CPU와 GPU의 병렬처리 | Parallel Processing
🖥️ CPU/GPU의 구조와 병렬처리 개념을 자세히 공부하고, 파이썬 멀티스레딩과 멀티프로세싱을 간단히 구현해봅니다.
CPU와 GPU의 병렬처리 | Parallel Processing
KEYWORDS
CPU, GPU, Parallel Processing, Parallel Computing, Multiprocessing, Multithreading, GIL, 파이썬 멀티프로세싱, 파이썬 멀티스레딩, 병렬 처리, SIMT
CPU란?
- CPU(중앙처리장치, Central Processing Unit)는 순차적인 명령어 실행을 최적화하도록 설계되었습니다.
- 명령어 실행의 지연(Latency)을 줄이기 위해 명령어 파이프라이닝(Pipelining), 비순차 실행(Out-of-order Execution), 투기적 실행(Speculative Execution), 다단계 캐시(Multilevel Cache) 기술을 가집니다.
- 복잡한 논리 연산과 순차적 작업을 빠르게 수행할 수 있습니다.
- CPU는 명령어 Latency을 줄이기 위해 캐시(Cache)와 제어 유닛(Control Unit)에 많은 칩 면적을 할당합니다.
- 그러나 연산 유닛(ALU, Arithmetic Logic Unit)의 수가 상대적으로 적기 때문에 많은 병렬 연산에는 적합하지 않습니다.
- CPU는 개별 연산을 빠르게 처리할 수 있지만, 대량의 연산을 동시에 수행하는 데에는 한계가 있습니다.
- ex. 연산 성능을 FLOPS로 측정하면, Intel의 24코어 CPU는 32비트 부동소수점 연산 기준으로 0.66 TFLOPS의 성능을 보여줍니다.
- FLOPS(Floating Point Operations per Second)는 1초당 수행할 수 있는 부동 소수점 연산 수를 의미합니다.
CPU와 병렬처리 CPU Parallel Processing
프로그램은 일반적으로 하나의 실행 흐름을 가지지만, 대규모 데이터 처리나 연산이 필요할 때 여러 작업을 동시에 처리할 필요가 있습니다.
- CPU는 적은 수의 강력한 코어를 가지고 있으며, 멀티스레딩과 멀티프로세싱을 활용하여 병렬 처리(Parallel Processing)를 수행할 수 있습니다.
- CPU의 병렬 처리는 GPU보다 더 복잡한 제어와 분기(Branching)에 유리합니다.
- 프로세스(Process) ㅣ OS에서 할당받은 자원 단위로, 독립적인 주소공간을 가지며 각 프로세스는 독립적인 스택(Stack)과 힙(Heap)을 사용합니다.
- 스레드(Thread) ㅣ 하나의 프로세스 내에서 실행되는 흐름 단위입니다.
- 스레드들은 동일한 주소공간을 공유하며 데이터를 빠르게 교환할 수 있다는 장점이 있지만, 동기화 문제가 발생할 수 있습니다.
Python GIL Global Interpreter Lock
- Python은 기본적으로 CPython이라는 구현체를 사용하여 실행되며, CPython은 Python 코드를 바이트코드로 변환하여 실행하는 방식을 뜻합니다.
- 이 바이트코드는 Python 인터프리터가 읽어 실행할 수 있는 중간 형태의 코드이며, Python의 대부분의 기능을 수행할 수 있습니다.
- CPython에서 멀티스레딩을 사용할 때 중요한 GIL(Global Interpreter Lock)은 한 번에 하나의 스레드만 Python 객체에 접근할 수 있도록 제한하는 Mutex입니다.
- 여러 스레드가 동시에 실행되더라도, 한 스레드만 Python 객체를 다룰 수 있게 하여 스레드 간의 충돌을 방지합니다.
- 동시에 실행되는 스레드가 Python 객체에 접근할 때 순차적으로 처리되게 합니다.
- CPython에서의 메모리 관리는 Thread-safe를 보장하지 않기 때문에 멀티스레드 환경에서 메모리 접근이 동시에 이루어지면 문제가 발생할 수 있습니다.
- 동시성 문제가 발생할 수 있고, 멀티스레딩이 성능을 개선하는 대신 오히려 오버헤드가 발생하는 경우가 많습니다.
- Python의 GIL은 각 스레드가 Python 객체에 접근할 때마다 GIL을 잠그고 해제하는 과정을 거칩니다.
- 여러 스레드가 동시에 실행되더라도 실제로는 단일 스레드처럼 동작하게 되는 것입니다.
- 병렬 처리가 아닌 동시 처리만 가능하게 되며, 멀티 스레딩 작업이 CPU 자원을 효율적으로 사용하기는 어렵습니다.
- 위 문제를 해결하기 위해 멀티프로세싱을 사용하여 프로세스 간에 독립적인 메모리 공간을 할당하고, 각 프로세스가 독립적으로 실행되게 하여 GIL의 영향을 받지 않게 할 수 있습니다.
- 서로 간에 메모리 공유가 없기 때문에 (독립 메모리 공간) 통신이 필요할 때는 파이프, 소켓 등을 사용해야 합니다.
- 이로 인해 멀티프로세싱은 통신 비용이 높고, Context Switching에도 오버헤드가 발생할 수 있습니다.
- 그럼에도 GIL의 제약을 피할 수 있기 때문에 병렬 연산이 필요한 작업에서는 여전히 유리합니다.
Python 멀티 스레딩 Multithreading
- CPU의 멀티스레딩 기능을 활용하여 데이터를 로딩하거나 GPU 메모리와의 통신을 최적화할 수 있습니다.
- 멀티 스레딩은 하나의 프로세스 내에서 여러 스레드가 작업을 수행하는 방식으로, 병렬 실행이 아니라 동시성(Concurrency)을 활용합니다.
- 여러 스레드가 하나의 프로세스 내에서 실행되지만, 실제로 병렬적으로 실행되는 것은 아닙니다.
- Python GIL의 영향을 받아 여러 스레드가 있더라도 한번에 하나의 스레드만 실행되므로, CPU 코어가 실제로 병렬 처리를 하진 않고 순차적으로 실행됩니다.
- 따라서 멀티 스레딩은 CPU-bound 작업에 효과적이지 않으며, I/O-bound 작업에서만 유용합니다.
threading.Thread를 사용하여 메인 스레드(Main Thread)에서 서브 스레드(Sub Thread)를 생성하고 실행할 수 있습니다.- 메인 스레드는 서브 스레드의 실행과 관계없이 독립적으로 진행되며, 서브 스레드가 실행되면 메인 스레드가 종료되더라도 서브 스레드는 계속 실행됩니다.
- ex.
threading.Thread클래스를 사용하여 새 스레드를 생성하고 실행해봅시다.start()호출 시, 메인 스레드와 별개로 서브 스레드가 실행됩니다.time.sleep(5)로 인해 서브 스레드는 5초 동안 대기하지만, 메인 스레드는 기다리지 않고 즉시 종료됩니다.
1
2
3
4
5
6
7
8
9
import logging
import threading
import time
# 서브 스레드 작업 함수
def worker_thread(thread_name):
logging.info("Thread %s: 시작", thread_name)
time.sleep(5)
logging.info("Thread %s: 종료", thread_name)
1
2
3
4
5
6
7
8
9
10
11
12
13
# 프로그램 실행 시작점
if __name__ == "__main__":
logging.basicConfig(format="%(asctime)s: %(message)s", level=logging.INFO, datefmt="%H:%M:%S")
# 새 스레드 생성
logging.info("스레드 생성")
thread1 = threading.Thread(target=worker_thread, args=('1번',))
# 서브 스레드 시작
logging.info("스레드 실행")
thread1.start()
logging.info("끝")
22:54:40: 스레드 생성 22:54:40: 스레드 실행 22:54:40: Thread 1번: 시작 22:54:40: 끝 22:54:43: Thread 1번: 종료
- ex.
join()을 사용하는 경우join()을 호출하면 메인 스레드는 서브 스레드가 종료될 때까지 기다립니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
if __name__ == "__main__":
logging.basicConfig(format="%(asctime)s: %(message)s", level=logging.INFO, datefmt="%H:%M:%S")
# 새 스레드 생성
logging.info("스레드 생성")
thread1 = threading.Thread(target=worker_thread, args=('1번',))
# 서브 스레드 시작
logging.info("스레드 실행")
thread1.start()
thread1.join()
logging.info("끝")
18:52:34: 스레드 생성 18:52:34: 스레드 실행 18:52:34: Thread 1번: 시작 18:52:37: Thread 1번: 종료 18:52:37: 끝
Python 멀티프로세싱 Multiprocessing
- Python의
multiprocessing모듈은 각 프로세스를 독립적으로 실행하고, 프로세스 간 메모리 공간을 공유하지 않기 때문에 GIL의 영향을 받지 않습니다.- 특히 Numpy, TensorFlow, PyTorch와 같은 라이브러리에서 GPU를 사용하는 병렬 연산에 잘 활용됩니다.
- 각 프로세스가 독립적인 메모리 공간을 사용하기 때문에 프로세스 간 데이터 공유가 어렵고, 프로세스 간 통신 비용이 높아질 수 있습니다.
- 병렬 컴퓨팅(Parallel Computing)과 직렬 컴퓨팅(Serial Computing)
- Python 스크립트를 실행하면 기본적으로 단일 프로세스로 동작하며, CPU의 단일 코어에서 코드가 실행됩니다.
- 하지만 대부분의 컴퓨터에는 다중 코어가 존재하므로, 병렬 처리를 활용하면 연산 속도를 향상시킬 수 있습니다.
- 직렬 컴퓨팅(Serial Computing) ㅣ 전체 작업을 순차적으로 실행하는 방식으로, 하나의 연산이 끝난 후 다음 연산을 수행합니다.
- 병렬 컴퓨팅(Parallel Computing) ㅣ 여러 개의 프로세스 또는 코어를 활용하여 동시에 연산을 수행하는 방식으로, 전체 작업을 여러 부분으로 나누어 동시에 처리합니다.
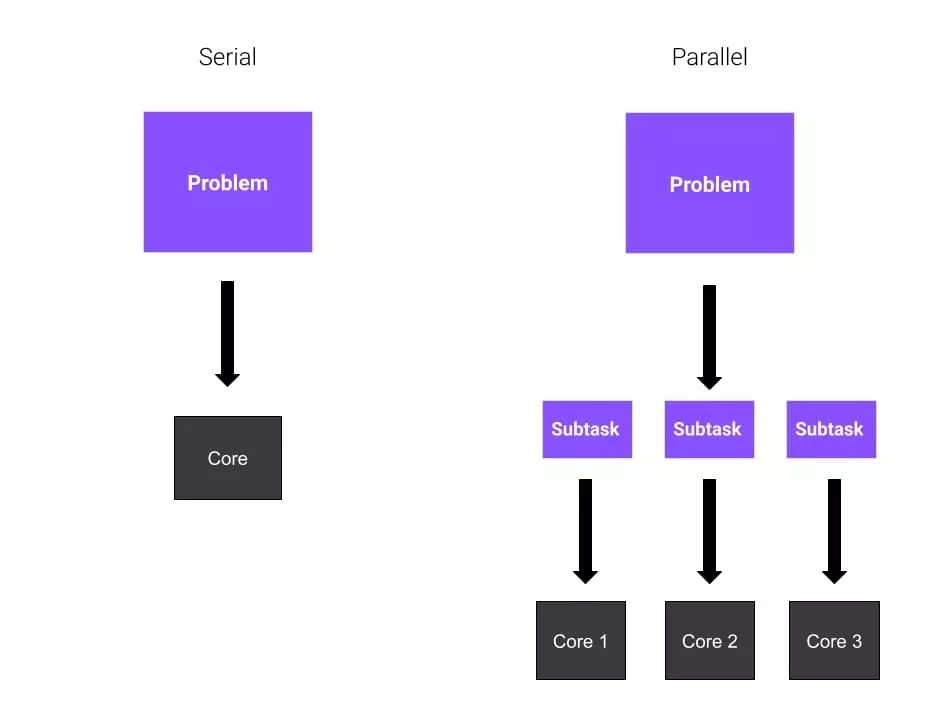 Serial and Parallel Computing 1
Serial and Parallel Computing 1
- 부모(Parent) 프로세스와 자식(Child) 프로세스
- 부모 프로세스(Parent Process) ㅣ 여러 개의 자식 프로세스를 생성할 수 있으며, 각 자식 프로세스는 독립적으로 실행됩니다.
- 자식 프로세스(Child Process) ㅣ 부모 프로세스에 의해 생성되며, 각각의 자식 프로세스는 추가로 다른 자식 프로세스를 생성할 수 있습니다.
- 장점
multiprocessing모듈은 각 프로세스를 독립적으로 실행하므로,threading모듈보다 CPU 연산이 많은 작업(CPU-bound)에서 성능이 우수합니다.threading모듈은 GIL로 인해 I/O-bound 작업에서 유리합니다.
- 하나의 프로세스에서 오류가 발생하더라도 다른 프로세스에 영향을 주지 않습니다.
- 프로세스 간 데이터를 공유하기 어렵지만,
multiprocessing.Queue나multiprocessing.Manager를 사용하여 데이터를 주고받을 수 있습니다. - 코드 구현이 간단합니다.
- ex.
multiprocessing.Process클래스를 사용하여 새 프로세스를 생성하고 실행해봅시다.start()를 호출하면 새 프로세스가 실행되며, 해당 프로세스는worker_process()함수를 실행하며 5초동안sleep()을 한 후 종료됩니다.join()을 호출하면 메인 프로세스는 해당 프로세스가 종료될 때 까지 대기하며,join()이 호출된 후에는 프로세스가 종료되었으므로False가 반환됩니다.
1
2
3
4
5
6
7
8
9
import logging
from multiprocessing import Process
import time
# 서브 프로세스 작업 함수
def worker_process(process_name):
logging.info("Process %s: 시작", process_name)
time.sleep(5)
logging.info("Process %s: 종료", process_name)
1
2
3
4
5
6
7
8
9
10
11
12
# 프로그램 실행 시작점
if __name__ == "__main__":
logging.basicConfig(format="%(asctime)s: %(message)s", level=logging.INFO, datefmt="%H:%M:%S")
logging.info("프로세스 생성")
proc = Process(target=worker_process, args=("1번", ))
logging.info("프로세스 실행")
proc.start()
proc.join()
logging.info(f"끝: {proc.is_alive()}")
08:44:52: 프로세스 생성 08:44:52: 프로세스 실행 08:44:52: Process 1번: 시작 08:44:52: Process 1번: 종료 08:44:52: 끝: False
GPU란?
- GPU(그래픽처리장치, Graphic Processing Unit)는 많은 병렬 연산과 높은 처리량(Throughput)을 목표로 설계되었습니다.
- 이미지 처리, 수치 계산, 딥러닝과 같은 분야에서는 선형대수 연산이 많이 필요하기 때문에, GPU는 다수의 연산을 동시에 수행하는데 최적화되어 있습니다.
- GPU는 많은 명령어 Latency을 감수하는 대신, 대량의 연산 유닛(ALU)을 포함하여 병렬 처리를 극대화합니다.
- GPU가 보유한 대량의 스레드(Thread)와 강력한 연산 성능 덕분이며, GPU는 실행 가능한 스레드를 효율적으로 스케줄링(Scheduling)합니다.
- 일부 스레드가 특정 명령어의 실행 결과를 기다리는 동안, GPU는 대기하지 않는 다른 스레드를 즉시 실행합니다.
- CPU와 달리 캐시와 제어 유닛에는 적은 칩 면적을 할당하여, 동일한 시간 내에 더 많은 연산을 수행할 수 있도록 설계되었습니다.
- ex. Nvidia의 Ampere A100 GPU는 32비트 정밀도 기준으로 19.5 TFLOPS의 성능을 보여줍니다.
- CPU보다 압도적으로 높은 성능이며, CPU와 GPU간의 성능 차이는 점점 멀어지고 있습니다.
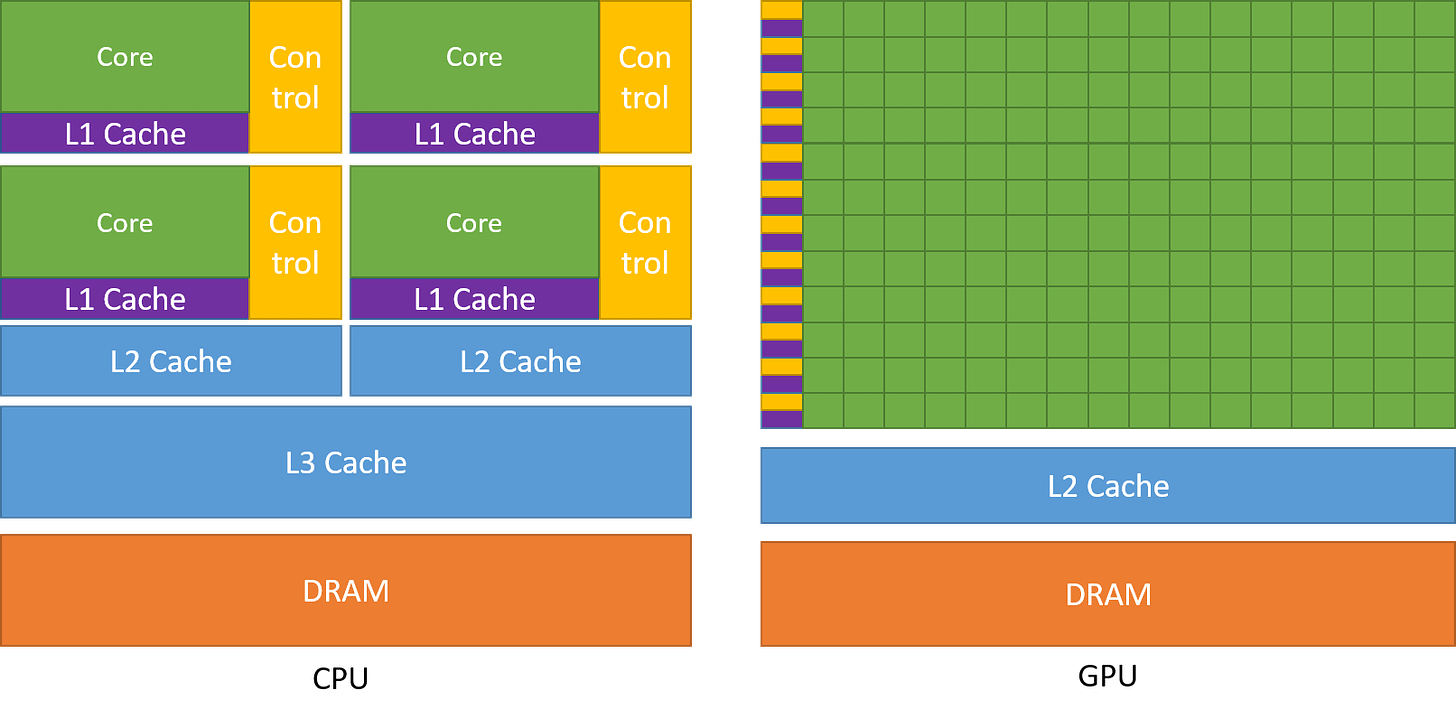 A comparison of the CPU and GPU chip design. Figure from the Nvidia CUDA C++ Programming Guide 2
A comparison of the CPU and GPU chip design. Figure from the Nvidia CUDA C++ Programming Guide 2
GPU Architecture
Computing
- GPU는 스트리밍 멀티프로세서(SM, Streaming Multiprocessor) 배열로 구성되며, 각 SM은 여러 개의 스트리밍 프로세서(코어/스레드)로 이루어집니다.
- ex. Nvidia H100 GPU는 132개의 SM을 포함하며, 총 8448 (\(132 \times 64\))개의 코어를 가집니다. (SM당 64개 코어)
- 각 SM에는 온칩 메모리(On-chip Memory)가 있으며, 이는 공유 메모리(Shared Memory) 또는 스크래치패드(Scratchpad)라고 부르기도 합니다.
- SM 내의 모든 코어가 공유되면서, 제어 유닛 자원에서도 코어들이 공통으로 사용됩니다.
- 각 SM에는 하드웨어 기반의 스레드 스케줄러가 있어 스레드를 효과적으로 실행할 수 있게 해줍니다.
- SM에는 특정 연산을 가속하는 기능 유닛(Functional Unit)이 있습니다.
- 가속 연산 유닛 ㅣ 텐서 코어(Tensor Core), 레이 트레이싱(Ray Tracing)
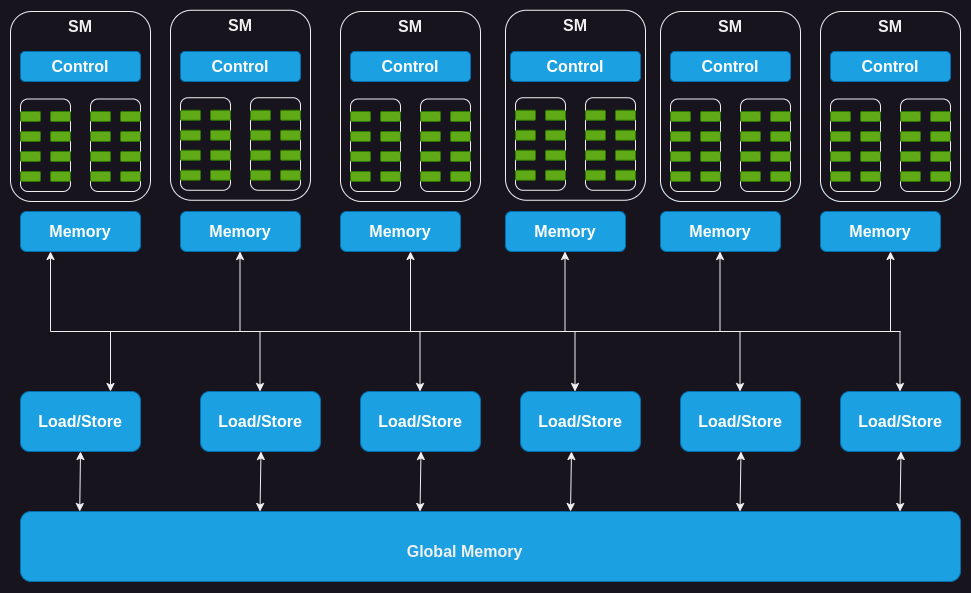 The GPU Compute Architecture 2
The GPU Compute Architecture 2
Memory
- GPU에는 각각 특정한 역할을 가진 여러 계층의 메모리가 존재합니다.
- 레지스터(Register)
- GPU의 각 SM에는 많은 레지스터가 있으며, 이는 코어 간에 공유되며 스레드 요구 사항에 따라 동적으로 할당됩니다.
- ex. Nvidia A100 및 H100 모델에는 SM당 65,536개의 레지스터
- 특정 스레드가 할당받은 레지스터는 다른 스레드가 읽거나 쓸 수 없습니다.
- GPU의 각 SM에는 많은 레지스터가 있으며, 이는 코어 간에 공유되며 스레드 요구 사항에 따라 동적으로 할당됩니다.
- 상수 캐시(Constant Cache)
- GPU 칩에 상수 캐시가 포함되며, 이는 SM에서 실행되는 코드가 사용하는 상수 데이터를 저장(캐시)하는 역할을 합니다.
- 개발자가 코드에서 객체를 명시적으로 상수로 선언하면, GPU가 이를 상수 캐시에 저장합니다.
- 공유 메모리(Shared Memory)
- 각 SM에는 공유 메모리라고 하는 Programmable On-chip SRAM이 포함되어 있으며, SM에서 실행되는 스레드 블록 내의 모든 스레드가 공유할 수 있도록 설계되었습니다.
- 커널(kernel) 실행 성능을 향상시키기 위해, 한 스레드만 글로벌 메모리(Global Memory)에서 데이터를 로드하고 나머지 스레드가 이를 공유하도록 하는 것이 목적입니다.
- 글로벌 메모리(Global Memory) ㅣ 오프칩(Off-chip) 글로벌 메모리로 고용량, 고대역폭 DRAM을 사용합니다.
- SM에서 멀리 떨어져 있어 Latency가 높지만, 여러 계층의 온칩 메모리와 많은 연산 유닛으로 해결합니다.
- 공유 메모리는 블록 내 스레드 간의 동기화(Synchronization)에도 사용될 수 있습니다.
- L1 & L2 캐시
- L1 캐시 ㅣ 각 SM마다 존재하며, 자주 접근하는 데이터를 L2 캐시에서 가져와 저장하는 역할을 합니다.
- L2 캐시 ㅣ 모든 SM이 공유하는 캐시로, 글로벌 메모리에서 자주 사용되는 데이터를 저장하여 메모리 Latency를 줄입니다
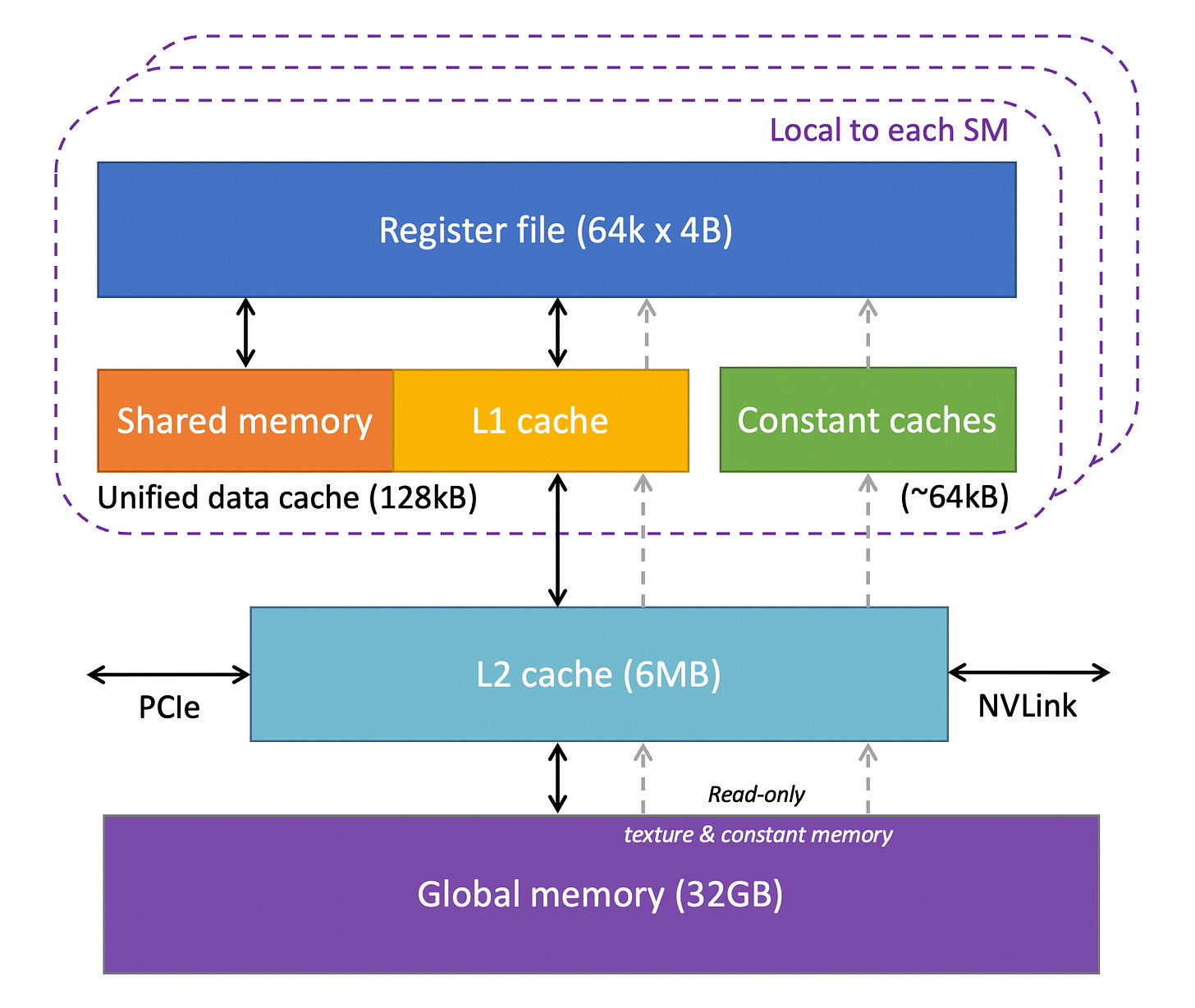 The GPU Memory Architecture from the Cornell Virtual Workshop on Understanding GPUs 2
The GPU Memory Architecture from the Cornell Virtual Workshop on Understanding GPUs 2
GPU 커널(Kernel) 실행하기
- 커널(kernel) ㅣ GPU에서 실행되는 함수
- CUDA3는 Nvidia에서 제공하는 GPU 프로그래밍 인터페이스로, C/C++ 함수와 유사한 형태로 GPU에서 실행할 코드를 작성할 수 있습니다.
- 커널은 함수의 입력으로 제공된 숫자 벡터에 대해 병렬 연산을 수행합니다. 이 커널은 두 개의 입력 벡터를 받아 각 요소를 더한 후 결과를 새로운 벡터에 저장합니다.
커널을 GPU에서 실행하려면 그리드(Grid)라고 하는 여러 개의 스레드(스레드 블록)를 실행해야 합니다.
- CUDA 커널을 작성하려면 두 개의 코드가 필요합니다.
- 호스트 코드(Host Code) ㅣ CPU에서 실행되는 코드입니다.
- 데이터를 불러오고 GPU 메모리를 할당하며, 커널을 적절한 스레드 구성으로 실행합니다.
- 디바이스 코드(Device Code) ㅣ GPU에서 실행되는 코드입니다.
- 실제 커널 함수가 정의되는 부분입니다.
- 호스트 코드(Host Code) ㅣ CPU에서 실행되는 코드입니다.
- CUDA 커널 실행 과정
- 호스트에서 디바이스로 데이터 복사하기
- 커널이 실행되기 전에, 커널이 필요로 하는 모든 데이터를 호스트(CPU)의 메모리에서 디바이스(GPU)의 글로벌 메모리로 복사해야 합니다.
- SM에 스레드 블록 할당하기
- GPU가 모든 필요한 데이터를 확보한 후, 스레드 블록을 SM에 할당합니다.
- 각 블록의 모든 스레드는 동일한 SM에서 동시에 실행되며, GPU는 실행 전에 해당 SM에 필요한 자원을 할당해야 합니다.
- SM의 개수는 제한적이며, 대규모 커널은 매우 많은 블록을 가질 수도 있기에, 일부 블록은 즉시 할당되지 못하고 대기 리스트에 등록됩니다 (이후에 순차적으로 할당).
- 단일 명령어 다중 스레드(SIMT)와 워프(Warp)
- 스레드 블록이 SM에 할당된 후, 내부 스레드는 추가적으로 그룹을 형성합니다.
- GPU에서는 32개의 스레드가 하나의 워프를 이루며, 프로세싱 블록(Processing Block)이라 불리는 연산 유닛에서 함께 실행됩니다.
- SM은 워프 단위로 명령어를 가져와 실행하며, 각 스레드는 동일한 명령을 수행하지만 서로 다른 데이터에 대해 연산을 수행합니다.
- 이러한 실행 모델을 단일 명령어 다중 스레드(Single Instruction Multiple Threads, SIMT) 라고 합니다.
- 워프 스케줄링
- SM의 실행 유닛(Execution Unit) 수가 제한되어있어, 한 번에 실행 중인 워프는 일부에 불과합니다.
- 실행하는 데 오래 걸리는 명령어의 경우, 해당 워프는 그 결과를 기다려야 하므로 대기 상태가 됩니다.
- GPU는 이러한 워프를 Sleep 상태로 전환 한 후, 대기 중인 다른 워프를 실행하여 최대 연산 자원을 활용 합니다.
- 디바이스에서 호스트로 결과 복사하기
- 모든 커널 실행이 완료되면, 마지막 단계로 연산 결과를 디바이스(GPU) 메모리에서 호스트(CPU) 메모리로 복사 합니다.
- 이 과정을 통해 CPU는 GPU에서 수행한 연산 결과를 활용할 수 있습니다.
GPU와 병렬처리 GPU Parallel Processing
- GPU는 SIMT 방식으로 동작하며, 하나의 명령어를 여러 데이터에 동시에 적용하는 방식입니다.
- CUDA, OpenCL, CuPy, Numba, PyTorch, TensorFlow 등의 라이브러리를 사용하여 구현할 수 있습니다.
- ex. Numba를 활용하여 GPU에서 행렬 덧셈을 구현하겠습니다.
@cuda.jit데코레이터를 사용하여 GPU에서 실행할 CUDA 커널 함수를 정의합니다.cuda.grid(1)을 사용하여 각 GPU 스레드의 글로벌 인덱스를 가져옵니다.threads_per_blockㅣ CUDA에서는 연산을 블록 단위로 실행하며, 각 블록은 여러 개의 스레드로 이루어집니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
from numba import cuda
import numpy as np
@cuda.jit
def add_vectors(a, b, result):
idx = cuda.grid(1)
if idx < a.size:
result[idx] = a[idx] + b[idx]
N = 1000000
a = np.ones(N, dtype=np.float32)
b = np.ones(N, dtype=np.float32)
result = np.zeros(N, dtype=np.float32)
# GPU에서 실행
threads_per_block = 256
blocks_per_grid = (N + threads_per_block - 1) // threads_per_block # 3906.25
add_vectors[blocks_per_grid, threads_per_block](a, b, result)
- ex. Pytorch를 활용하여 CPU보다 빠르게 대량의 행렬을 연산할 수 있습니다.
1
2
3
4
5
6
7
8
import torch
# GPU로 텐서 이동
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
a = torch.randn(1000, 1000, device=device)
b = torch.randn(1000, 1000, device=device)
c = torch.mm(a, b) # GPU에서 행렬 곱 연산 수행
Summary
- 멀티 스레딩은 하나의 프로세스 내에서 여러 스레드가 작업을 수행하는 방식으로, 동시성(Concurrency)을 활용합니다.
- Python의 멀티 스레딩은 GIL의 영향을 받아 한 번에 하나의 스레드만 실행되게합니다.
- CPU 코어가 순차적으로 실행되기 때문에 CPU-bound 작업에는 유용하지 않습니다. (병렬 실행 X)
- 멀티 프로세싱은 여러 개의 독립적인 프로세스나 코어에서 작업을 실제로 동시에 실행하는 것을 의미하며, 병렬 컴퓨팅(Parallel Computing)에 해당합니다.
- 멀티 프로세싱은 프로세스마다 별도의 Python 인터프리터를 실행하므로 GIL의 영향을 받지 않습니다.
- GPU는 다수의 SM과 코어로 구성되어 병렬 연산을 수행할 수 있으며, 온칩 메모리와 공유 메모리를 활용하여 연산 속도를 최적화합니다.
- CUDA를 이용하면 CPU에서 GPU로 데이터를 복사한 후, 커널을 실행하고 연산 결과를 다시 CPU로 반환할 수 있습니다.
- GPU 병렬 처리는 블록과 스레드 구성을 통해 GPU를 최대한 활용하여 연산 속도를 높일 수 있는 방법입니다.
References
This post is licensed under CC BY 4.0 by the author.