LLM의 역사 | A History of Large Language Models
📚 현재의 LLM을 만든 연구들을 순서대로 소개합니다.
KEYWORDS
LLM, LLM 역사, LLM이란, LLM 인공지능 뜻, 대규모 언어 모델, Language Model, 분산 표현, Word Embedding, Word2Vec, Attention, Transformer, Attention is all you need, RLHF, Bengio 2003, 어텐션이란, 트랜스포머 논문리뷰
Introduction
- 대규모 언어 모델(Large Language Model, LLM)은 어느 날 갑자기 등장한 기술이 아니라, 1980년대 분산 표현 연구부터 이어진 40여 년의 연구 결과물입니다 1.
- LLM을 이해하려면 오늘날의 GPT, Claude가 무엇을 하는가가 아니라, 어떤 아이디어들이 순차적으로 연결되어 지금의 모델을 만들었는가를 이해하는 것이 좋습니다.
본 글은 LLM을 구성하는 핵심 아이디어들의 흐름을 시간순으로 정리했습니다.
분산 표현(Distributed Representation) ㅣ Bengio 2003
- 자기회귀 프레임워크(Autoregressive Framework)
- Word2Vec과 언어 규칙성(Linguistic Regularities)
- Seq2Seq 모델과 적응적 문맥(Adaptive Context)
- Attention 메커니즘의 분화
- Transformer (Attention is all you need, 2017)
- 생성적 사전학습(Generative Pre-training)과 정렬(Alignment, RLHF)
분산 표현 Distributed Representation
- 핵심 질문 ㅣ 사람의 언어를 어떻게 컴퓨터로 모델링할 것인가?
- 1980년대까지 자연어 처리(Natural Language Processing, NLP)는 수작업으로 설계된 규칙과 특성(Feature) 기반이었습니다.
- 1990년대 초부터 통계적 기계학습 방법이 도입되기 시작했습니다 2.
- 통계적 NLP의 핵심은 언어를 가능한 모든 시퀀스에 대한 확률 분포로 모델링하는 것입니다.
- 이 분포는 보통 각 단어가 앞선 모든 단어에 의존하도록 분해됩니다:
- 좋은 언어 모델 \(p(w_{1:T})\)가 있으면 시퀀스의 가능도 비교, 번역, 조건부 생성 등 다양한 작업이 가능합니다.
차원의 저주 Curse of Dimensionality
- 위 확률을 추정하는 일은 매우 어렵습니다.
- 영어 어휘는 대략 백만 단어 수준이며, 번역처럼 조건부 확률이 많은 작업에서는 모든 조합을 관측할 수 없습니다.
- 데이터 희소성(Data Sparsity) 문제로, 실제 확률을 추정하는 것이 사실상 불가능해집니다.
- 가장 오래된 접근은 Markov 가정으로, 이는 각 조건부 확률이 직전 \(N\)개 단어에만 의존한다고 단순화하는 방식입니다 3:
- 이것이 유명한 N-gram 모델입니다.
- \(N=2\) (bigram), \(N=3\) (trigram) 정도에서는 추정이 가능하나, Markov 가정은 문맥(Context)을 파괴하기 때문에 자연어의 복잡도, 뉘앙스를 재현하기 어렵습니다.
- 2000년 무렵까지 이것이 NLP의 표준이었습니다.
신경망 언어 모델
- 2003년 Bengio와 연구진은 분산 표현을 이용한 신경 확률적 언어 모델을 제안했습니다 4.
- 이 모델은 아래의 세가지 아이디어를 포함합니다:
- 단어를 실수 벡터(embedding)로 표현
- 확률 함수를 해당 임베딩의 함수로 표현
- 신경망을 통해 임베딩과 확률 함수의 파라미터를 동시에 학습(Back-propagation)
- 이 모델은 아래의 세가지 아이디어를 포함합니다:
- 어휘 \(V = \{1, 2, \ldots, V\}\)의 각 단어를 \(D\)차원 벡터로 표현하면, 전체 어휘는 행렬로 나타낼 수 있습니다:
- \(i\)번째 행 \(c_i\)는 \(i\)번째 단어의 단어 임베딩(Word Embedding)입니다.
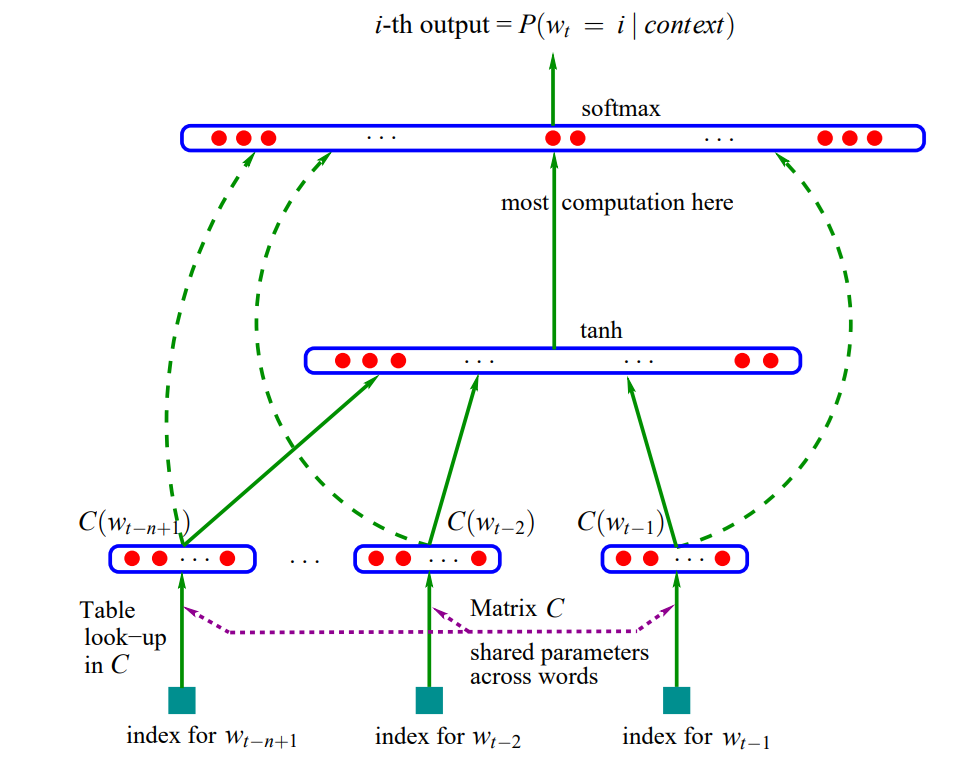 분산 표현 행렬 \(C\)의 구조. 각 행이 한 단어의 \(D\)차원 임베딩이다 4.
분산 표현 행렬 \(C\)의 구조. 각 행이 한 단어의 \(D\)차원 임베딩이다 4.
- 확률 함수를 feed-forward 신경망으로 구현했습니다:
- 학습 파라미터 집합은 단어 임베딩 \(C\)와 신경망 파라미터 \(\theta\)입니다:
모델 작동 방식
- 원 논문의 핵심 논증은 일반화(Generalization) 가능성에 있습니다.
- 의미, 문법적으로 유사한 단어는 비슷한 임베딩을 가지며, 확률 함수는 이 임베딩의 매끄러운(Smooth) 함수입니다.
- 따라서 임베딩이 조금 변하면 확률도 조금 변하며, 학습 데이터에 한 문장만 있어도 그 문장의 임베딩 공간 이웃 문장들에 대해 확률이 동시에 올라갑니다.
- ex. “dog”과 “cat”의 임베딩이 가깝다면,
The cat is walking on the sidewalk과The dog is walking on the sidewalk은 비슷한 확률을 가집니다.- 학습 데이터에 한 문장만 있어도 다른 문장으로 일반화 가능하다는 의미입니다.
자기회귀 프레임워크 Autoregressive Framework
- 핵심 질문 ㅣ Bengio 모델을 어떻게 학습하고, 새 문장을 어떻게 생성하는가?
- 이 프레임워크는 현재의 LLM과 개념적으로 동일한 학습 방식입니다.
- ex. Virginia Woolf의 문장
"Intellectual freedom depends upon material things."을 학습한다고 할 때:- Context window \(N=2\)로 두면, 첫 번째 Non-zero 입력은 “intellectual” 단어의 임베딩 \(c_{I(\text{intellectual})}\)입니다.
- 모델은 \(V\)차원 확률 분포 \(p(w_2 \mid w_1)\)를 출력합니다.
- 정답 단어 “freedom”에 대응되는 One-hot 벡터와 교차 엔트로피(Cross-Entropy) 손실을 계산합니다.
- 한 단어씩 shift하며 반복합니다. \(N=2\) 제약 때문에 세 번째 입력에서는 “intellectual”이 문맥을 벗어나 손실됩니다.
- 이것이 Context Window의 근본적 한계이며, 이후 연구들의 핵심 동기가 됩니다.
목적 함수와 생성
- 교차 엔트로피 최소화는 로그 우도 최대화와 동치이므로, 학습은 다음을 푸는 문제로 일반화됩니다:
Back-propagation과 경사 하강법(Gradient Descent)으로 파라미터 \(\Theta\)를 추정합니다.
- 학습이 끝난 후 문장 생성은 다음과 같이 이루어집니다:
- 첫 단어 \(w_1\)을 어휘에서 샘플링
- 두 번째 단어를 \(p(w_2 \mid w_1)\)에서 샘플링
- 세 번째 단어를 \(p(w_3 \mid w_{1:2})\)에서 샘플링
- 종료 토큰에 도달할 때까지 반복
LLM이 자연어를 이해하는 동시에 생성하는 이유가 여기에 있습니다. 언어 모델은 기술적 모델(descriptive)인 동시에 생성적(generative) 모델입니다.
- 이런 방식으로 학습된 모델을 자기회귀 모델(Autoregressive Model)이라 부릅니다.
- 통계학에서 자기회귀란 변수가 자신의 이전 값으로 예측되는 모델을 의미합니다.
변화
- 핵심 질문 ㅣ Bengio 2003이 랜드마크라면서, 왜 그 후 10년 가까이 실제로는 N-gram이 주류였는가?
- 답은 간단합니다. 신경망을 학습하는 일이 당시엔 너무 어려웠습니다.
- Bengio 모델은 CPU 상에서, 자동 미분 라이브러리도 없이 훈련되었습니다.
AlexNet
- 2012년 ImageNet 대회에 등장한 AlexNet 5은 컴퓨터 비전의 트렌드를 크게 바꾸었습니다.
- ILSVRC-2012 top-5 Test Error 15.3% (2등 26.2%). 상대적 오류율 기준 40% 감소.
- GPU 상에서 대규모 데이터셋(ImageNet)으로 end-to-end 학습된 최초의 deep CNN.
- “2003년 Bengio는 개념적 무대를 놓았고, 2012년 Krizhevsky는 기술적 무대를 놓았다.”
- 이후 NLP 연구자들이 신경망을 규모 있게 학습하려는 시도를 본격화합니다.
Word2Vec
Bengio 모델의 계산 비용을 살펴봅시다. Bengio 모델의 단일 단어 예측 복잡도는 대략 다음과 같이 계산됩니다:
\(V\)는 어휘 크기, \(N\)은 Context Window, \(D\)는 Embedding 차원, \(H\)는 Hidden 차원.
- 어휘 \(V\)가 매우 크기 때문에 \(VH\)가 지배적이며, 거기에 Softmax 정규화까지 더해져 학습이 매우 느렸습니다.
- Mikolov 등이 쓴 두 가지 기법:
- Hierarchical Softmax ㅣ 이진 트리 기반 정규화. 복잡도를 \(\mathcal{O}(V)\)에서 \(\mathcal{O}(\log_2 V)\)로 축소.
- Negative Sampling ㅣ 노이즈 분포에서 \(K\)개 샘플을 뽑아 관측을 노이즈와 구분하도록 학습. 정규화 상수를 명시적으로 계산하지 않음.
- 모델 구조도 극단적으로 단순화합니다. Bengio의 비선형 Hidden Layer를 제거하고 로그-선형(Log-linear) 모델만 남깁니다.
CBOW와 Skip-gram
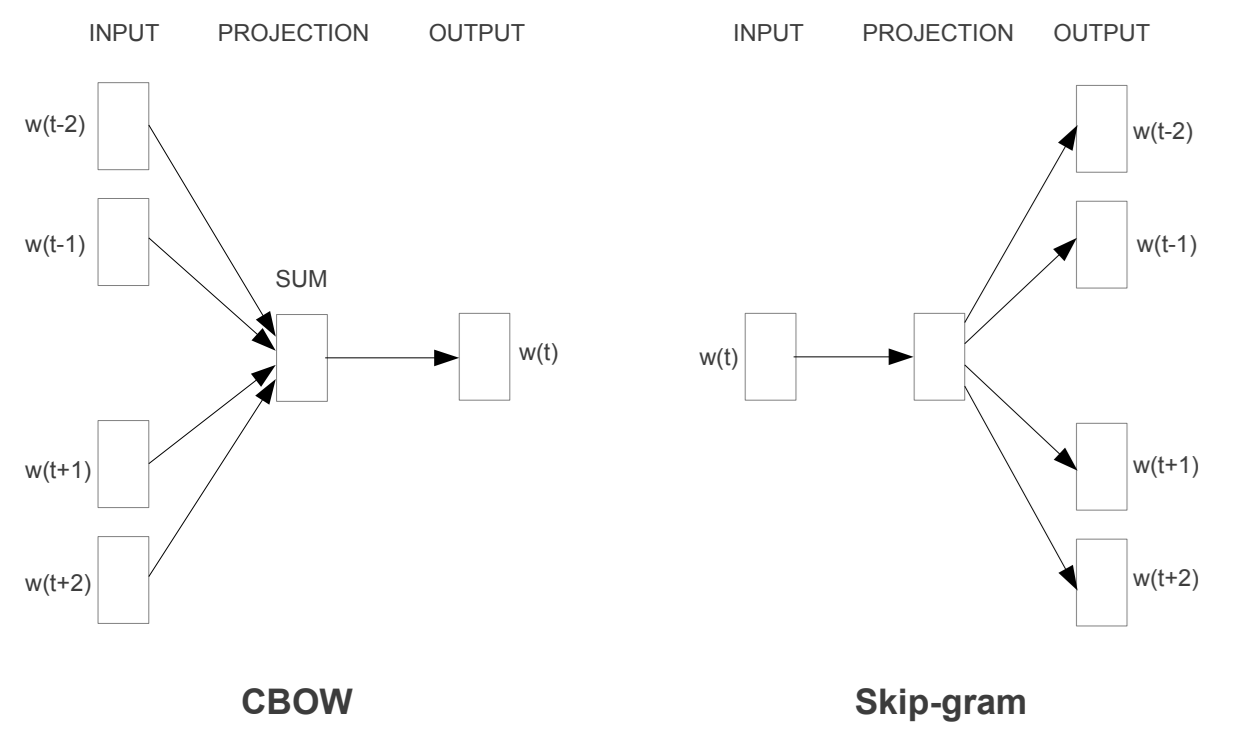 CBOW(왼쪽)와 Skip-gram(오른쪽). 모두 얕은 로그-선형 모델이다 6.
CBOW(왼쪽)와 Skip-gram(오른쪽). 모두 얕은 로그-선형 모델이다 6.
- CBOW(Continuous Bag-of-Words) ㅣ 주변 단어들이 중심 단어를 예측
Skip-gram ㅣ 중심 단어가 주변 단어들을 예측
- Skip-gram의 목적 함수 (window \(N=2C\)):
- 조건부 확률은 로그-선형으로 모델링됩니다:
- 로그를 취하면 선형 형태가 드러납니다:
\(Z\)는 정규화 상수이며, Negative Sampling을 쓰면 명시적 계산이 불필요합니다.
중요한 subtlety ㅣ CBOW/Skip-gram은 완전한 언어 모델이 아닙니다. 좋은 단어 임베딩을 학습하기 위한 보조 목적일 뿐입니다.
- 그러나 이 얕은 모델들은 대규모 학습이 가능했고, 결과는 놀라웠습니다.
언어 규칙성의 발현 Emergent Linguistic Regularities
핵심 질문 ㅣ 단순한 선형 모델이 왜 의미·문법 구조를 포착하는가?
- Mikolov 등은 단어 임베딩에서 유의미한 선형 오프셋이 관찰됨을 보였습니다 8.
- 즉, 많은 의미·문법 관계가 임베딩 공간에서 거의 일정한 벡터 차이로 표현됩니다.
- ex. “king is to queen as man is to woman”:
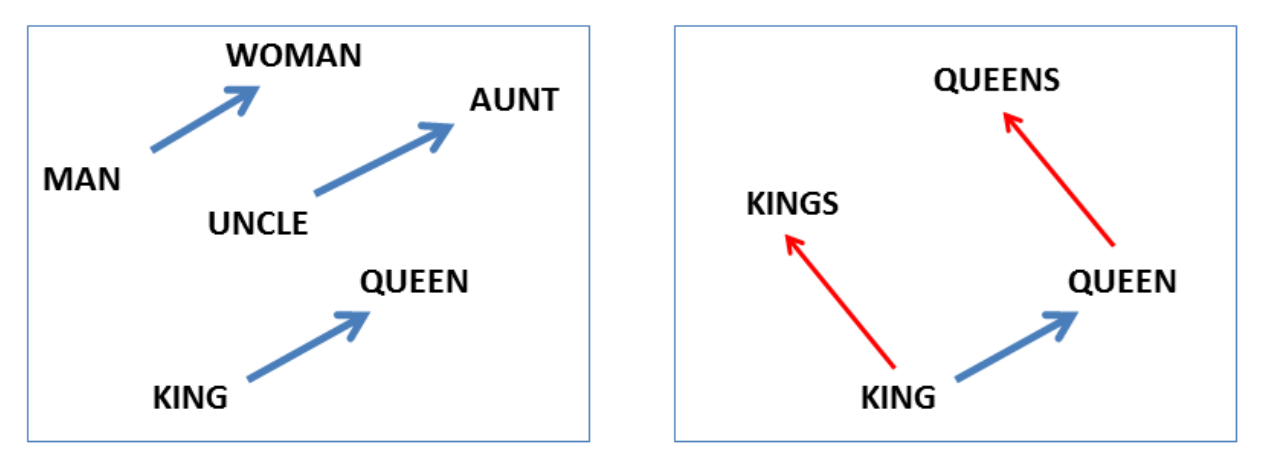 고차원 단어 임베딩 공간에서는 하나의 단어가 성별, 단수·복수 등 여러 의미 관계를 동시에 벡터 방향으로 표현할 수 있다 8.
고차원 단어 임베딩 공간에서는 하나의 단어가 성별, 단수·복수 등 여러 의미 관계를 동시에 벡터 방향으로 표현할 수 있다 8.
- ex:
- 단어는 이산적(Discrete) 객체이며, 단어의 작은 변화는 직관적일 뿐 수학적으로 정의되지 않습니다.
- 임베딩 공간은 이 직관을 구체화합니다. 의미가 가까운 단어끼리 가까운 벡터를 가진다는 것은, 연속적인 벡터 공간에서 이산적 의미 구조가 거의 선형적으로 유지됨을 뜻합니다.
- 이후 문맥 의존 임베딩(Contextualized Embedding) 계열이 등장합니다.
- Peters 등 2018의 ELMO는 Bidirectional LSTM의 Hidden State를 문맥 의존 임베딩으로 사용합니다 9.
- 사전학습 임베딩과 지도학습 Fine-tuning을 결합하는 방향을 미리 보여준 작업입니다.
적응적 문맥 Adaptive Context
핵심 질문 ㅣ 고정 크기 Context Window를 넘어 임의 길이 시퀀스를 어떻게 다룰 것인가?
2013년경까지 임베딩은 잘 작동했지만, 여전히 고정 Window 안에서만 유효했습니다.
- 이 한계를 극복한 모델이 Sequence-to-Sequence(Seq2Seq) 모델입니다.
RNN 인코더-디코더
- Seq2Seq 모델의 구조:
- Encoder ㅣ 가변 길이 입력 시퀀스를 고정 길이 벡터로 압축
- Decoder ㅣ 이 벡터를 다시 가변 길이 출력 시퀀스로 복원
- 대표 논문 3편은 다음과 같습니다 10 11 12:
- Kalchbrenner & Blunsom (2013) ㅣ CSM 인코더 + RNN 디코더
- Cho et al. (2014) ㅣ 두 개 RNN 구조 (encoder-decoder 모두 RNN)
- Sutskever et al. (2014) ㅣ LSTM 기반 encoder-decoder, vanishing gradient 문제 완화
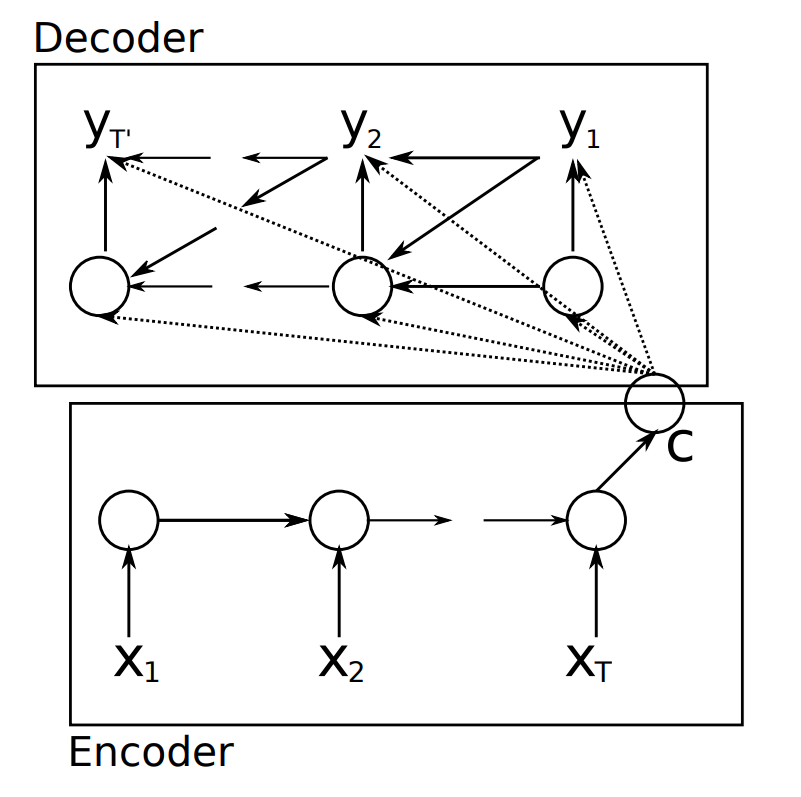 RNN 인코더-디코더 구조. 인코더의 Hidden States \(H\)가 고정 길이 Context Vector \(c\)로 압축된 뒤 디코더로 전달된다 11.
RNN 인코더-디코더 구조. 인코더의 Hidden States \(H\)가 고정 길이 Context Vector \(c\)로 압축된 뒤 디코더로 전달된다 11.
RNN 상태 수식
- 가변 길이 입력 \(X = \{x_1, x_2, \ldots, x_{T_x}\}\), 출력 \(Y = \{y_1, y_2, \ldots, y_{T_y}\}\)를 정의합니다.
- 인코더의 Hidden State는 재귀적으로 계산됩니다:
- 간단한 RNN 유닛은 다음과 같은 비선형 함수로 구체화됩니다:
- Context Vector \(c\)는 Hidden State들의 함수로 정의됩니다:
가장 단순한 선택은 \(c = h_{T_x}\)로, 마지막 Hidden State를 그대로 사용하는 것입니다.
디코더도 재귀 관계를 갖습니다:
- 학습 목적은 로그 우도 최대화입니다:
고정 벡터의 병목
- RNN Encoder-decoder 프레임워크는 강력했지만, 큰 한계가 있었습니다.
- 문장이 길어질수록 고정 크기 Context Vector \(c\)에 정보를 압축해야 했고, 장거리 의존성이 손실됐습니다.
- Cho 등(2014)은 BLEU 점수가 문장 길이에 따라 급격히 열화됨을 실험으로 확인했습니다.
- 이 병목을 깨는 답이 Attention 메커니즘이었습니다.
Attention
- 핵심 질문 ㅣ 고정 벡터로 압축하지 않고, 디코더가 필요할 때마다 인코더의 특정 부분을 참조할 수는 없을까?
NMT에서의 Attention 등장
- Bahdanau et al. (2014)은
Neural Machine Translation by jointly learning to align and translate에서 미분 가능한 Attention 레이어를 NMT에 최초로 성공적으로 적용했습니다 13.- 원문 표현: “parts of a source sentence that are relevant to predicting a target word”를 자동으로 (Soft) 탐색.
- 각 디코더 Hidden State \(s_i\)가 자신만의 Context Vector \(c_i\)를 가집니다. 이 \(c_i\)는 모든 인코더 Hidden State의 가중 합입니다:
- Attention 가중치 \(\alpha_{ij}\)는 Softmax 정규화된 정렬(Alignment) 점수입니다:
- \(\alpha_i\)는 정렬 벡터(Alignment Vector)로, 디코더가 인코더의 어느 부분을 얼마나 참조할지 결정합니다.
- 모델 파라미터 \(v_a, W_a, U_a\)는 End-to-End 로 학습됩니다.
Attention의 차원 정리
- Luong et al. (2015)은 Bahdanau의 아이디어를 단순화하며 Attention의 여러 형태를 체계화했습니다 14.
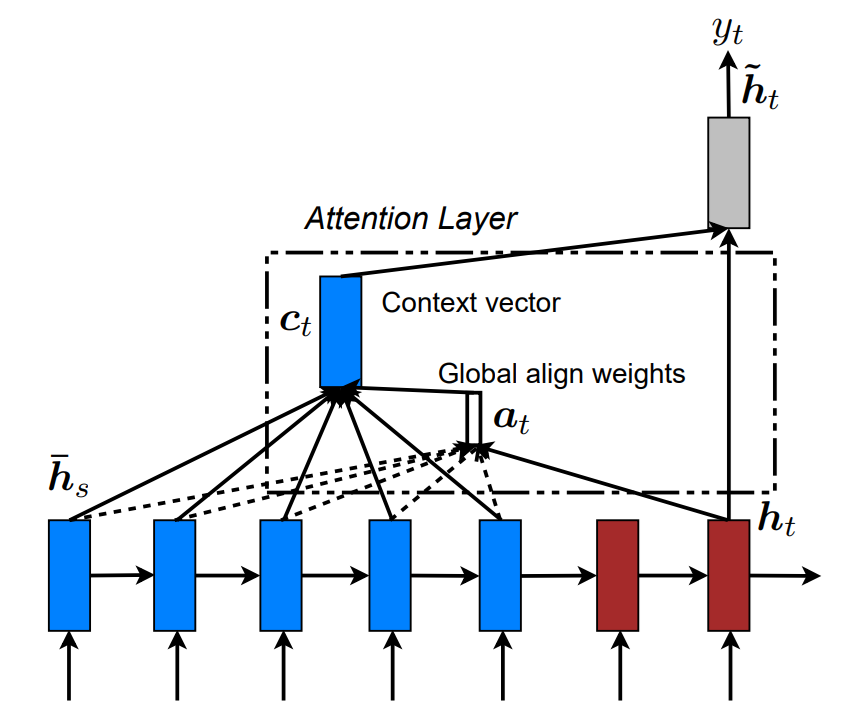 Attention 유형 1. Global — 모든 소스 상태 참조 14
Attention 유형 1. Global — 모든 소스 상태 참조 14
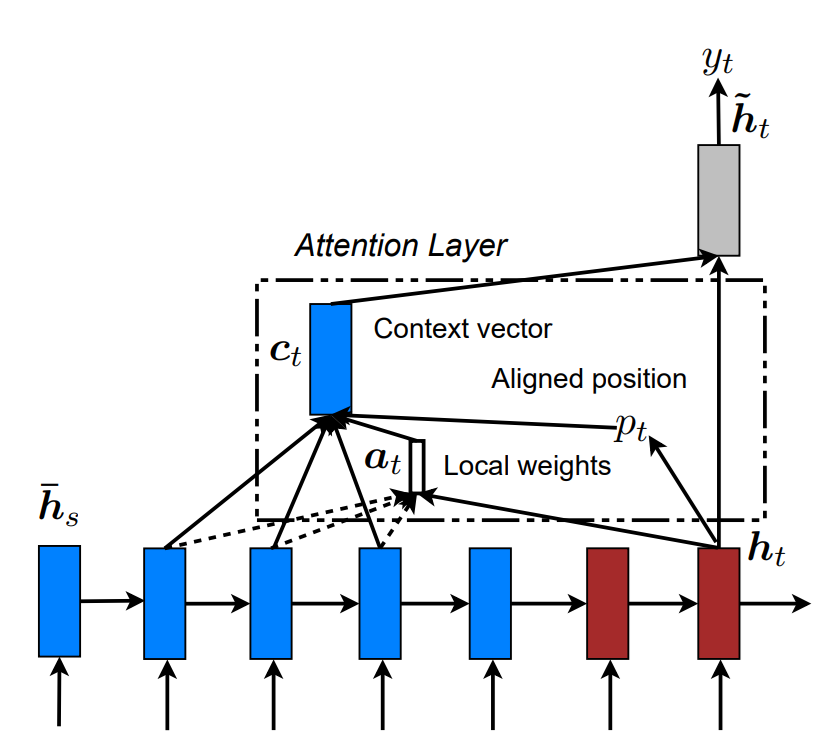 Attention 유형 2. Local — 일부 상태만 참조 14
Attention 유형 2. Local — 일부 상태만 참조 14
- 차원 1: 범위 — Global vs Local Attention
- Global ㅣ 모든 인코더 Hidden State를 참조 (\(a=1, b=T_x\))
- Local ㅣ 일정 윈도우만 참조
- 차원 2: 점수 함수 — Alignment Score Function
- 세 가지 주요 점수 함수:
이후 Transformer가 선택하는 형태는 Dot-product Attention입니다. 두 벡터의 내적은 유사도(Similarity)의 자연스러운 척도이기 때문입니다.
- 차원 3: 관심 변수의 출처 — Cross vs Self Attention
- Query(Q), Key(K), Value(V) 는 정보 검색(Information Retrieval)에서 차용된 개념입니다:
- Query ㅣ 사용자가 찾는 것
- Key ㅣ 검색 대상의 메타데이터
- Value ㅣ 실제로 반환되는 내용
- Cross-Attention ㅣ Query는 한 집합에서, Key·Value는 다른 집합에서 (Bahdanau와 동일)
- Self-Attention ㅣ Query, Key, Value 모두 같은 집합에서
- Query(Q), Key(K), Value(V) 는 정보 검색(Information Retrieval)에서 차용된 개념입니다:
- Self-Attention을 NLP에 최초로 적용한 것은 Cheng et al. (2016)의 “LSTM-Networks for Machine Reading”으로 알려져 있습니다 15.
- 시퀀스가 자기 자신의 어느 부분에 주목할지를 결정할 수 있게 되었습니다.
Transformer
핵심 질문 ㅣ 재귀 연산(RNN)을 완전히 제거하고 Attention만으로 시퀀스 모델링을 할 수 있을까?
- 2017년 Vaswani et al.은 Attention is all you need에서 정확히 이 제안을 합니다 16.
- 원문 그대로: “We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely.”
- 왜 좋은 아이디어인가?
- RNN의 순차적 성질은 학습 병렬화를 막는다는 한계가 있었습니다.
- Attention은 병렬 처리가 가능합니다. 규모 확장이 가능하다면, 충분히 좋아질 수 있다는 전제입니다.
- 실제로 8개의 P100 GPU로 12시간 학습한 결과가 당시 최첨단 번역 품질에 도달했습니다.
아키텍처
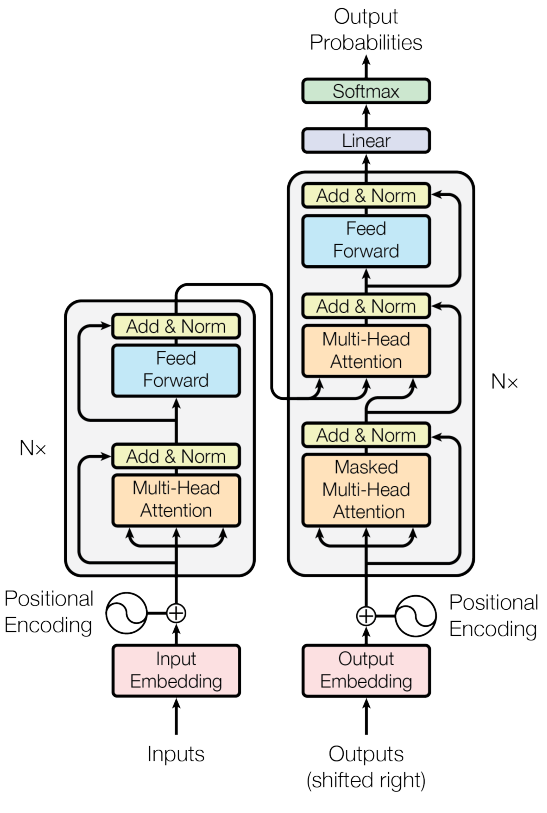 Transformer 아키텍처. Encoder와 Decoder 모두 Positional Encoding과 Multi-head Self-attention을 사용한다 16.
Transformer 아키텍처. Encoder와 Decoder 모두 Positional Encoding과 Multi-head Self-attention을 사용한다 16.
- Transformer는 Encoder-decoder 구조를 유지하되, 내부를 모두 Attention으로 대체합니다:
- Positional Encoding ㅣ Attention 자체엔 순서 정보가 없으므로, 입력 벡터에 위치 의존적 정보를 더함
- Multi-Head Self-Attention (Encoder) ㅣ 입력 시퀀스 내부의 의존성 포착
- Masked Multi-Head Self-Attention (Decoder) ㅣ 디코딩 시 미래 토큰을 가려 Autoregressive 구조 유지
- Cross-Attention (Encoder–Decoder) ㅣ Bahdanau 스타일로 인코더 출력을 디코더에서 참조
- Layer Normalization + Residual Connection ㅣ 기존 기법을 그대로 차용
Scaled Dot-Product Attention
- Transformer의 핵심 연산은 Scaled dot-product Attention입니다.
- Query 행렬 \(Q \in \mathbb{R}^{M \times D_k}\), Key 행렬 \(K \in \mathbb{R}^{N \times D_k}\), Value 행렬 \(V \in \mathbb{R}^{N \times D_v}\)에 대해:
- 이 식은 Luong의 Dot-product Attention에 스케일링 계수 \(\sqrt{D_k}\) 만 추가한 뒤 행렬 형태로 패키징한 것입니다.
- 동일한 연산을 여러 샘플에 대해 한 번에 병렬 계산할 수 있도록 해줍니다.
- Transformer에서의 Q/K/V 해석:
- Encoder Self-attention ㅣ Q, K, V 모두 같은 입력 시퀀스에서 유도
- Decoder Self-attention ㅣ Q, K, V 모두 출력 시퀀스에서 유도
- Encoder–Decoder Attention ㅣ Q는 디코더 상태, K·V는 인코더 출력
Multi-Head Attention
- 단일 Attention 대신 여러 개 Attention을 병렬로 수행합니다.
- 각 Head가 서로 다른 파라미터 집합 \(\{W_a, U_a, v_a\}_{a=1, \ldots, A}\)를 가집니다.
- 각 Head는 언어의 서로 다른 측면을 학습합니다 (경험적으로).
- 성능 및 효율
- 기존 ConvS2S Ensemble은 영어→프랑스어 학습에 약 \(1.2 \times 10^{21}\) FLOPs가 필요했습니다.
- Transformer는 \(3.3 \times 10^{18}\) FLOPs로 동일 수준의 BLEU를 달성했습니다.
- 약 360배 계산 절감. 단순히 성능이 좋아진 것이 아니라, 모델링 정확도와 확장성의 파레토 경계를 옮겼다는 데에 의의가 있습니다.
생성적 사전학습 Generative Pre-training
- Transformer 아키텍처만으로는 오늘의 LLM이 완성되지 않았습니다.
- 원 Transformer는 최대 2.13M 파라미터, WMT 2014 데이터셋(약 3,600만 문장) 규모였습니다.
- 학습 방식의 진화가 있어야 오늘날 사람들이 만나는 LLM이 가능했습니다.
- OpenAI가 GPT 시리즈를 통해 제시한 세 단계 훈련 파이프라인이 대표적입니다:
- Generative Pre-training ㅣ 대량 Unlabeled 데이터에 대한 Next-word Prediction
- Discriminative Fine-tuning ㅣ 특정 Task에 대한 지도 학습
- RLHF ㅣ 인간 피드백 기반 강화 학습
GPT | 사전학습 + 파인튜닝
- 2018년 OpenAI는 Improving Language Understanding by Generative Pre-Training을 발표합니다 17.
- Transformer를 가능한 한 많은 Unlabeled 데이터로 사전학습한 뒤, 소량의 Labeled 데이터로 Task에 맞게 Fine-tune.
- 사전학습 목적 함수 (자기회귀 프레임워크 그대로)
- 라벨이 불필요하므로 방대한 데이터로 학습 가능합니다.
BERT | Masked Language Model
- GPT는 좌→우 자기회귀 방식이라 양방향 문맥이 필요한 Downstream Task에 약점이 있습니다.
- 2019년 Google AI는 BERT를 제안했습니다 18. 핵심은 Masked Language Model(MLM) 목적 함수입니다.
- 입력 \(w_{1:T}\)의 위치 집합 \(M \subset \{1, \ldots, T\}\)을 무작위로 가리고, 가려지지 않은 토큰 \(w_{\neg M}\)을 보고 가려진 토큰을 예측:
- 좌우 양방향 Context를 동시에 활용할 수 있게 됩니다.
Discriminative Fine-tuning
- 사전학습만으로는 모델을 실제 사례에 적용하기에 충분하지 않습니다.
- ex. “I am having trouble getting a date. Any advice?”라는 질문에 next-word 예측만 하는 모델은 “You’ll never find true love!” 같은 이상한 답을 낼 수 있습니다.
- 따라서 Task 특화 데이터로 지도학습 Fine-tuning을 이어서 수행합니다:
- 사전학습된 지식을 잃지 않도록 두 목적을 가중 결합하기도 합니다:
- 단, GPT-2, GPT-3 이후로는 Fine-tuning 없이도 Zero-shot·Few-shot 성능이 나오기 시작하며, 사전학습 자체의 규모가 훨씬 더 중요해집니다.
정렬 Alignment
거짓말을 하지 않거나, 인종차별적 농담을 하지 않거나, 성적인 발언을 하지 않는 것
자기회귀 프레임워크엔 이런 제약이 내재되어 있지 않습니다.
일부 속성은 Fine-Tuning용 데이터셋(ETHICS, RealToxicityPrompts 등)으로 다룰 수 있지만, 상당수 가치는 정의 자체가 어려워 데이터셋 제작이 어렵습니다.
그 해답으로 등장한 것이 RLHF(Reinforcement Learning from Human Feedback)입니다.
- 원래는 보상 함수를 명세하기 어려운 RL 문제를 위한 방법이었습니다 19.
RLHF
- RLHF의 3단계
- (1) 선호 데이터 수집 ㅣ 여러 후보 응답을 생성하고, 사람이 선호를 순위로 라벨링
- (2) 보상 모델 학습 ㅣ 어떤 응답을 사람이 선호하는지를 예측하는 보상 함수를 학습
- (3) RL 정책 Fine-Tuning ㅣ 보상 모델의 신호를 바탕으로 PPO(Proximal Policy Optimization) 20 같은 표준 RL 알고리즘으로 LLM을 Fine-tune
- 적용
- GPT-2 ㅣ “Fine-tuning language models from human preferences”
- GPT-3 ㅣ “Training language models to follow instructions with human feedback”
- GPT-4 ㅣ 공식 whitepaper에서도 RLHF 사용 명시
- Anthropic는 “helpful, honest, harmless”라는 HHH 기준을 세우고 imitation learning, binary discrimination, ranked preference modeling 등 다양한 정렬 기법을 탐구하고 있습니다.
- 다만 정렬은 여전히 열린 문제입니다.
Bitter Lesson | 규모가 이긴다 21:
- Richard Sutton의 유명한 블로그 글 Bitter Lesson에서 AI 역사는 일반적·계산 효율적·확장 가능한 방법이 도메인 지식을 이긴다는 것을 반복적으로 보여줍니다.
- Chain-of-Thought 추론조차 100B 이상 모델에서만 효과가 나타납니다 22.
이는 전문가의 도메인 지식·수작업 Feature가 순수 계산과 학습된 표현에 밀린다는 경험적 관찰입니다.
- 그렇다고 모든 전문성이 무의미한 것은 아닙니다.
- AlphaFold 23 는 Blackbox Deep Learning과 생물학 사전 지식(진화적으로 가까운 서열, 동족 단백질의 3D 좌표)을 결합해 단백질 구조 예측에서 거의 실험 수준 정확도를 달성했습니다.
- 강력한 머신러닝과 도메인 전문성의 결합이 아직도 합당한 전략입니다.
- Hinton은 2024 BBC 인터뷰에서 LLM이 실제로 자연어를 이해한다고 주장합니다.
- 그의 관점에서 LLM은 뇌가 언어를 이해하는 방식에 대한 현재 우리의 최선의 이론이기도 합니다.
Summary
- 40여 년의 학술적 계보를 한 줄로 요약하면 다음과 같습니다:
- 1980s ㅣ 분산 표현·역전파(Rumelhart, Hinton)
- 2003 ㅣ Bengio — 분산 표현 기반 신경 확률적 언어 모델
- 2012 ㅣ AlexNet — 대규모 신경망 학습의 개막
- 2013 ㅣ Word2Vec — 확장 가능한 임베딩 학습
- 2014 ㅣ Seq2Seq, RNN encoder-decoder
- 2014 ㅣ Bahdanau — NMT에서의 Attention
- 2015 ㅣ Luong — Attention의 형태 정리
- 2017 ㅣ Transformer — “Attention is all you need”
- 2018 ㅣ GPT — 생성적 사전학습
- 2019 ㅣ BERT — 양방향 Masked Language Model
- 2017~ ㅣ RLHF — 인간 선호 기반 정렬
- 현재의 LLM
- OpenAI GPT 계열 (GPT-1 ~ GPT-4)
- Google Gemini, PaLM, LaMDA, Gopher, BERT
- Anthropic Claude (Haiku, Sonnet, Opus)
- Meta LLaMA
- Open-weight: DeepSeek-R1 등
- 본질은 모두 대규모로 사전학습된 Transformer 계열, next-word prediction 기반
- 크기/규모 변화
- GPT-1 ㅣ ~117M 파라미터
- GPT-2 ㅣ ~1.5B
- GPT-3 ㅣ ~175B
- Gopher (2021) ㅣ 280B
- PaLM (2022) ㅣ 540B
- 현재의 모델은 trillion 규모에 도달한 것으로 추정됩니다.
Conclusion
- LLM은 하나의 혁신이 아니라 40여 년 간의 연구들이 누적된 결과입니다.
- 각 단계는 앞 단계의 한계를 풀기 위한 최소 변경에 가까웠고, 규모(scale)의 힘이 결합되며 현재의 성능을 만들어냈습니다.
- LLM의 두 가지 원리:
- Attention ㅣ 문맥 윈도우의 한계를 푸는 방법의 진화 — 고정 벡터(RNN) → 가중합(Bahdanau) → 병렬화 가능한 dot-product(Transformer)
- Bitter Lesson ㅣ 단순한 아이디어를 규모로 학습할 때 이긴다
- 현재의 LLM을 다시 바라보면:
- 자기회귀 프레임워크는 Bengio 2003 그대로입니다.
- 다른 점은 스케일, 데이터, 사전학습 절차, 그리고 정렬(RLHF)입니다.
- 남은 과제들도 여전히 많습니다:
- 왜 스케일이 작동하는가? 명확한 이론적 설명은 없습니다.
- 정렬은 어떻게 일반화되는가? 열린 문제입니다.
- 어느 지점에서 다음 패러다임이 필요할까? 알 수 없습니다.
References
Brown, Peter F., et al. “A statistical approach to machine translation.” Computational Linguistics 16.2 (1990): 79-85. ↩︎
Markov, Andrey. “Example of a statistical investigation of the text Eugene Onegin concerning the connection of samples in chains.” (1913). ↩︎
Bengio, Yoshua, et al. “A neural probabilistic language model.” Journal of Machine Learning Research 3 (2003): 1137-1155. ↩︎ ↩︎2
Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. “ImageNet classification with deep convolutional neural networks.” Advances in Neural Information Processing Systems 25 (2012). ↩︎
Mikolov, Tomas, et al. “Efficient estimation of word representations in vector space.” arXiv preprint arXiv:1301.3781 (2013). ↩︎ ↩︎2
Mikolov, Tomas, et al. “Distributed representations of words and phrases and their compositionality.” Advances in Neural Information Processing Systems 26 (2013). ↩︎
Mikolov, Tomas, Wen-tau Yih, and Geoffrey Zweig. “Linguistic regularities in continuous space word representations.” NAACL-HLT (2013). ↩︎ ↩︎2
Peters, Matthew E., et al. “Deep contextualized word representations.” NAACL-HLT (2018). ↩︎
Kalchbrenner, Nal, and Phil Blunsom. “Recurrent continuous translation models.” EMNLP (2013). ↩︎
Cho, Kyunghyun, et al. “Learning phrase representations using RNN encoder–decoder for statistical machine translation.” EMNLP (2014). ↩︎ ↩︎2
Sutskever, Ilya, Oriol Vinyals, and Quoc V. Le. “Sequence to sequence learning with neural networks.” NeurIPS (2014). ↩︎
Bahdanau, Dzmitry, Kyunghyun Cho, and Yoshua Bengio. “Neural machine translation by jointly learning to align and translate.” arXiv preprint arXiv:1409.0473 (2014). ↩︎
Luong, Minh-Thang, Hieu Pham, and Christopher D. Manning. “Effective approaches to attention-based neural machine translation.” arXiv preprint arXiv:1508.04025 (2015). ↩︎ ↩︎2 ↩︎3
Cheng, Jianpeng, Li Dong, and Mirella Lapata. “Long short-term memory-networks for machine reading.” EMNLP (2016). ↩︎
Vaswani, Ashish, et al. “Attention is all you need.” Advances in Neural Information Processing Systems 30 (2017). ↩︎ ↩︎2
Radford, Alec, et al. “Improving language understanding by generative pre-training.” (2018). ↩︎
Devlin, Jacob, et al. “BERT: Pre-training of deep bidirectional transformers for language understanding.” NAACL-HLT (2019). ↩︎
Christiano, Paul F., et al. “Deep reinforcement learning from human preferences.” Advances in Neural Information Processing Systems 30 (2017). ↩︎
Schulman, John, et al. “Proximal policy optimization algorithms.” arXiv preprint arXiv:1707.06347 (2017). ↩︎
Wei, Jason, et al. “Chain-of-thought prompting elicits reasoning in large language models.” Advances in Neural Information Processing Systems 35 (2022). ↩︎
Jumper, John, et al. “Highly accurate protein structure prediction with AlphaFold.” Nature 596.7873 (2021): 583-589. ↩︎