의 Bias를 더 심화시킬 수 있다는 사실이 밝혀졌습니다.
- 크롤링한 이미지-텍스트 데이터셋을 분석하여 Bias와 악의적 콘텐츠의 비율을 확인했고, 큰 데이터셋이 작은 것보다 더 높은 편향성을 유발할 수 있다는 것을 밝혔습니다.
언어 모델링은 압축이다 24
- LLM은 뛰어난 예측 능력을 보여주기 때문에 강력한 Compressor가 될 수 있는데, 이 논문은 이러한 예측 문제를 압축의 관점에서 바라보고 대규모 모델의 압축 능력을 평가합니다.
- 결과적으로 대형 언어 모델은 강력한 일반 예측기로 작용하며, 압축 관점은 스케일링 법칙, 토큰화 및 문맥 학습에 대한 새로운 통찰을 제공합니다.
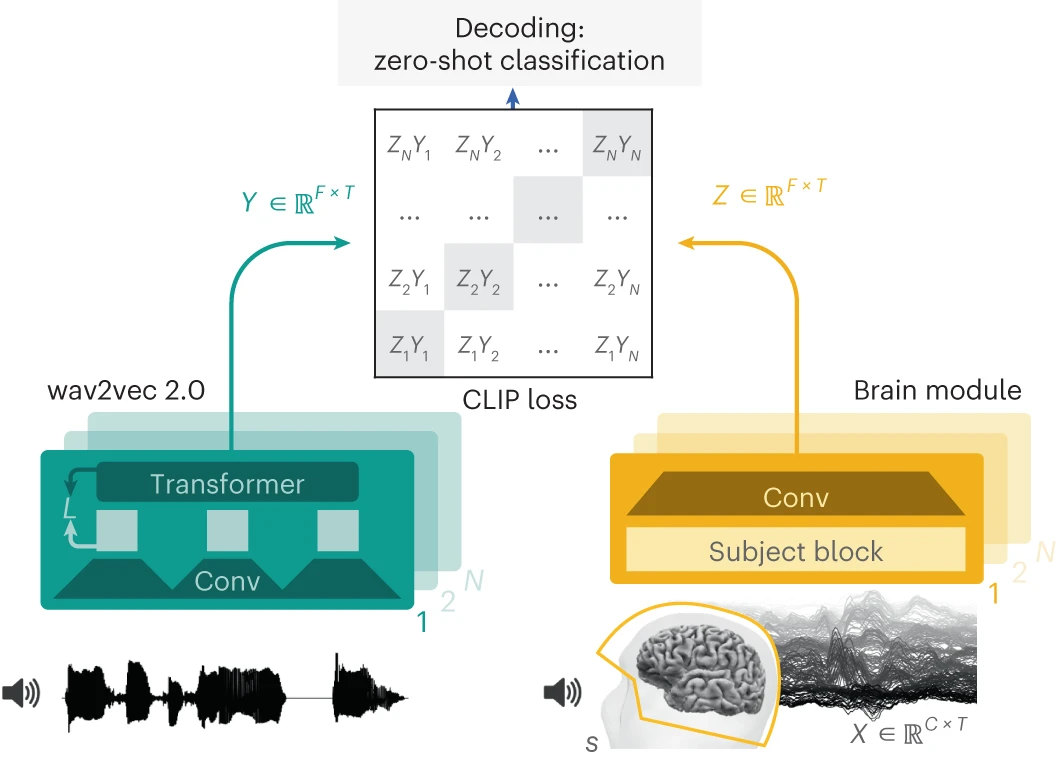
비침습적인 뇌 기록으로부터 언어 인식 해독하기 25
- 최근 심층 학습 알고리즘을 사용하여 뇌파에서 글자, 단어 및 오디오 *spectrogram과 같은 언어적 특징을 해독하는 연구가 진행되고 있습니다.
- 그러나 자연스러운 말 표현과 비침습적 (non-invasive)인 뇌 기록에 이 접근법을 활용하는 것은 여전히 힘듭니다.
- 이 연구에서는 비침습 뇌 기록에서 자기 지도 학습을 통해 예측된 언어의 표현을 해독하기 위한 모델을 소개합니다.
Self-RAG: Self-reflection을 통한 검색, 생성, 비평 학습 26
- SELF-RAG는 검색과 Self-reflection을 결합하여, 어떤 정보가 필요한지를 파악하고 그에 맞게 텍스트를 가져오는 새로운 프레임워크입니다.
- 공개 도메인 QA, 추론 및 사실성 개선을 포함한 사실 확인 작업에서 SoTA LLM(ChatGPT 및 검색 증강 Llama2-Chat)보다 훨씬 뛰어난 성능을 발휘합니다.
생성된 데이터로 훈련하면 모델이 잊어버리는 현상 27
- 각각 다른 모델이 생성한 데이터로 훈련된 기계 학습 모델의 정확도를 조사했습니다.
- 연속적으로 훈련된 모델은 희귀한 유형의 예제를 생성하는 데 어려움을 겪고 훈련 데이터의 분포와 일치하지 않는 결과물을 출력할 수 있다는 것을 보여주었습니다.
- 이는 Model Collapse 현상을 나타나며, 훈련 데이터의 오류를 쌓이게 합니다. 이에 따라 데이터 생성자는 새로운 정보에 접근해야 할 필요성이 있음이 제기되었습니다.
수술 중 초고속 딥러닝을 통한 중추신경계 종양 분류 28
- 신경망은 환자가 수술대에 있는 동안 종양을 제거할 때 뇌 외과 의사가 건강한 조직을 얼마나 잘라낼지 결정하는 데 도움을 줍니다.
- 신경망은 이러한 예비 DNA 서열을 빠르고 정확하게 분류할 수 있습니다.
대규모 언어 모델에서의 반복적인 부트스트래핑을 통한 사고 연쇄 프롬프트 개선 29
- 대규모 언어 모델이 어려운 문제에 대해 올바른 사고 사슬을 생성하도록 유도하는 방법인 Iterative bootstrapping in chain-of-thought-prompting를 제안합니다.
Llemma: 수학을 위한 오픈 언어 모델 30
- Proof-Pile-2 데이터셋에 대한 Code Llama의 지속적인 사전 학습을 기반으로 하는 수학용 LLM입니다.
- 데이터 세트에는 과학 논문, 수학이 포함된 웹 데이터 및 수학 코드가 포함됩니다.
장문형 질의응답을 위한 검색 보강 이해 31
- 긴 형식의 질문 응답에 대한 검색 증강 언어 모델입니다.
- 검색된 문서에 질문에 답하기 위한 정보/증거가 충분하지 않을 때 귀속 오류가 더 자주 발생한다는 사실을 발견했습니다.
AnomalyGPT: 대규모 비전-언어 모델을 활용한 산업 이상 탐지 32
- AnomalyGPT라는 새로운 IAD 접근 방식을 LVLM을 활용하여 제안하여 이상 이미지를 시뮬레이션하고 해당 이미지에 대한 텍스트 설명을 생성하여 학습 데이터를 생성합니다.
- 또한 이미지 디코더를 사용하여 세밀한 의미를 제공하고 LVLM을 prompt 임베딩을 이용해 미세 조정합니다.
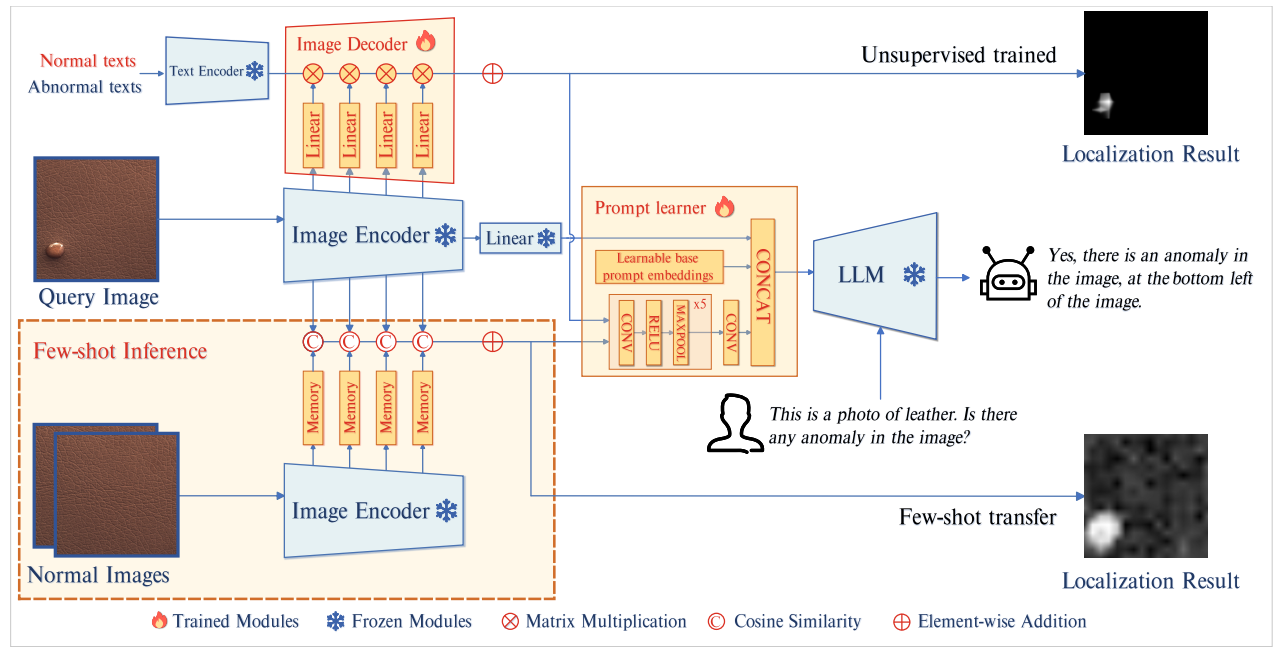 AnomalyGPT Architecture
AnomalyGPT Architecture
InstaFlow: 고품질 확산 기반 텍스트-이미지 생성에 필요한 한 단계 33
- Diffusion 모델은 multi-step sampling 과정으로 인해 느리다는 문제가 있습니다.
- Stable Diffusion를 초고속 one-step 모델로 변환하기 위해 텍스트 조건 파이프라인을 제안합니다.
Spectrogram 기반 LLM을 활용한 음성 질문 응답 및 연속 발화 34
- LLM에 사전 훈련된 음성 인코더를 부여함으로써, 모델은 음성 입력을 받아 음성 출력을 생성할 수 있게 됩니다.
- 전체 시스템은 end-to-end로 훈련되며 spectrogram에서 직접 작동하여 아키텍처를 단순화합니다.
InstaFlow: 고품질 확산 기반 텍스트에서 이미지 생성에 필요한 단 한 단계 35
- Rectified Flow의 핵심은 확률 흐름의 경로를 평탄화하는 ‘reflow’ 절차에 있으며, 잡음과 이미지 간의 결합을 개선하고, 학생 모델을 사용하여 distillation 프로세스를 용이하게 합니다.
- Diffusion을 텍스트에 의존하는 새로운 파이프라인으로 구성하여 SD를 초고속 단일 단계 모델로 변환하는 것을 제안합니다.
SAM-Med3D 36
- Segment Anything Model (SAM)은 2D 자연 이미지 분할에서 인상적인 성능을 보였지만, 3D 체적 의료 이미지에 적용하면 상당한 결함이 드러났습니다.
- 3D 의료 이미지를 위해 SAM을 수정한 모델인 SAM-Med3D를 제안합니다.
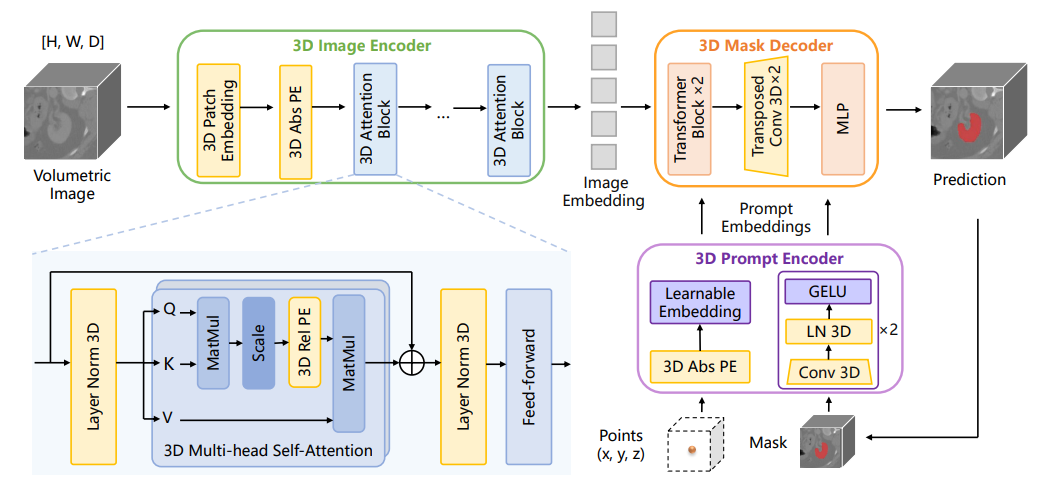 SAM-Med3D Architecture
SAM-Med3D Architecture
🧠 Deep Learning, Gen AI
Gen AI와 Transformer 37
- Generative AI가 무엇인지 설명하는 Financial Times의 스크롤 스토리입니다.
Multimodality와 LLM 38
- LLM의 등장을 소개하며 텍스트, 이미지 또는 오디오에 국한된 기존 ML 모델에서의 전환을 언급합니다.
- DeepMind의 최근 GPT4V 릴리스에 이어 LLM의 다중 양식 가능성에 대한 광범위한 사례를 다룹니다.
- 효율적인 교육 기술 + BLIP-2 및 LLaVA와 같은 새로운 시스템과 같은 LMM에서 진행 중인 연구 영역을 강조합니다.
파이토치로 Stable Diffusion 구현하기 39
- Stable Difussion을 Pytorch로 처음부터 구축하는 내용을 다루며 Repository 및 PDF 슬라이드도 제공합니다.
Transformer로 시계열 학습 40
- 기존의 Transformer를 변형한 inverted Transformer를 제안하여 시계열 데이터의 구조와 필요에 더 적합한 아키텍처로 성능을 향상시켰습니다.
- 새로운 아키텍처는 변수 간의 상관 관계를 더 잘 파악하고, 복잡한 수정 없이도 선형 모델보다 강력한 성과를 보여주며, 시계열 학습에 적합한 방향으로 변화를 이끌고 있습니다.
TimeGPT: 시계열 예측을 위한 최초의 기초 모델 41
- TimeGPT-1은 예측 분야에 적용되는 LLM의 기술 및 아키텍처로, 제로샷 추론이 가능한 최초의 시계열 기초 모델을 형성합니다.
- N-BEATS, N-HiTS 및 PatchTST에 대해 평가된 예측 프로젝트에 TimeGPT를 적용할 수 있는 방법을 소개합니다.
⚙️ MLOps
MLflow AI Gateway와 Llama2를 이용하여 Gen AI 어플 빌드하기 42
- MLflow AI Gateway는 확장성이 뛰어난 API Gateway 입니다.
- Llama2-70B-Chat 모델과 Instructor-XL 모델을 사용하여 Databricks Lakehouse AI 플랫폼에서 RAG 애플리케이션을 구축/배포하는 방법을 소개합니다.
머신러닝 컨테이너 구축 모범 사례 43
- 머신러닝 컨테이너를 구축하려면 성능 및 효율을 최적화하기 위해 다양한 요소를 고려해야합니다.
- “Base Image with Startup Scripts for Customization” 방식을 활용하여 효율적인 이미지를 생성합니다.
- Train, Validation 등 용도에 맞는 단일 컨테이너를 만들어 컨테이너의 크기와 복잡성을 줄입니다.
- 컨테이너의 라이브러리와 모델의 정확한 버전을 지정하고 Git을 이용하여 도커 파일을 관리합니다.
RAY를 이용한 최신 머신러닝 플랫폼 구축 44
- RayDP, Ray Tune 및 Ray Serve 등의 Ray 생태계를 활용하여 ML 플랫폼 구축에서 생기는 문제를 해결하는 방법을 정리합니다.
- 이는 확장/반복 가능한 머신러닝 개발 플로우를 지원하며 전체 머신러닝 운영 비용을 최소화 합니다.
OnnxStream 45
- OnnxStream은 저메모리 장치에서 대규모 Transformer 모델, 특히 Stable Diffusion 1.5 및 XL 1.0을 실행하도록 설계된 Inference 라이브러리입니다.
- OnnxStream은 메모리 소비 최소화에 중점을 두어 기존보다 최대 55배 적은 메모리로 작동할 수 있습니다.
2023 벡터 데이터베이스 선택 46
- 2023년 주요 벡터 데이터베이스를 포괄적으로 비교합니다.
- Milvus는 성능 및 커뮤니티 강점을 가지며, Pinecone은 개발자 경험 및 호스팅 솔루션에 유용합니다.
MLOps에서의 데이터 드리프트 모니터링과 그 중요성 47
- Data Drift를 관리하여 ML을 효율적으로 모니터링, 관리 하는 방법을 소개합니다.
Malloy 4.0 48
- Malloy는 데이터베이스를 쿼리하기 위해 SQL을 생성하는 새로운 분석 언어입니다.
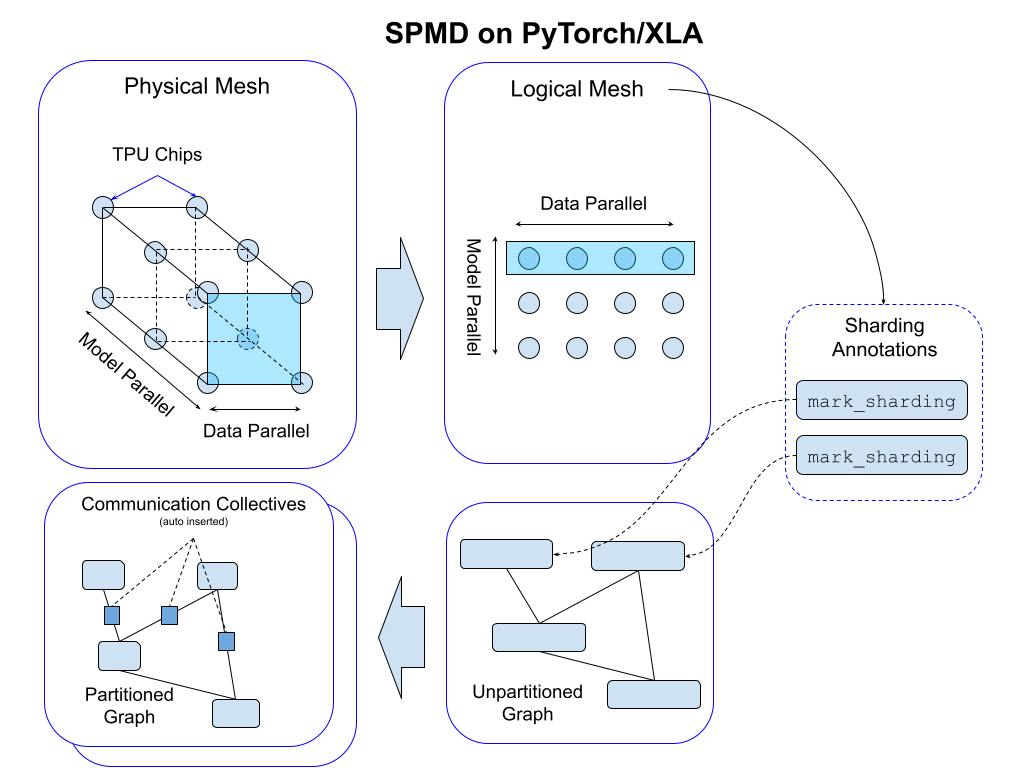
PyTorch/XLA SPMD: 자동 병렬화로 모델 훈련 및 서빙 확장하기 49
- PyTorch/XLA SPMD는 ML 워크로드를 위한 자동 병렬화 시스템인 GSPMD를 사용하기 쉬운 API를 통해 PyTorch에 통합한 것입니다.
BigQuery 데이터와 채팅 50
- 자연어를 사용하여 BigQuery 데이터에 액세스할 수 있는 예제입니다.
Verity로 데이터 품질 보장하기 51
- Verity를 소개하며 이것이 어떻게 우리의 Hive 데이터 웨어하우스에서 데이터 품질을 확보하는 중추적인 플랫폼으로 작용하는지 보여줄 것입니다
데이터베이스 파일 형식 최적화 52
- Mixpanel은 독점적인 열 기반 데이터베이스를 개발했으며, 압축을 개선하고 성능을 높이는 작업을 소개합니다.
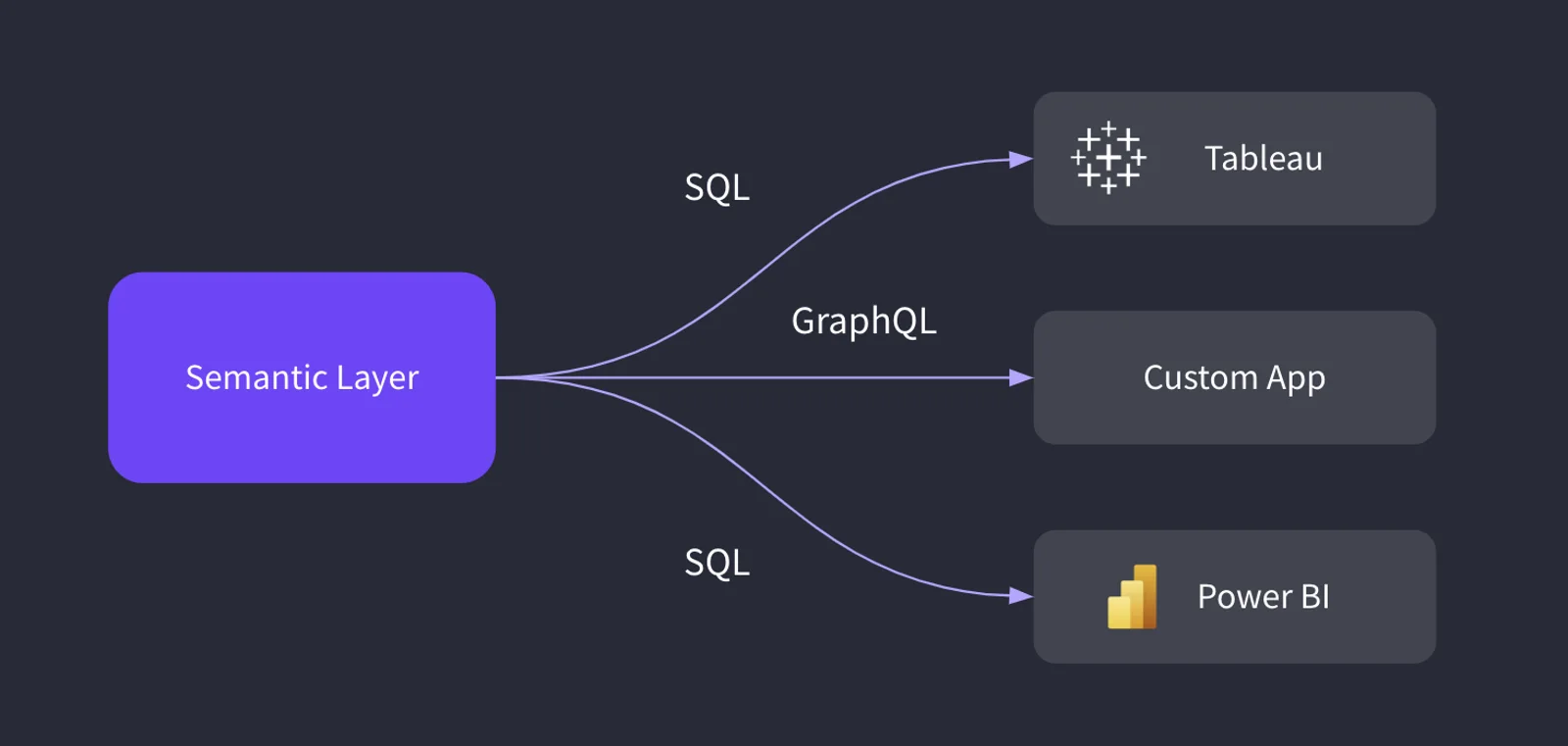
Semantic Layer를 위한 표준의 중요성 53
- Open Semantic Layer 표준이 비즈니스 인텔리전스 도구, 데이터 사이언스 노트북, 포함된 분석 시스템, 카탈로그 등과 Semantic Layer가 상호 작용하는 방법에 대한 일관성을 제공할 수 있다고 주장합니다.
- 이러한 표준화는 소프트웨어 공급업체에 부담을 덜어주고 전환 비용과 공급업체에 의한 잠금을 줄여 소비자들에게 이득을 주게 됩니다.
데이터 통합이 완전히 해결되지 않는 이유 54
- 몇 가지 데이터 데이터 통합도구를 다루고 이것이 단 하나의 클라우드 도구로 해결해야 하는 문제가 있는 까다로운 분야인 이유를 설명합니다.
- 데이터 통합 문제는 SaaS 벤더와 시스템 통합 업체 간의 경쟁적인 상업적 이해관계에 의해 주도되기 때문에 완전한 해결은 어려운 상태입니다.
Dockerfile을 Buildpack으로 대체하기 55
- Buildpack는 Docker 이미지를 생성하는 데 도움이 되는 강력한 도구로, Dockerfile을 작성할 필요없이 프로젝트를 손쉽게 Docker화 할 수 있습니다.
- Dockerfile 대비 간편한 사용성과 프로젝트의 언어 및 종속성 자동 감지를 제공하여 CI/CD 파이프라인에 원활하게 통합됩니다.
개발자가 알아야 할 GPU 컴퓨팅 지식 56
- GPU 컴퓨팅에 대한 기본적인 이해를 제공하며, CPU와 GPU의 설계 목표와 차이, GPU의 아키텍처와 메모리 구조, 그리고 CUDA 커널의 실행 모델에 대해 설명합니다.
References
How LinkedIn Is Using Embeddings to Up Its Match Game for Job Seekers ↩︎
Introducing New AI Experiences Across Our Family of Apps and Devices ↩︎
Details emerge on Jony Ive and OpenAI’s plan to build the ‘iPhone of artificial intelligence’ ↩︎
JPMorgan CEO Jamie Dimon says AI could bring a 3½-day workweek ↩︎
Confluent debuts managed Apache Flink service and generative AI features ↩︎
Is this a date? Using ML to identify date formats in file names ↩︎
How Microsoft is Trying to Lessen Its Addiction to OpenAI as AI Costs Soar ↩︎
Toward a real-time decoding of images from brain activity ↩︎
Doppelgangers: Learning to Disambiguate Images of Similar Structures ↩︎
WavJourney: Compositional Audio Creation with Large Language Models ↩︎
Decoding speech perception from non-invasive brain recordings ↩︎
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection ↩︎
The Curse of Recursion: Training on Generated Data Makes Models Forget ↩︎
Ultra-fast deep-learned CNS tumour classification during surgery ↩︎
Enhancing Chain-of-Thoughts Prompting with Iterative Bootstrapping in Large Language Models ↩︎
Understanding Retrieval Augmentation for Long-Form Question Answering ↩︎
AnomalyGPT:Detecting Industrial Anomalies using Large Vision-Language Models ↩︎
InstaFlow: One Step is Enough for High-Quality Diffusion-Based Text-to-Image Generation ↩︎
Spoken Question Answering and Speech Continuation Using Spectrogram-Powered LLM ↩︎
InstaFlow: One Step is Enough for High-Quality Diffusion-Based Text-to-Image Generation ↩︎
Tsinghua University: Inverting Transformers Significantly Improves Time Series Forecasting ↩︎
TimeGPT: The First Foundation Model for Time Series Forecasting ↩︎
Using MLflow AI Gateway and Llama 2 to Build Generative AI Apps ↩︎
Best Practices for Building Containers for Machine Learning ↩︎
Picking a vector database: a comparison and guide for 2023 ↩︎
PyTorch/XLA SPMD: Scale Up Model Training and Serving with Automatic Parallelization ↩︎
From Big Data to Better Data: Ensuring Data Quality with Verity ↩︎
Why data integration will never be fully solved, and what Fivetran, Airbyte, Singer, dlt and CloudQuery do about it ↩︎