2024년 AI 기술 트렌드 둘러보기 #1 | AI Trends
🤖 2024년 상반기 AI 기술 동향과 주요 뉴스, 논문, 글, 사례를 소개합니다.

KEYWORDS
인공지능 기술 트렌드, 2024 AI, Recent AI Trend, AI Issue, AI News, Top AI Paper
💡 News
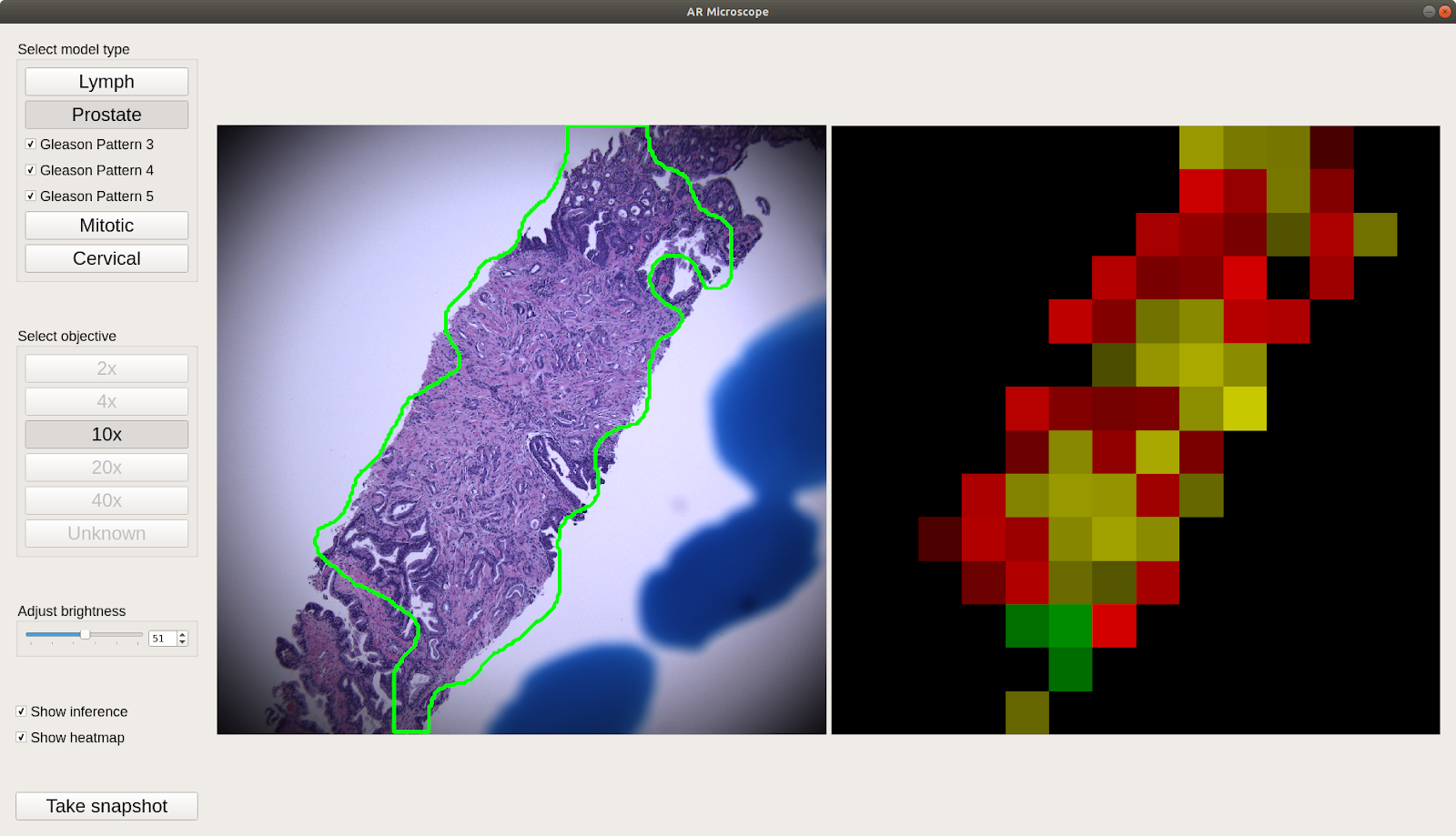
증강 현실 현미경을 통한 암 진단 1
- 미국 국방부가 증강 현실 현미경을 사용하여 병리 슬라이드를 통한 암(유방암, 자궁경부암, 전립선암)을 진단합니다.
- 이 현미경은 머신러닝 모델을 사용하여 암 조직을 감지하고, 감지된 종양의 경계를 표시하여 병리학자들의 진단을 돕습니다.
Meta’s Audio2Animation AI Model 2
- Meta는 Audio-to-3D-Animation AI 모델을 발표했으며, 오픈 소스 코드와 사전 학습된 모델을 제공했습니다.
- 이 연구는 오디오 입력을 통해 사실적인 3D 인간 아바타를 생성하는 프레임워크를 제안했으며, 이 모델은 벡터 양자화와 확산 프로세스를 활용해 기존 방법을 뛰어넘는 아바타 동작을 만들어냅니다.
Stanford on LLM Hallucination 3
- 이 논문은 WikiChat이라는 새로운 LLM을 소개하며, 위키피디아 데이터를 기반으로 잘못된 정보를 줄이는 데 초점을 맞추고 있습니다.
- LLM의 응답을 위키피디아 정보로 보완하여 97.3%의 정확도를 달성했으며, 최신 정보와 인기가 적은 주제에서도 우수한 성과를 보였습니다.
2024 CES에서의 AI 4
- 라스베이거스에서 열린 2024 소비자 전자제품 박람회(CES)에서 인공지능(AI)을 활용한 다양한 제품들이 등장했습니다.
- 휴대용 AI 개인 비서인 Rabbit R1, 대시보드 AI 보조 장치, AI 가속기 카드 등이 눈에 띄었으며, AI가 일상 생활에 더 많이 통합될 가능성을 보여주었습니다.
미국 AI 연구 자원 지원 5
- 미국 정부는 AI 연구를 지원하기 위한 국가 AI 연구 자원(NAIRR) 프로그램을 시작했습니다.
- Microsoft와 Nvidia와 같은 기업들이 이 프로그램에 자원을 기부하고 있으며, 이를 통해 더 많은 연구자들이 AI 연구에 접근할 수 있게 되었습니다.
농업에서의 AI 활용 6
- 인도의 Telangana주에서 소규모 농부들을 지원하는 Saagu Baagu 프로그램은 AI를 활용해 농작물 생산성을 향상시켰습니다.
- 농부들은 채팅봇을 통해 작물 상태에 맞춘 실시간 정보를 받고, 컴퓨터 비전 시스템을 사용해 작물 품질을 분석할 수 있습니다.
- 이 프로그램 덕분에 농부들은 작물 생산량을 21% 증가시키고, 판매 가격도 8% 올릴 수 있었습니다.
Vulkan Kompute가 LLama.cpp와 GPT4ALL의 백엔드로 채택됨 7
- Vulkan Kompute는 다양한 GPU에서 최적화된 AI 프레임워크를 지원하며, Meta의 최신 Code Llama 70B 모델 출시와 함께 주목받고 있습니다.
- Kompute는 AI 프레임워크에서 GPU 계산을 최적화하는 역할을 담당함.
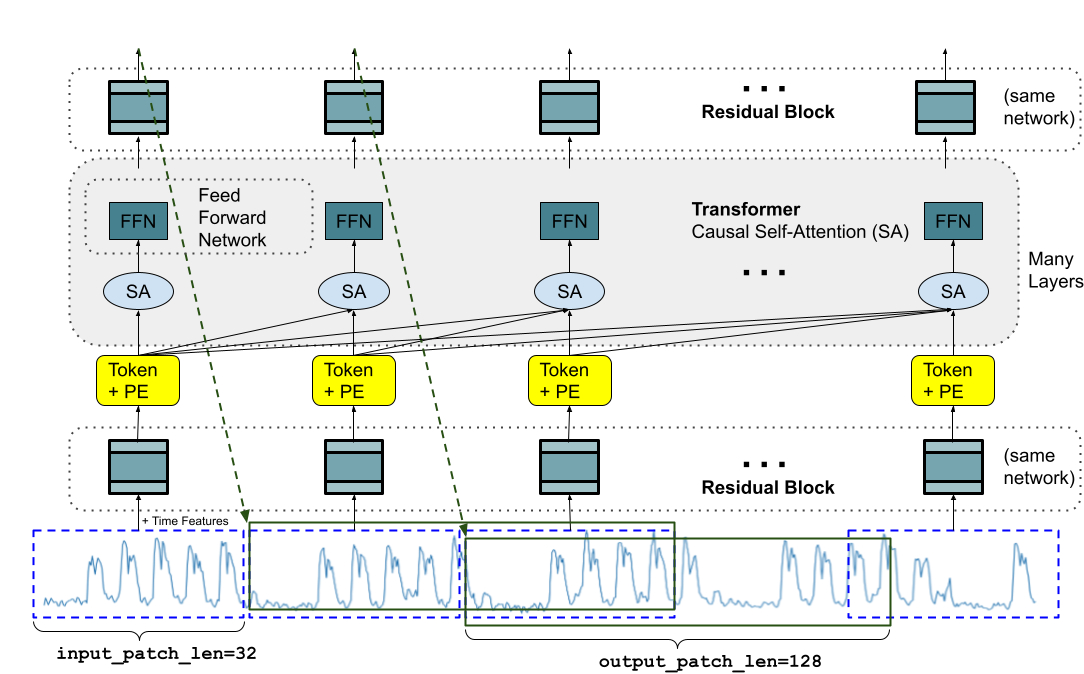
Google의 새로운 시계열 예측 모델 8
- Google은 “TimesFM”이라는 2억 매개변수를 가진 모델을 발표했습니다.
- 이 모델은 1000억 개의 실제 시계열 데이터를 기반으로 사전 학습되었으며, 추가 훈련 없이 예측을 수행하는 제로샷 기능을 제공합니다.
베수비오 화산 폭발로 손상된 두루마리 해독 9
- 인공지능 연구팀이 신경망을 사용하여 화산 폭발로 손상된 두루마리를 읽어내는 데 성공했습니다.
- 이 두루마리에는 에피쿠로스 철학과 관련된 내용이 포함된 것으로 해석되었으며, 이번 성과는 딥러닝 기술이 역사적 문제 해결에 기여할 수 있음을 시사합니다.
AI 기반 자동 음성 통화 제한 10
- 미국에서는 인공지능으로 생성된 음성을 사용하는 자동 전화가 금지되었습니다.
- 이는 선거에서 AI 생성 음성을 이용한 불법적 행위들에 의한 조치이며, 새로운 규제는 AI 음성을 포함한 통화에 대해 엄격한 동의와 식별 요구를 강화하고 있습니다.
비디오 생성 AI ‘Sora’ 공개 11
- OpenAI는 텍스트를 기반으로 한 비디오 생성 모델인 ‘Sora’를 공개했습니다.
- 이 모델은 1분 길이의 고해상도 비디오를 생성할 수 있으며, 현실적인 장면을 표현하는 데 뛰어난 성능을 보입니다.
아마존의 대규모 TTS 모델 발표 12
- 아마존은 100,000시간의 공공 도메인 음성 데이터를 학습한 10억 매개변수의 텍스트-음성 변환(TTS) 모델인 BASE TTS를 발표했습니다.
- 이 모델은 자동 회귀 트랜스포머를 사용하여 텍스트를 음성 코드로 변환하고, 이를 컨볼루션 기반 디코더가 음성으로 변환하는 방식입니다.
메타의 GenAI 인프라 13
- 메타는 하루에 수백 조 건의 AI 모델 데이터 추론을 처리하고 있으며, 두 개의 24,576-GPU 클러스터를 통해 AI 인프라를 한 단계 발전시키고 있습니다.
- Grand Teton, OpenRack, PyTorch 기반으로 한 메타의 AI 인프라 개선은 대규모 AI 작업을 처리하기 위한 최적화된 저장소와 성능 향상을 포함합니다.
- 메타는 2024년 말까지 350,000개의 NVIDIA H100 GPU를 도입할 계획을 세우고 있으며, 이는 기술 대기업 간 GPU 전쟁이 치열하다는 것을 보여줍니다.
Instability at Stability AI 14
- Stability AI의 CEO Emad Mostaque가 사임하면서 회사는 경영난에 직면했습니다.
- 현 경영진은 공동 CEO로 임명되어 회사를 운영하고 있으며, 재정 문제와 상장 절차가 지연되고 있습니다.
RAPTOR: Richer Context for RAG 15
- Stanford의 연구진은 텍스트 요약 기술을 활용하여 더 많은 관련 정보를 담은 RAG(retrieval augmented generation) 시스템인 RAPTOR를 개발했습니다.
- RAPTOR는 LLM의 최대 입력 길이에 따라 원문 또는 요약본을 제공하며, QASPER라는 데이터셋을 기반으로 한 테스트에서 RAPTOR는 다른 검색 시스템보다 더 뛰어난 성과를 보였습니다.
📰 Papers
StreamDiffusion: A Pipeline-level Solution for Real-time Interactive Generation 16
- 실시간 이미지 생성에 대한 스트리밍 프로세스를 병렬화하는 StreamDiffusion 파이프라인을 소개합니다.
Amphion: An Open-Source Audio, Music and Speech Generation Toolkit 17
- 오디오, 음악, 음성 생성을 위한 오픈소스 툴킷으로, 연구자들이 쉽게 연구를 시작할 수 있도록 지원합니다.
AnyText: Multilingual Visual Text Generation And Editing 18
- 여러 언어로 텍스트를 이미지에 정확하게 렌더링하는 AnyText 모델을 소개합니다.
FlexGen: High-Throughput Generative Inference of Large Language Models with a Single GPU 19
- 제한된 GPU 메모리로 LLM을 실행할 수 있는 고처리량 생성 엔진인 FlexGen을 소개합니다.
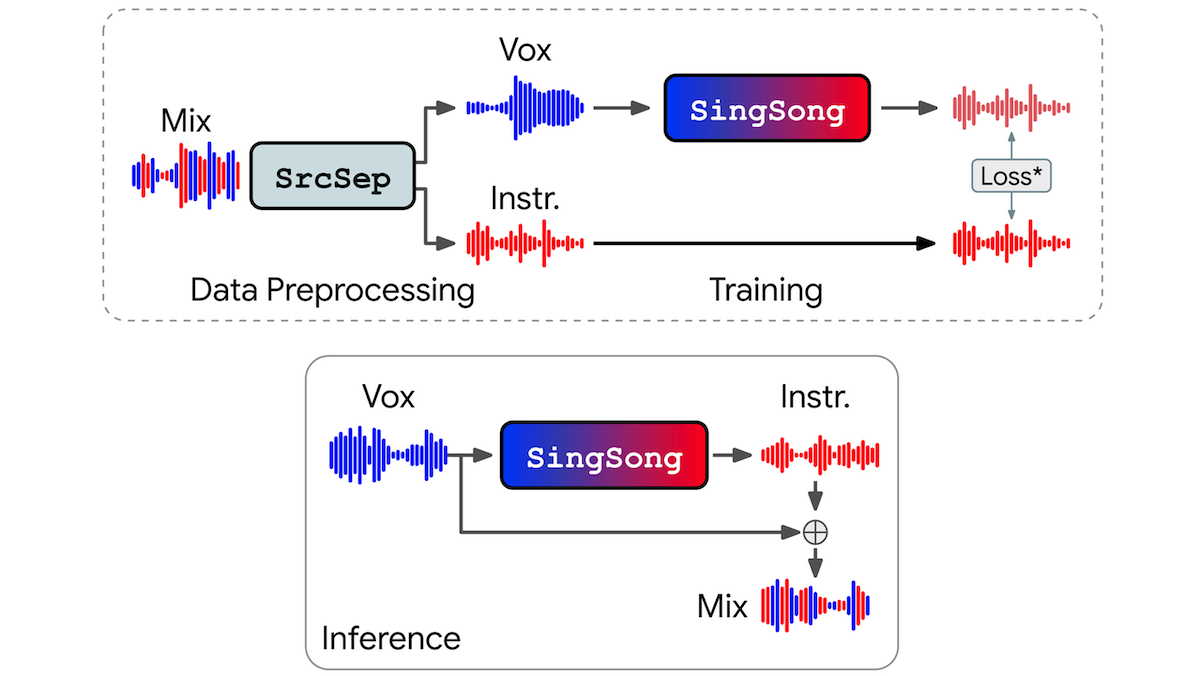
SingSong: 음성에 맞춘 자동 반주 생성 20
- 구글 연구진이 개발한 SingSong은 목소리에 맞춰 자동으로 악기 반주를 생성하는 AI 시스템입니다.
- 이 시스템은 노이즈를 추가하여 기존의 악기 잔향을 제거함으로써 목소리만으로 반주를 생성하는 데 성공했습니다.
A pancreatic cancer risk prediction model(Prism) developed and validated on large-scale US clinical data 21
- MIT 연구진이 췌장암 위험을 예측하는 모델을 개발했으며, 이 모델은 기존의 유전자 검사보다 더 높은 정확도를 보여주었습니다.
Solving olympiad geometry without human demonstrations 22
- 글과 뉴욕대학 연구진이 기하학 정리를 증명하는 AI 시스템을 개발했으며, 이는 수학 올림피아드 참가자들과 비슷한 수준의 성과를 보여주었습니다.
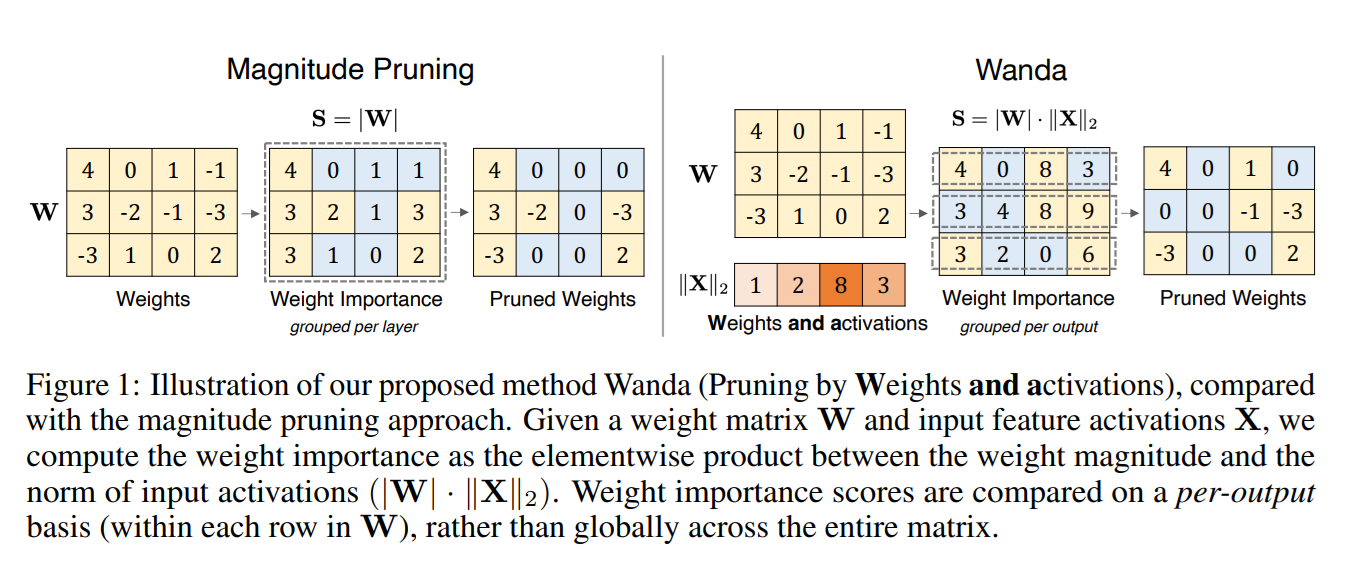
A Simple and Effective Pruning Approach for Large Language Models 23
- 카네기 멜론 대학교와 Meta AI 등의 연구팀이 신경망 가지치기의 새로운 방법인 Wanda를 개발했습니다.
- 이 방법은 중간층 출력 크기를 고려해 중요하지 않은 가중치를 효과적으로 제거하여 모델 크기를 절반으로 줄이면서도 성능 저하를 최소화합니다.
Adapted large language models can outperform medical experts in clinical text summarization 24
- Nature Medicine에 발표된 논문에서는 LLM, 특히 GPT-4가 임상 텍스트 요약 작업에서 인간 의료 전문가보다 유의미하게 더 우수한 성능을 보여준다는 것을 입증했습니다.
- GPT-4는 요약의 완전성, 정확성, 간결성 등 여러 지표에서 뛰어난 성능을 보였으며, Hallucination 오류 또한 인간 전문가보다 낮았습니다.
Accurate structure prediction of biomolecular interactions with AlphaFold 3 25
- AlphaFold 3는 분자의 구조와 상호작용을 정확하게 예측하는 새로운 최첨단 모델을 발표했습니다.
- 이 모델은 단백질, DNA, RNA 및 소분자의 3D 구조를 생성할 수 있으며, Evoformer 모듈을 개선한 버전입니다.
- 예측 결과는 확산 네트워크를 통해 조합되며, 확산 과정은 원자의 구름으로 시작되어 최종 분자 구조로 수렴합니다.
DrEureka: Language Model Guided Sim-To-Real Transfer 26
- DrEureka는 LLM을 사용하여 sim-to-real 디자인을 자동화하고 가속화하는 방법을 조사합니다.
- 이 연구는 목표 작업을 위한 물리적 시뮬레이션을 요구하며, 실제 세계 전이를 지원하기 위해 보상 함수와 도메인 무작위화 분포를 자동으로 구축합니다.
- 이 연구는 사족 보행 및 정교한 조작 작업에서 기존 인간 설계와 경쟁할 수 있는 sim-to-real 구성 요소를 발견했습니다.
Contextual Position Encoding: Learning to Count What’s Important 27
- CoPE는 맥락에 따라 위치 인코딩을 조정하는 새로운 방법으로, 특정 토큰에서만 위치를 증가시킵니다.
Attention as an RNN 28
- 새로운 Attention 메커니즘을 제시하여, 병렬로 훈련 가능하고 새로운 토큰 업데이트 시 메모리 사용량을 일정하게 유지합니다.
- 이 방식은 병렬 Pre-fix 스캔 알고리즘에 기반하여 효율적인 주의 계산을 가능하게 하며, 38개의 데이터셋에서 Transformer와 비슷한 성능을 보이면서 시간과 메모리 효율성이 더 높습니다.
Financial Statement Analysis with Large Language Models 29
- LLM이 트렌드 및 재무 비율 분석을 통해 유용한 통찰력을 생성할 수 있으며, GPT-4는 좁게 전문화된 모델과 동등한 성능을 보입니다.
- GPT의 예측을 기반으로 한 수익성 있는 거래 전략을 달성했습니다.
🧠 Deep Learning, LLM
Hallucination 탐지하기 30
- LLM이 사실이 아닌 정보를 말하지 않도록 ‘모름’이라고 답하게 훈련하는 새로운 접근법을 제시합니다.
LLM 추론을 위한 효율적인 Scaling 31
- 대규모 GPU 클러스터를 활용해 LLM 추론을 효율적으로 확장하는 방법을 다룹니다.
OLMo 32
- OLMo는 7B 파라미터를 가진 오픈 소스 언어 모델로, 훈련 코드, 데이터, 모델 가중치, 평가 및 미세 조정 코드를 모두 제공합니다.
- 이 모델은 다양한 생성 작업에서 우수한 성능을 보입니다. 또한 OLMo 1B라는 작은 버전도 함께 공개되었습니다.
SliceGPT 33
- SliceGPT는 훈련 후 희소화 기법을 사용하여 각 가중치 행렬을 작은 밀집 행렬로 대체하는 새로운 LLM 압축 기술을 제안합니다.
- Llama2-70B 및 Phi-2 모델에서 매개변수를 최대 20% 줄이면서도 제로샷 성능을 유지하면서, 모델 크기와 계산 비용을 줄일 수 있습니다.
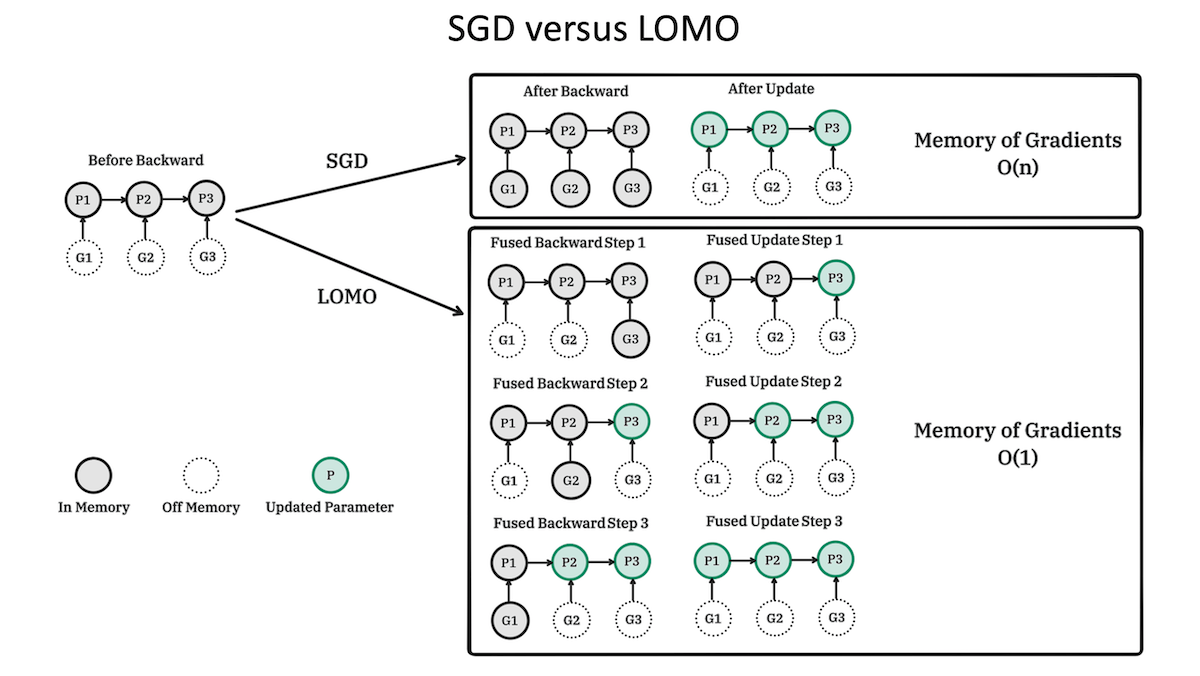
메모리 효율 최적화 기법 ‘LOMO’ 34
- 푸단 대학 연구진은 대형 언어 모델을 튜닝할 때 메모리 사용을 줄이는 새로운 최적화 기법인 ‘LOMO’를 개발했습니다.
- LOMO는 기존 최적화 기법보다 메모리 요구량이 적고 성능이 뛰어납니다.
Google DeepMind Gemini 1.5 35
- Google DeepMind는 Gemini 1.5를 발표하며, 100만 토큰을 처리할 수 있는 장기 문맥 이해력을 강조했습니다.
- 이 모델은 Mixture-of-Experts 아키텍처를 사용합니다.
LLMs의 효과적인 회귀 분석 36
- LLM은 선형 및 비선형 회귀를 효과적으로 수행할 수 있으며, 종종 랜덤 포레스트 및 그래디언트 부스팅과 같은 전통적인 방법보다 뛰어난 성능을 보입니다.
- LLM이 대규모 텍스트 코퍼스에서 훈련을 통해 복잡한 수치 추론 능력을 발전시키고, 맥락 내 예제를 처리하면서 회귀 능력을 조정하고 정제할 수 있음을 시사합니다.
Llama 3 37
- Llama 3는 80억 및 700억 개의 사전 훈련 및 지시 조정 모델을 포함하는 LLM으로, Llama 3 8B는 Gemma 7B 및 Mistral 7B Instruct보다 뛰어난 성능을 보입니다.
- Llama 3 70B는 Gemini Pro 1.5와 Claude 3 Sonnet보다 전반적으로 더 우수한 성능을 나타냅니다.
⚙️ MLOps & Data
머신러닝의 유닛 테스트에 대한 접근법 38
- 머신러닝에서는 논리가 정적이지 않고 데이터에서 학습하는 동적 시스템이기 때문에 전통적인 소프트웨어 테스트와 다릅니다.
- 작은 데이터 샘플로 테스트하거나 임의의 가중치를 사용하여 모델을 테스트하고, 외부 라이브러리를 피하면서 실제 모델을 대상으로 중요한 테스트를 수행하는 것이 좋은 방법으로 제시되었습니다.
디스코드의 대규모 데이터 처리 39
- 디스코드는 트릴리언 데이터포인트를 저장하고 관리하기 위해 MongoDB에서 Cassandra, 그리고 ScyllaDB로 전환했습니다.
- 이 과정에서 성능과 확장성 문제를 해결하며, 월드컵과 같은 대규모 트래픽 이벤트에서도 성공적으로 데이터를 관리한 사례를 통해 많은 학습과 최적화 방법을 공유했습니다.
70억 매개변수 모델을 집에서 훈련하기 40
- RTX 3090 또는 4090과 같은 두 개의 게임용 GPU만으로 대형 언어 모델을 훈련할 수 있는 오픈 소스 프레임워크가 등장했습니다.
- Fully Sharded Data Parallel, Quantization, QLoRA 같은 기법을 활용하여 소규모 연구실이나 개인도 대규모 AI 프로젝트를 저비용으로 실행할 수 있습니다.
머신러닝 공학 및 시스템 설계 41
- “Jupyter Beyond”는 머신러닝 맥락에서의 엔지니어링 및 시스템 설계에 대한 최선의 관행을 위한 교육 자료 모음입니다.
- 이 자료는 Jupyter 노트북 기반 프로젝트를 더 나은 유지보수 및 효율성을 위해 리팩토링하는 사례 연구를 포함하여, ML 분야에서 소프트웨어 설계 원칙에 대한 실제 예제를 제공합니다.
Stripe의 Feature Store와 Airbnb의 오픈소스 42
- Stripe는 Airbnb와 협력하여 Chronon OSS 프레임워크를 내부 ML 기능 플랫폼인 “Shepherd”에 적용했습니다.
- Stripe는 200개 이상의 새로운 기능을 통합하여 사기 탐지를 개선하고, 효율적인 데이터 처리를 위한 이중 키-값 저장 시스템을 활용한 내부 시스템의 주요 적응 사항도 설명합니다.
Ways to Deploy an ML Model 43
- Outerbounds 팀은 기계 학습 모델을 배포하는 다양한 방법을 소개하며, 배포 전략의 주요 고려 사항인 확장성, 신뢰성 및 반복 속도에 중점을 두며, 배치 처리 vs 실시간 처리, 재사용 가능 vs 전문화된 모델, 모달리티 등 애플리케이션 요구 사항에 따라 광범위한 기술적 요구 사항을 고려하는 것이 중요하다고 강조합니다.
GPUs Go Brrr 44
- GPU에서 AI 컴퓨팅을 최적화하기 위한 실용적인 전략과 복잡한 CUDA 커널 프로그래밍을 간소화하여 복잡한 ML 알고리즘을 다루는 방법을 소개합니다.
- 주요 모범 사례로는 공유 메모리에서 직접 비동기 행렬 곱셈 명령어를 활용하고, 지연 시간과 은행 충돌을 최소화하기 위해 공유 메모리의 특성을 관리하는 방법이 있습니다.
References
AI-Enabled Microscopes Demonstrate the Potential for More Timely and Accurate Cancer Detection ↩︎
A decoder-only foundation model for time-series forecasting ↩︎
Resurrect an ancient library from the ashes of a volcano. ↩︎
The FCC is proposing a ban on robocalls using AI-generated voices. ↩︎
BASE TTS: Lessons from building a billion-parameter text-to-speech model on 100K hours of data ↩︎
A Dataset of Information-Seeking Questions and Answers Anchored in Research Papers ↩︎
StreamDiffusion: A Pipeline-level Solution for Real-time Interactive Generation ↩︎
Amphion: An Open-Source Audio, Music and Speech Generation Toolkit ↩︎
FlexGen: High-Throughput Generative Inference of Large Language Models with a Single GPU ↩︎
A pancreatic cancer risk prediction model (Prism) developed and validated on large-scale US clinical data ↩︎
A Simple and Effective Pruning Approach for Large Language Models ↩︎
Adapted large language models can outperform medical experts in clinical text summarization ↩︎
Accurate structure prediction of biomolecular interactions with AlphaFold 3 ↩︎
Contextual Position Encoding: Learning to Count What’s Important ↩︎
Harmonizing multi-GPUs: Efficient scaling of LLM inference ↩︎
SliceGPT: Compress Large Language Models by Deleting Rows and Columns ↩︎
Full Parameter Fine-tuning for Large Language Models with Limited Resources ↩︎
From Words to Numbers: Your Large Language Model Is Secretly A Capable Regressor When Given In-Context Examples ↩︎
Introducing Meta Llama 3: The most capable openly available LLM to date ↩︎
Shepherd: How Stripe adapted Chronon to scale ML feature development ↩︎