의료 인공지능의 모든 것 | Medical AI
🦠 의료 분야 인공지능 기술과 최신 동향을 정리했습니다.
KEYWORDS
의료 인공지능, 의료 인공지능 사례, 의료 인공지능 전망, 헬스케어 인공지능, 헬스케어 인공지능 사례, Medical AI, Medical AI Challenge
Introduction
- 1970년부터 1990년 즈음에는 저수준의 픽셀 처리와 수학적 모델링을 기반으로 한 Rule-based 시스템 및 전문가 시스템이 널리 활용되었습니다.
- 1990년대 후반부터는 지도학습과 같은 기계 학습 접근 방식이 활용되기 시작하였으며, 시스템은 사람이 설계하고 예제 데이터를 사용하여 모델을 훈련하는 방식으로 발전하였습니다.
- 특히 연구자가 직접 이미지로부터 추출한 Handcrafted Features를 기반으로 최적의 결정 경계를 도출하였습니다.
- 딥러닝의 도입 이후 컴퓨터가 데이터를 통해 최적의 특성을 스스로 학습하게 되었습니다.
- 주로 이미지에 대해 여러 층을 가진 CNN(Lenet, Alexnet 등)이 널리 사용되었으며, Imagenet 챌린지와 같은 성과를 기반으로 의료 영상 분석 분야에서도 딥러닝 기법으로 연구 방향이 점진적으로 전환되었습니다.
- 주요 기술적 발전으로는 주성분 분석(PCA), 이미지 패치 클러스터링, 사전 접근법(Dictionary Approaches), CNN (Convolutional Neural Network) 등의 기법이 있습니다.
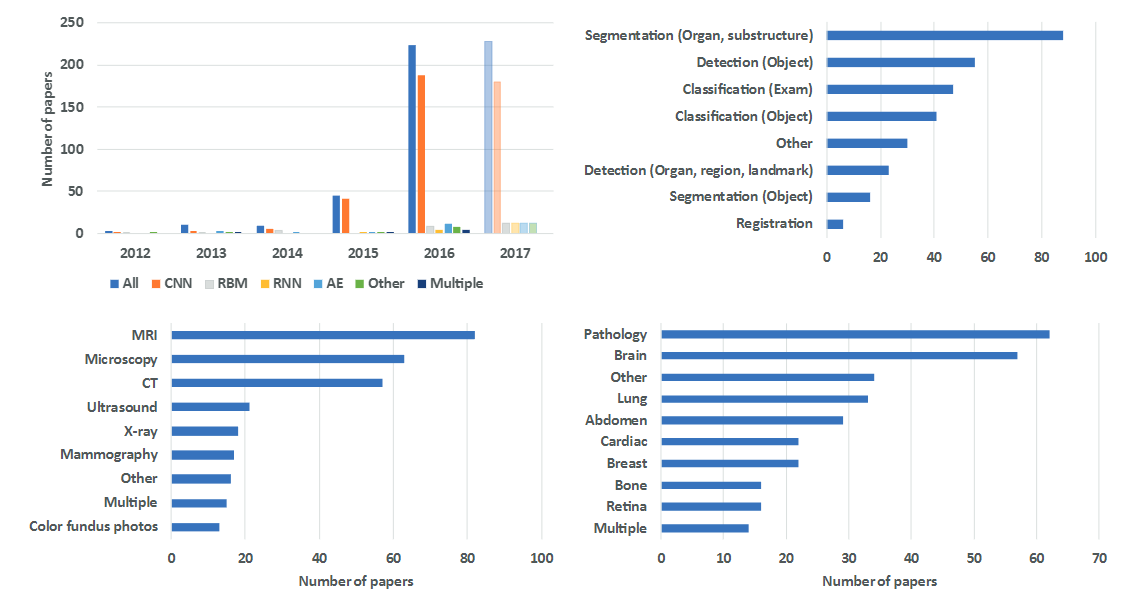 Number of Papers in medical AI field 1
Number of Papers in medical AI field 1
Dataset
- 원천 의료 데이터
- 질병 예후, 공공 건강 기록, 생체 데이터, 의료 영상 등이 있습니다.
- 임상 데이터 ㅣ 환자 기록, 생활 습관, 병력
- 생체 의학 데이터 ㅣ 유전체 정보, 약물 연구
- 특징
- 높은 복잡성, 많은 변수, 계층 불균형, 수집 과정에서 발생한 누락 데이터로 인한 낮은 데이터 품질이 특징입니다.
- 형태
- 구조화 데이터 ㅣ 인구 통계, 생활 습관, 병력
- 비구조화 데이터 ㅣ 의사-환자 대화, 의사의 조사 기록
Machine Learning
- 의료 분야에서 머신러닝은 데이터를 통해 올바른 예측을 하기 위해 적절한 특성(Feature)을 찾는 것이 중요합니다.
- 과거에는 의료 전문가가 의료 이미지를 해석하거나 특정 결과를 설명하기 위한 의미 있는 설명자(Descriptor)를 개발하였습니다.
- 최근에는 방대한 양의 데이터가 지속적으로 생성되며 여러 머신러닝 기법을 활용할 수 있게 되었고, 이는 전문가만큼 정확한 예측을 가능하게 합니다.
- 암 연구 ㅣ 임상 이미징 배열에서 관련된 특성 (Feature)을 정확히 찾아내어 암 치료의 초기 지표를 탐지합니다.
- 임상 응용 ㅣ 머신러닝 예측은 예후, 진단, 이미지 검사 및 치료 과정에서 임상 의사의 업무를 보완합니다.
- 예측, 분류, 클러스터링, 회귀 등 여러 가지 작업을 처리하는 다양한 알고리즘이 존재합니다.
서포트 벡터 머신 Support Vector Machine, SVM
- SVM은 데이터 포인트를 고차원 공간으로 매핑하여 최대한 멀리 떨어져 있는 두 클래스 사이의 초평면(Hyperspace)을 사용해 구분합니다.
- 초평면은 두 클래스 사이의 거리를 최대화하며 커널 함수를 활용해 최적의 초평면을 구분하고 비선형 문제를 해결할 수 있습니다.
- 변수에 비해 작은 데이터셋에서 효과적이므로 질병 예측 및 진단과 같은 의학 분야에서 널리 적용됩니다.
- 사례
- Dallora et al. (2017) ㅣ 경도 인지 장애가 있는 환자가 알츠하이머 병으로 발전할지 여부를 예측하였습니다.
- Taylor et al. (2018) ㅣ 요로 감염을 예측하기 위해 사용되었습니다.
- Leha et al. (2019) ㅣ 폐 고혈압 진단 작업에 사용되었습니다.
- Meiring et al. (2018) ㅣ 중환자실(ICU) 환자들의 생존율 예측에 사용되었습니다.
- Formulation
 Formulations of the SVM 2
Formulations of the SVM 2
군집화 Clustering
- 군집화는 데이터 내의 유사성을 찾아 그룹화하는 방법이며, 라벨이 없는 데이터를 유의미한 군집(Cluster)으로 분류하는 기법입니다.
- Proximity Measure는 유클리드 거리와 같은 측정 방법을 사용하여 데이터 간의 유사성을 계산합니다.
- K-means Clustering은 데이터 포인트를 초기 무작위 군집으로 할당한 후, 각 군집의 중심에서 데이터 포인트들을 거리에 따라 재할당하는 방식으로 작동합니다.
- 유전적 발현 데이터와 단백질 도메인과 같은 데이터에 광범위하게 사용됩니다.
- 사례
- Khan et al. (2017) ㅣ 유방암 및 간 질환 진단에서 다른 알고리즘에 비해 좋은 성능을 도출하였습니다.
- Formulation
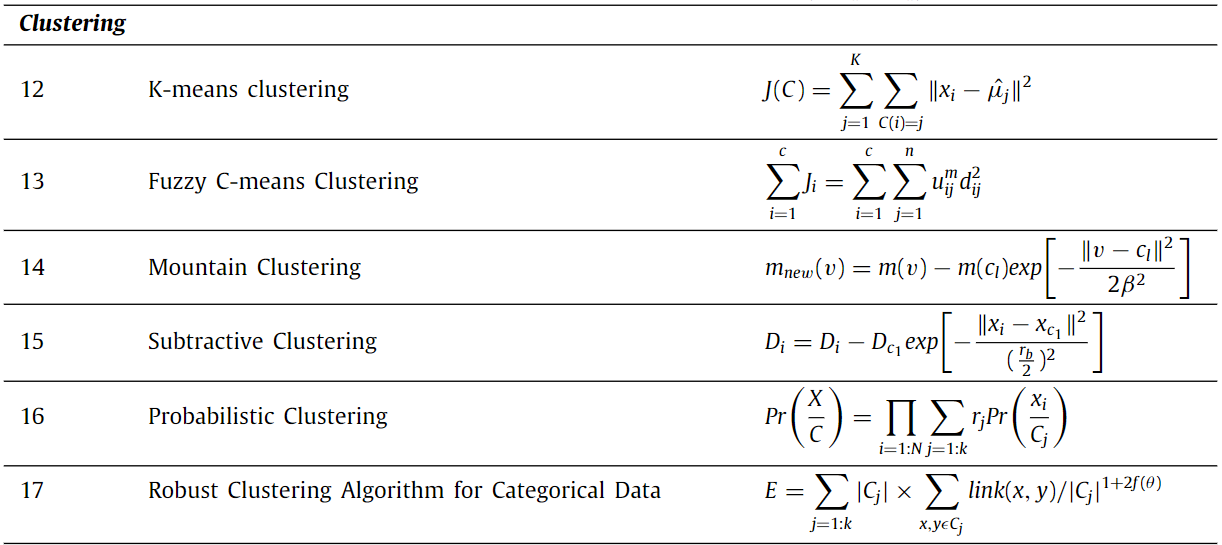 Formulations of clustering methods 2
Formulations of clustering methods 2
결정 트리 Decision Tree, DT
- 학습된 지식을 if-then 규칙으로 구성된 트리에 포함하며, 트리의 각 노드는 학습 변수를 나타냅니다.
- 데이터를 분류하기 위해 정보 이득(Information Gain) 및 Entropy를 계산합니다.
- 높은 정보 이득은 더 많은 정보를 포함하고 있다는 의미입니다.
- 정보를 반복적으로 분할하여 가장 적절한 특징을 찾아내고, 더 이상 분할할 수 없을 때까지 해당 과정을 반복합니다.
- Formulation
 Formulations of the decision tree 2
Formulations of the decision tree 2
랜덤 포레스트 Random Forest, RF
- 여러 개의 결정 트리를 모아 놓은 모델로, 각 트리가 분류 작업을 수행하고 다수결 투표로 최종 결과를 결정합니다.
- 개별 트리의 예측치를 평균 내어 최종 예측을 산출합니다.
- 깊은 트리일수록 과적합이 발생하기 쉬운데, RF는 다수의 트리를 사용함으로써 이를 방지합니다.
- 사례
- Wang et al. (2015) ㅣ 상관관계가 없는 여러 결정 트리를 사용하여 미국에서 진단된 당뇨병 환자의 의료비를 예측하였습니다.
- Goto et al. (2018) ㅣ 병원 응급실에서 천식 또는 만성 폐쇄성 폐질환 환자의 중환자 치료 또는 입원 여부를 예측하였습니다.
- Zhu et al. (2018) ㅣ 각 결정 트리의 투표에 가중치르 곱하여 클래스의 신뢰도를 강화하고 RF의 클래스 불균형 문제를 해결하였습니다.
- Formulation
 Formulations of the random forests 2
Formulations of the random forests 2
K-nearest Neighbor KNN
- KNN은 분류되지 않은 데이터 포인트를 가장 가까운 K개의 데이터 포인트의 다수결에 따라 분류하는 기법입니다.
- 유클리드 거리, 맨해튼 거리, 해밍 거리 등의 거리 계산 방법이 활용됩니다.
- 모든 특징에 동등하게 가중치를 부여하기 때문에 많은 속성값을 가지는 데이터에는 적합하지 않습니다.
- Fuzzy KNN은 데이터 포인트를 특정 클래스가 아닌 샘플 벡터에 할당하여 추가적인 검토를 통해 최종 분류하는 방식입니다.
- 사례
- Zhang et al. (2016) ㅣ 의료 데이터에 KNN을 적용하기 위한 준비의 중요성을 강조하며 수학적 증거를 제시하였습니다.
- Chen et al. (2017) ㅣ 구조화된 환자 데이터(인구통계학적 정보, 생활 습관, 혈액 검사 결과, 질병 등)를 활용하여 뇌경색증의 위험을 예측하였습니다.
- Formulation
 Formulations of the KNN 2
Formulations of the KNN 2
나이브 베이즈 Naive Bayes
- 나이브 베이즈는 주어진 특징 집합을 기반으로 클래스를 예측하는 기법이며, Bayes’ Theorem에 기초하여 작동합니다.
- 각 특징의 확률을 다른 특징들로부터 얻은 정보를 기반으로 계산하여 독립성을 확보합니다.
- 불필요한 특징을 제거하여 분류 정확도를 향상시키며, 특히 텍스트 분류에서 탁월한 성능을 보입니다.
- 사례
- Kukar et al. (2016) ㅣ 대퇴골 경부 골절 회복의 예후를 예측할 때 다른 분류 모델에 비해 더 높은 성능을 보인 것으로 확인되었습니다.
- Formulation
 Formulations of the Naive bayes 2
Formulations of the Naive bayes 2
Deep Learning
신경망 Neural Netrwork, NN
- 신경망은 딥러닝의 기초이며 뉴런(Neuron)으로 구성되며, 각 뉴런은 활성화 함수(Activation Function), 가중치(Weight), 편향(Bias) 파라미터로 구성됩니다.
- 역전파(Backpropagation) 알고리즘을 통해 뉴런의 가중치를 미세 조정합니다.
- 경사 하강법(Gradient Descent)를 사용하여 Cost function을 최소화 하는 방향으로 모델을 최적화합니다.
합성곱 신경망 Convolutional Neural Network, CNN
- 합성곱(Convolution) Layer, Pooling Layer, Fully-connected Layer로 구성됩니다.
- 주로 이미지 데이터를 입력으로 하여 복잡한 Feature map을 학습하며 정보 영역 선택, 특징 추출, 분류 등의 작업을 수행합니다.
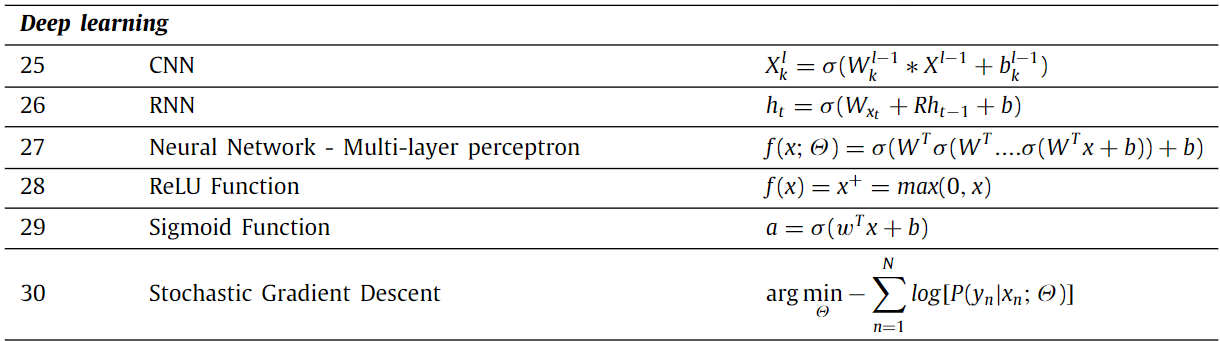 Formulations of the deep learning models 2
Formulations of the deep learning models 2
Learning
Learning Problem
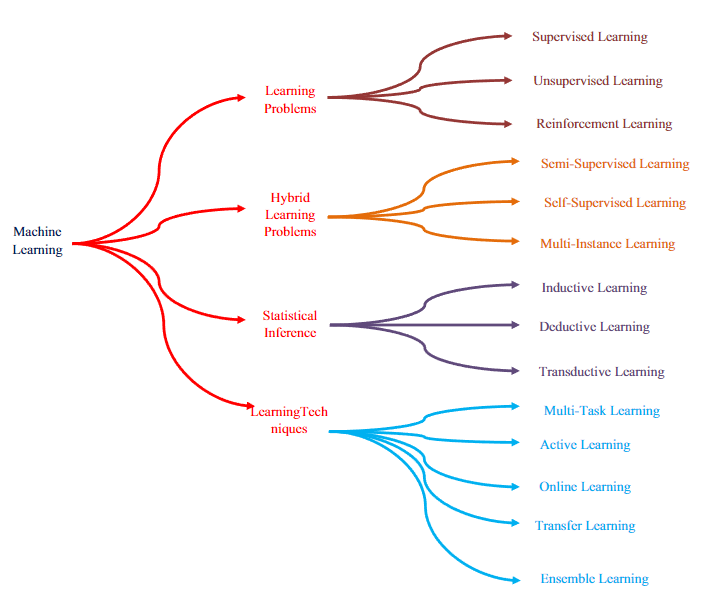 Types of learning 3
Types of learning 3
지도학습 Supervised Learning
- 지도학습은 모델이 입력 데이터와 목표 변수 사이의 관계를 학습하는 문제이며, 클래스 라벨을 예측하는 분류(Classification) 문제와 수치 라벨을 예측해야 하는 회귀(Regression) 문제로 나뉩니다.
비지도학습 Unsupervised Learning
- 비지도학습은 입력 데이터만 사용하고 출력 또는 정답 변수 없이 학습하는 방식입니다.
- 군집화(Clustering)은 데이터를 그룹화하며 밀도 추정(Density Estimation)은 데이터 분포를 요약합니다.
- 시각화를 통해 패턴, 추세, 관계를 시각적으로 강조할 수 있으며, 투영(Projection)을 통해 고차원 데이터를 저차원 데이터로 변환할 수 있습니다.
강화학습 Reinforcement Learning
- 강화학습은 특정 맥락에서 작업을 수행하기 위해 피드백을 학습해야 하는 일련의 과제입니다.
- 피드백을 통해 작업을 개선하지만 피드백이 지연될 수 있어 인과 관계를 파악하기 어려운 특성이 있습니다.
- Deep Reinforcement Learning ㅣ 기존 강화 학습에 신경망을 결합한 방식입니다.
- Q-learning ㅣ 에이전트가 상태와 행동의 Q-값(품질)을 학습해 최적의 행동을 선택하는 방법입니다.
- Temporal Difference Leanring ㅣ 에이전트가 상태와 행동의 Q-값(품질)을 학습해 최적의 행동을 선택하는 방법입니다.
Hybrid Learning Problem
반지도학습 Semi-supervised Learning
- 일부 데이터만 라벨링 되어 있고, 나머지 다수의 데이터는 라벨이 없는 상태로 학습하는 방법입니다.
- 라벨 유무와 상관없이 모든 사용 가능한 데이터를 효율적으로 활용하여 모델을 개선하는 방식입니다.
- 이는 완전히 라벨이 있는 데이터만 사용하는 전통적인 지도 학습과 차별화됩니다.
자기 지도학습 Self-supervised Learning
- 라벨이 없는 데이터를 활용하여 문맥 예측 및 이미지 회전 예측과 같은 목표 과제를 자율적으로 계산하는 방식입니다.
- Autoencoder를 통해 입력 데이터를 압축-복원하여 특징을 학습할 수 있으며, GAN을 활용하면 합성 이미지를 생성할 수 있습니다.
다중 인스턴스 학습 Multi-instance Learning
- 한 그룹의 데이터 전체가 특정 클래스의 데이터를 포함하거나 포함하지 않는 것으로 라벨링되며, 그룹 내 개별 데이터들은 라벨링되지 않습니다.
- 개별 데이터 포인트에 대한 정보가 아닌, 그룹 전체에 대한 정보를 중심으로 이미지가 특정 객체를 포함하는지 여부를 학습합니다.
통계적 추론 Statistical Inference
- 추론(Inference)은 모델을 통해 데이터로부터 예측/결론을 도출하는 과정입니다.
- 모델의 특정 알고리즘이 어떻게 작동하는지 또는 학습 문제를 어떻게 해결하는지를 설명하는 추론 패러다임은 아래와 같이 다양합니다.
귀납 학습 Inductive Learning
- 결과를 평가하기 위해 증거를 사용하는 학습 방식으로, 구체적인 상황에서 일반적인 결과를 도출하는 방식입니다.
- 귀납 추론(Inductive Reasoning) ㅣ 과거의 특정 사례를 통해 일반적인 규칙(모델)을 학습하며, 가용한 증거를 이용해 결과를 도출합니다.
- 여러 번의 데이터 (사례)를 통해 일반적인 패턴이나 규칙 (모델)을 추출합니다.
- 구체적인 예시를 바탕으로 학습 데이터셋에서 모델 또는 가설을 만들며, 이 모델은 알려지지 않은 데이터에 대해 예측을 수행하는 데 사용됩니다.
연역 학습 Deinductive Learning
- 일반 개념을 사용해 구체적인 결과를 평가하는 방법이며, Induction과 반대의 개념입니다.
- 귀납(Induction) ㅣ 구체적인 사례에서 일반적인 결론을 도출하는 과정입니다. (Bottom-up)
- 연역(Deduction) ㅣ 일반적인 개념에서 구체적인 결론을 도출하는 과정입니다. (Top-down)
- 귀납(Induction) ㅣ 구체적인 사례에서 일반적인 결론을 도출하는 과정입니다. (Bottom-up)
- 연역 추론 (Deductive Reasoning) ㅣ 모든 전제를 충족시키고 결과를 결정하려는 방식입니다.
- 머신러닝에서 알고리즘을 사용하여 예측을 할 수 있으며, Induction을 사용하여 모델을 학습하기 전에 훈련 데이터셋에 맞도록 한다는 점에서 유사합니다.
- 이러한 모델은 Deductive method로 사용됩니다.
Transductive Learning
- 통계 학습 이론에서 특정 예제를 예측하는 과정으로, 일반적인 규칙을 학습하는 Induction과 달리 Transduction은 구체적인 예제를 바탕으로 예측하는 방식입니다.
- 적용 예시로는 함수의 특정 지점에서 값을 추정하는 모델을 들 수 있으며, 제한된 지식에서 최상의 결과를 도출하려는 경우에 활용됩니다.
- 대표 알고리즘으로는 k-NN (k-nearest Neighbors)가 있으며, 이는 예측이 필요할 때마다 직접 알고리즘을 사용하며 훈련 데이터로 모델링하지 않습니다.
Learning Techniques
- 아래는 모델 학습과정에서 활용될 수 있는 기법들입니다.
Multi-task Learning
- 서로 다른 작업의 세부 사항을 결합하여 일반화 성능을 향상시키는 기술입니다.
- 하나의 작업에 대한 라벨링된 데이터가 풍부할 때 유용하며, 해당 데이터를 라벨링된 데이터가 적은 또 다른 작업에 공유할 수 있습니다.
- 같은 입력 패턴이 여러 다른 출력 또는 지도 학습 문제에 사용할 수 있습니다.
- 각 출력은 모델의 다른 부분에 의해 예측되며, 동일한 입력을 각 작업에 대해 일반화할 수 있습니다.
Active Learning
- 모델이 학습 과정 중 사용자에게 질문을 던져 불확실성을 해결하려는 방법론입니다.
- 수동적인 기존의 지도 학습보다 더 효율적인 데이터를 사용하면서 동일하거나 더 나은 결과를 도출하는 것을 목표로 합니다.
- Central Principle ㅣ Active Learning 알고리즘이 학습할 데이터를 선택하게 하여, 적은 학습 레이블로 더 높은 정확도를 달성할 수 있습니다.
- Active Learner는 질문을 던지며, 이는 주로 라벨이 없는 정보 인스턴스로 나타나고 이를 Oracle(Human Annotator)이 라벨을 붙입니다.
- 데이터가 적고 라벨링 비용이 많이 들 때 유용하며, Domain Sampling을 조정하여 샘플 수를 줄이는 동시에 모델의 효율성을 높입니다.
Online Learning
- 머신러닝은 주로 오프라인에서 수행되며, 이는 일정한 데이터 배치에서 학습한다는 의미입니다.
- Data Stream이 있을 경우, 새로운 데이터 포인트가 도착할 때마다 추정치를 업데이트해야 하므로 온라인 학습이 필요합니다.
- 이는 시간이 지남에 따라 데이터가 빠르게 변화할 때 유용하며, 데이터셋이 점진적으로 증가하는 경우에도 유용합니다.
- 일반적으로 온라인 학습은 모델 성능이 모든 지식을 일괄적으로 사용 가능했을 때와 얼마나 잘 수행되는지를 비교하여 불일치를 제거하는 것을 목표로 합니다.
- Online Gradient Descent ㅣ 주로 Stochastic Gradient Descent를 사용하며, 이는 일반화 오류를 최소화하는 것이 명확히 드러납니다.
Transfer Learning
- 기존 작업을 해결하면서 학습한 모델을 다른 새 작업 문제 해결에 사용하는 방법입니다.
- 주된 작업과 유사한 과정이 있을 때 효과적이며, 데이터가 많이 필요한 관련 작업에서 유용합니다.
- Multi-task Learning과 달리 Transfer Learning은 작업을 순차적으로 학습하며, Multi-task Learning은 하나의 모델이 동시에 여러 작업에서 좋은 성능을 내도록 학습합니다.
- 큰 작업에서 학습한 패턴 추출 기능이 또 다른 작업에 도움이 됩니다.
Ensemble Learning
- 두 개 이상의 모델을 결합하여 예측 성능을 향상시키는 방법으로, 개별 모델보다 더 나은 성능을 달성하는 것을 목표로 합니다.
- 불확실성을 줄이고 예측 능력을 향상시키기 위한 중요한 방법입니다.
- 주요 방법
- Bootstrap ㅣ 샘플링을 통해 여러 데이터셋을 만든 후 개별 모델을 학습합니다.
- Weighted Average: ㅣ 각각의 모델 예측에 가중치를 부여하여 최종 예측을 도출합니다.
- Stacking(Stacked Speculation) ㅣ 여러 모델의 예측 결과를 다시 입력값으로 사용하는 메타 모델을 학습합니다.
- 계산 방법
- Bagging ㅣ 다수의 데이터 서브셋을 이용해 다수의 모델을 학습하고, 개별 모델의 예측을 평균 계산하여 최종 예측을 도출합니다.
- Boosting ㅣ 예측 오류를 줄이기 위해 순차적으로 모델을 학습하고, 각 모델이 이전 모델의 오류를 보정합니다.
Task Definition in Medical Imaging
분류 Classification
- Image Classification는 주로 질병/암 진단과 같은 이진 분류에 대한 것이며, 의료 데이터의 경우 보통 일반 컴퓨터 비전 데이터 셋의 양보다 적기 때문에 (~수백/수천), Transfer learning 기법을 활용해 데이터 셋이 부족하다는 문제를 해결할 수 있습니다.
- Classification Task에서는 주로 특징 추출(Feature Engineering) 및 미세 조정(Fine-tuning) 이 많이 활용되며 최근에는 특히 CNN을 기반으로한 여러 연구들이 진행되고 있습니다.
- ex. Fine-tuned Google Inception-v3, 3D CNN, Graph-based CNN
- Object/Lesion Classification
- 객체나 병변을 분류하는 Task이며 CT의 결절 분류와 같이 소규모 영역에 대한 분류를 예로 들 수 있습니다.
- 정확한 분류를 위해 Local 정보와 전체적인 Context 정보를 필요로 합니다.
- ex. Multi-stream Architecture, Multi-scale 이미지를 결합한 특징 벡터, CNN-RNN, 3D Information Integration, End-to-end Training, RBMs, SAEs, CSAEs, Multiple Instance Learning (MIL).
- Exam Classification
- 진단 검사 사진을 질병 유무 또는 정상/비정상으로 분류하는 작업입니다.
- 사전 학습된 CNN이 주로 활용됩니다.
- Essential Terminology
- Binary Classification, Multi-class Classification, Multi-label Classification
Detection
- Manual Detection은 환자에게 심각한 결과를 초래할 수 있는 여러 문제를 겪고 있어, 이러한 문제를 최소화 하기 위해 자동 감지가 필요해졌습니다.
- Detection Task는 주로 장기, 병변 및 랜드마크 위치를 지정해주는데 쓰이며, 특히 3D 데이터 파싱을 위해 다양한 접근 방식이 제안되고 있습니다.
- ex. 3D 영역을 2D 직교 평면의 조합으로 처리함, 3개의 독립적인 2D MRI 슬라이스로 원거리 대퇴 표면의 랜드마크 식별, 2D CT 볼륨 파싱 후 3D 경계 상자를 식별하여 심장, 대동맥 궁, 하행 대동맥 근처의 ROI 식별.
- 객체 또는 병변 탐지는 의료 진단 영역의 주요 부분이며, 임상의에게 많은 시간을 소모하게 합니다.
- AI를 통해 이미지 내 작은 병변의 위치를 지정하고 식별하는 것으로 해결합니다.
- 대부분의 탐지 시스템은 CNN을 사용하여 픽셀을 분류 후 후처리를 수행하며, 문맥적 또는 3D 정보를 포함하기에 Multi-stream CNN을 사용합니다.
- 또한, 학습 데이터 생성 부담을 줄이기 위해 Weakly Supervised Learning을 활용할 수 있습니다.
False Positive Detection
- False Positive(FP)는 정상이지만 비정상으로 간주되는 픽셀로, CAD 시스템의 민감도를 줄이면서 잘못된 의료적 개입을 야기합니다.
- 기존에는 FP를 감소시키기위해 통계 분석을 기반으로하나 후처리 필터를 활용하거나 수동적인 방법을 사용하였지만, 딥러닝을 통해 이를 개선할 수 있습니다.
- CNN으로 다양한 뷰와 스케일의 2D 슬라이스를 학습하여 FP와 TP를 구분합니다.
Segmentation
- Segmentation Task는 장기 및 하위 구조를 분할하여 부피 및 형태와 관련된 임상 파라미터의 정량적 분석을 가능하게 합니다.
- 주요 접근법은 객체의 윤곽 또는 내부를 구성하는 폭셀(Voxel)을 식별하는 것이고 일반적으로 U-net, V-net, RNN 등이 활용될 수 있습니다.
- 3D 이미지를 직접적으로 처리하여 2D 이미지에 비해 더 정확한 Segmentation을 가능케 하는 3D CNN-based Segmentation 기법이 있습니다.
- Efficient Dense Training Scheme ㅣ 전체 이미지를 사용하는 대신 인접한 이미지 패치를 사용하여 학습합니다.
- Deeper and More Discriminative 3D-CNNs
- Dual Pathway Architecture: 여러 스케일에서 병렬로 처리.
- Pereira et al. ㅣ 작은 CNN Kernel을 활용하여 글리오마 (가장 공격적인 뇌종양)를 분할했습니다.
- Avendi et al. ㅣ 딥러닝 구조를 결합한 심장 좌심실 분할을 통해 임상 평가에 중요한 지표를 제공했습니다.
Registration
- 정합(Registration)은 한 의료영상을 다른 의료영상에 공간적으로 맞추는 과정이며, 일반적으로 두 영상을 비교하여 유사도를 계산하고 이를 최적화하여 정합을 수행합니다.
- 여러 이미지 데이터를 하나의 일치된 좌표 시스템으로 변환하고, 중요한 의료적 함의가 있는 일치된 이미징 내용을 생성합니다.
- 동일한 항목 (MRI와 CT스캔) 또는 다른 시간 및 위치에서 촬영된 두 스캔이미지 정렬을 위한 좌표 찾기에 활용할 수 있습니다.
- 주로 Deep Regression Networks와 Deep Learning Networks를 사용합니다.
- Wu et al. (2013) ㅣ 독립적 공간 분석과 CNN을 결합하여 HAMMER 정합 알고리즘을 보강했습니다.
- Simonovsky et al. (2016) ㅣ 서로 다른 모달리티의 패치들 사이의 유사도 비용 추정했습니다.
- Cheng et al. (2015) ㅣ CT와 MRI 이미지 패치의 유사도 평가를 위한 오토인코더를 사용했습니다.
- 변환 파라미터 예측을 위해 딥러닝을 활용하여 입력 이미지로부터 바로 변환 파라미터를 예측할 수 있습니다.
- Miao et al. (2016) ㅣ CNN을 활용하여 3D 모델과 2D X-ray 정합을 수행하여 수술 중 임플란트 객체의 위치와 자세를 평가했습니다.
- Yang et al. (2016) ㅣ U-net과 같은 아키텍처를 사용하여 LDDMM 기법의 현재와 이전 뇌 MRI 정합을 수행했습니다.
- ANT나 Simple ITK와 같은 툴을 활용할 수 있습니다.
Localization
- 2D 및 3D 공간, 그리고 시간(4D)에서 장기나 다른 기관의 위치를 인식합니다.
- ConvNet을 사용하여 관심 부위의 해부학적 구조를 3D 의료 이미지에서 자동으로 Localization합니다.
- 수동 및 자동으로 지정된 중심점과 Bounding Box의 거리를 계산하여 분석합니다.
- 이미지를 얻는 과정의 차이, 구조적 차이, 환자 간의 병리 차이 등 때문에 딥러닝 네트워크가 변동에 민감할 수 있습니다.
Content-based Image Retrieval
- Content-based Image Retrieval(CBIR)은 방대한 데이터베이스에서 지식 발견을 위한 기술입니다.
- 유사한 사례 기록 식별, 희귀 장애 이해, 환자 치료 개선을 위해 수행됩니다.
- 주로 픽셀 수준 정보에서 효과적인 특징 표현 추출하거나, 이를 의미 있는 개념과 연관시키기 위해 활용됩니다.
- 현재 접근법은 (사전 학습된) CNN을 사용해 의료 영상에서 Feature Descriptor 추출하는 것입니다.
- Anavi et al. (2016), Liu et al. (2016) ㅣ X-ray 이미지 데이터베이스를 대상으로 CNN을 사용하고 Fully-connected Layers에서 특징을 추출했습니다.
- Anavi et al. (2016) ㅣ 마지막 레이어와 사전 학습된 네트워크 사용하여, 특징을 One-vs-all SVM 분류기에 피드해 Distance Metric을 얻었습니다.
- Shah et al. (2016) ㅣ CNN Feature Descriptor와 해싱-포레스트 사용하고, 1000개의 특징을 중첩 패치로부터 추출했습니다.
Image Generation and Enhancement
- 이미지 생성 및 향상 기법은 장애 요소 제거, 이미지 정규화, 이미지 품질 향상, 데이터 완성, 패턴 발견 등의 사례에 활용될 수 있습니다.
- 주로 2D 또는 3D CNN를 사용하며 분류 네트워크에서 사용되는 Pooling Layer가 없고 입력 이미지와 원하는 출력이 모두 포함된 데이터셋으로 학습합니다.
- 손실함수는 생성된 이미지와 원하는 출력 간의 차이로 정의됩니다.
- Yang et al. (2016) ㅣ 일반 X-ray와 Bone-suppressed X-ray를 생성했습니다.
- Bahrami et al. (2016) ㅣ 3T와 7T 뇌 MRI를 생성했습니다.
- Li et al. (2014) ㅣ MRI로부터 PET를 생성했습니다.
- Nie et al. (2016) ㅣ MRI로부터 CT를 생성했습니다.
- 다중 저해상도 입력에서 고해상도 이미지 생성하는 목적으로도 활용됩니다.
- Oktay et al. (2016) ㅣ 다중 저해상도 입력 MRI에서 고해상도 심장 MRI를 생성했습니다.
- Golkov et al. (2016) ㅣ 제한된 데이터로부터 고급 MRI 확산 매개 변수 추론했습니다.
- 이미지 향상에도 응용될 수 있습니다.
- Janowczyk et al. (2016) ㅣ H&E 염색된 조직 병리학 이미지를 정규화했습니다.
- Benou et al. (2016) ㅣ DCE-MRI에서 노이즈를 제거했습니다.
Text Report
- 주로 리포트를 텍스트 라벨로 사용하여 텍스트 설명과 이미지를 같이 학습하여, 테스트 시에는 의미있는 클래스 라벨 예측을 가능케 합니다.
- Schlegl et al. (2015) ㅣ 리포트를 활용한 이미지 분류 정확도를 개선했습니다.
- Kisilev et al. (2016) ㅣ 유방 병변에 대해 BI-RADS 기술어를 예측했습니다.
- Shin et al. (2015, 2016) ㅣ PACS 시스템에서 추출한 대규모 데이터 세트의 방사선 보고서 및 이미지 간의 의미적 상호작용을 추출했습니다.
- 잠재 디리클레 할당(LDA)
- Wang et al. (2016) ㅣ LDA를 사용했습니다.
- Shin et al. (2016) ㅣ CNN을 이용하여 이미지의 레이블을 한 번에 하나씩 생성하고, 이를 사용하여 RNN을 훈련시켜 MeSH 키워드 시퀀스를 생성했습니다.
Application Areas
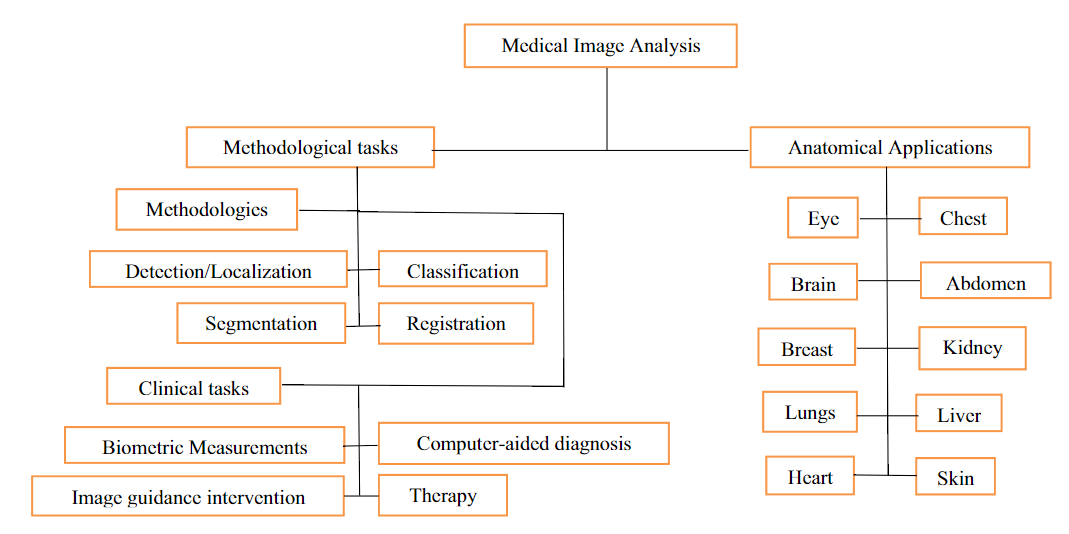 Medical Image Analysis 3
Medical Image Analysis 3
Chest
- 흉부 영상 분석의 주요 응용 분야는 다음과 같습니다.
- 결절 탐지 및 분류 ㅣ 결절의 탐지, 특성화, 및 분류가 흉부 영상 분석에서 가장 일반적으로 다루어지는 응용 분야입니다.
- 기존 시스템에 추가된 딥러닝 특징 ㅣ 많은 연구가 딥러닝에서 도출된 특징을 기존의 특징 집합에 추가하거나 비교하는 형태입니다.
- 흉부 X-선 ㅣ 여러 그룹이 단일 시스템으로 여러 질병을 탐지합니다.
- CT 스캔 ㅣ 간질성 폐 질환을 나타내는 질감 패턴의 탐지도 일반적인 연구 주제입니다.
- 텍스트와 이미지 분석 결합 연구들이 대규모 이미지와 텍스트 보고서를 사용하여 이미지 분석을 위한 CNN과 텍스트 분석을 위한 RNN을 결합한 시스템을 학습합니다.
- 폐 질환은 100개 이상의 만성 질환으로 구성되며, 폐 조직의 염증으로 특징지을 수 있습니다.
- 전통적인 진단은 환자 인터뷰, 신체 검사, X선 또는 CT 스캔으로 이루어지며, 이는 잘못된 진단을 야기할 수 있습니다.
- CT 슬라이드를 통해 패치 이미지를 생성하고 VGG 및 Alexnet을 활용하여 약 86% 정도의 폐 질환 분류 정확도 성능을 달성했습니다.
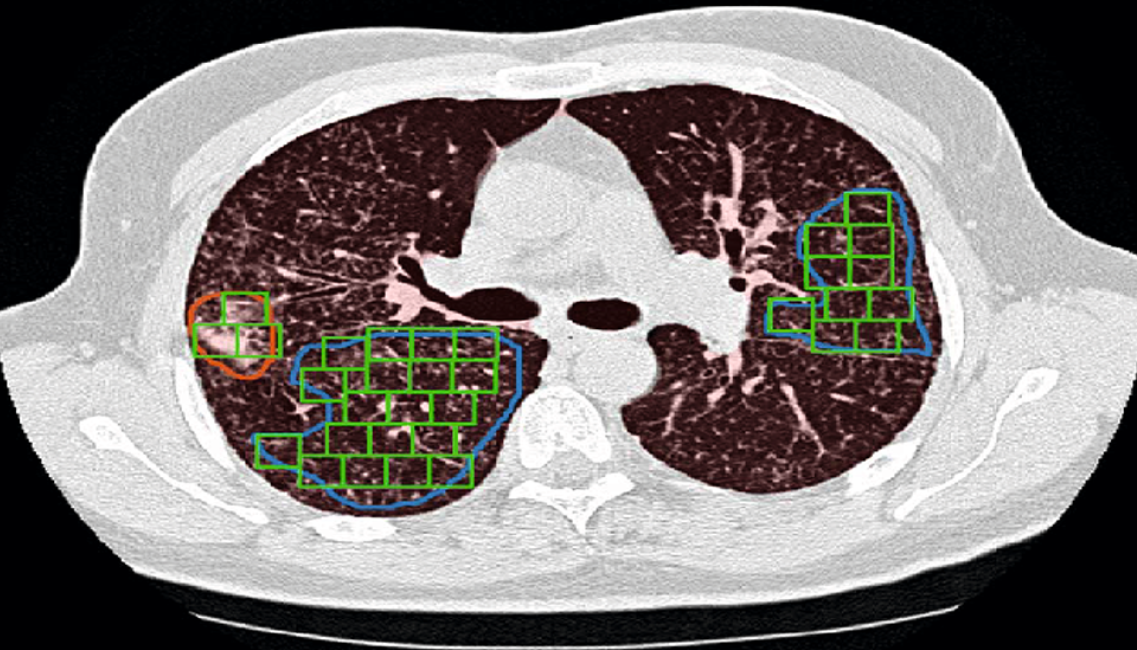 Generating image patches from one CT slide 4, 5
Generating image patches from one CT slide 4, 5
Brain
- 뇌 영상 분석에서 딥러닝을 활용하여 알츠하이머병(Alzheimer’s Disease, AD) 분류, 뇌 조직 및 해부학적 구조의 세분화, 병변 감지 등을 수행하고 있습니다.
- 뇌 이미지에서 추출된 특성을 분류하여 해부학적 뇌 구조 변화를 모니터링합니다. (뇌실 크기, 모양, 조직 두께, 뇌 부피)
- 3D-CNN을 활용하여 AD 바이오마커를 인식하고 학습한 일반화 특징을 통해 AD를 예측하고 해부학적 모양 변화를 감지합니다.
- Multi-modal RBM을 통해 MRI와 PET 이미지의 High-level Hidden Feature을 찾고, 3D 패치에서 특징을 추출하여 다층 RBM으로 분류합니다.
- AD 분류에서 RBM이 CNN보다 뛰어난 성능을 보여준다는 연구 결과가 있습니다.
- 로컬 패치를 활용하는 학습 기법은 로컬 패치에서 Representation으로, Representation에서 라벨로의 매핑을 학습합니다.
- Ghafoorian et al. (2016) ㅣ 로컬 패치가 해부학적 맥락 정보를 놓칠 수 있기에, 패치 측면에서 샘플링 비율을 점진적으로 낮춰 더 넓은 맥락을 포괄합니다.
- 또 다른 접근법은 Multi-scale 분석 및 Fully-connected Layer에서의 표현 융합 기술입니다.
- 뇌 종양을 분할하기위해 딥러닝 기반 Segmentation 모델이 활용됩니다.
- 종양 패치 이미지를 통해 Two-pathway 또는 Cascaded 구조 기반 CNN을 학습하여 비종양, 괴사, 부종, 증강 종양 등으로 세분화됩니다.
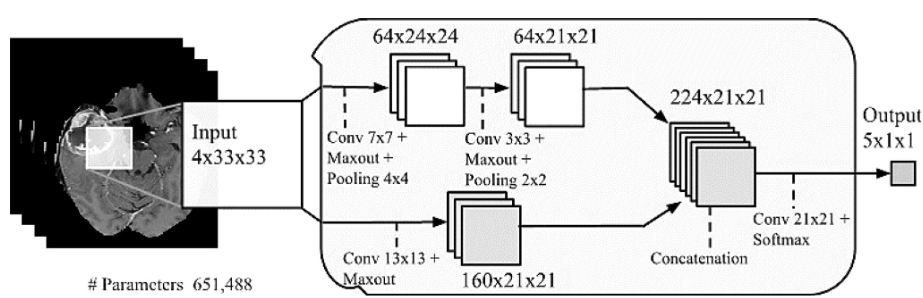 Two pathways and cascaded architectures 4, 6
Two pathways and cascaded architectures 4, 6
- 대부분의 방법은 2D에서 3D 볼륨을 슬라이스로 분석하는 방식이며, 이는 계산 요구 사항 감소 또는 데이터셋 내 평면 해상도에 비해 두꺼운 슬라이스를 원인으로 볼 수 있습니다.
- 최근에는 3D 네트워크를 사용하는 연구도 증가하는 추세입니다.
- 대다수 연구는 뇌 MRI 영상을 중점적으로 다루고 있으며, CT 및 초음파와 같은 다른 뇌 영상 모달리티 또한 딥러닝 분석에서 혜택을 받을 것으로 예상됩니다.
Pathology and Microscopy
- 주요 도전과제
- 핵 탐지, 세분화 및 분류
- 대형 기관 세분화
- 병변 또는 전체 슬라이드 이미지 수준에서 질병 탐지 및 분류
- 색상 정규화
- 사례 ㅣ 조직병리학(Histopathology)
- Janowczyk et al. (2016) ㅣ H&E 염색 이미지를 대상으로한 Stain Normalization를 위한 Deep Sparse AE 기법을 소개했습니다.
- Sethi et al. (2016) ㅣ CNN 기반 조직 분류에 색상 정규화의 중요성을 강조했습니다.
- 유방암 병리 이미지 분석에 DeepMitosis라고 불리는 CNN기반의 TP/FP에 대한 확률 점수를 추정한 연구가 진행됐습니다.
Breast
- 대부분의 Breast Imaging 기술이 2차원이므로 기존의 이미지 기술을 쉽게 적용할 수 있습니다.
- 주로 종양 같은 병변의 검출 및 분류, 미세 석회화의 검출 및 분류, 유방암 위험 점수 계산 등이 있습니다.
- Modality ㅣ 유방조영술이 가장 일반적으로 사용됩니다.
- Tomosynthesis, 초음파(US), 전단파 탄성 측정 기법 등의 연구는 아직 부족한 실정입니다.
- 유방 MRI에 대한 연구는 거의 없습니다.
- Modality ㅣ 유방조영술이 가장 일반적으로 사용됩니다.
- 유방암 대규모 공개 디지털 데이터베이스 부재로 인해, 오래된 필름 데이터셋이 많이 사용됩니다.
- 적은 데이터셋 문제는 Semi-supervised Learning, Self-supervised Learning, Weakly Supervised Learning 등으로 해결하려고 합니다.
- 유방 촬영술 이미지 분석(Mammogram Image Analysis)은 유방암 조기 발견을 위한 가장 안전한 방법이며, CAD 시스템에서 CNN을 활용한 유방 병변 감지, 분할, 분류 등의 자동화 과정을 거칩니다.
Cardiac
- 심장 이미지 분석(Cardiac Image Analysis)에는 주로 MRI가 많이 쓰이며, 좌심실 분할(Left Ventricle Segmentation) 같은 작업이 주로 활용됩니다.
- Segmentation, Tracking, Slice Classification, Image Quality Assessment, Super-resolution
- Automated Calcium Scoring(자동 칼슘 점수화), Coronary Centerline Tracking(관상 동맥 중심선 추적)
- 대부분의 논문에서 단순한 2D CNN을 사용하여 3D 또는 4D 데이터를 슬라이스 별로 분석합니다.
- DBN(Deep Belief Networks)이 많이 활용되었으며 주로 특징 추출에 사용됩니다.
- Poudel et al. (2016) ㅣ U-net 아키텍처 내에 순환 연결(Recurrent Connection)을 도입하여 좌심실을 슬라이스 별로 분할하고, 이전 슬라이스의 정보를 기억하여 다음 슬라이스 분할에 활용했습니다.
- Kong et al. (2016) ㅣ 표준 2D CNN과 LSTM을 결합하여 Temporal Regression를 수행하고, 특정 프레임과 심장 시퀀스를 식별했습니다.
Musculoskeletal
- Segmentation ㅣ 근골격계(Musculoskeletal) 이미지를 분석하여 뼈, 관절 및 관련 연조직의 이상 여부를 분할합니다.
- Detection ㅣ 관절과 뼈의 세부 구조, 그리고 이상 유무를 식별합니다.
- MRI, CT, X-ray, 초음파 등의 다양한 이미징 기법을 활용함.
- Jamaludin et al. (2016) ㅣ 12,000개의 척추 디스크 데이터를 사용해 시스템을 학습했습니다.
Other
- 피부병 진단(Dermoscopic Image Analysis)
- 딥러닝의 급격한 성능 향상으로 기존에 어려운 영역으로 알려졌던 피부암 진단에 대한 자동화 수요가 증가하고 있습니다.
- Esteva et al. (2017) ㅣ Google’s Inception-v3 모델을 이용하여, 보통 사진과 Dermoscopic 이미지로 학습했습니다.
- 제안된 시스템이 30명의 피부과 전문의와 동일한 수준의 성능을 보였습니다.
- 초창기 연구는 Pre-trained CNN을 특징 추출기로 사용했으나, 최근 연구는 완전한 End-to-end로 학습된 CNN을 기반으로 합니다.
- 이러한 CNN은 기존의 수작업 특징 기반 머신러닝 방법을 대체하고, 의료영상 해석에서의 표준적인 접근 방식으로 자리잡고 있습니다.
Discussion
- 기술적 확산
- 딥러닝이 의료 영상 분석의 모든 측면에 빠르게 확산되고 있으며, 242개 논문이 2016년 또는 2017년 초에 출판되었습니다.
- 다양한 딥러닝 아키텍처가 사용되고 있습니다.
- 초기 연구
- 초기 연구에서는 사전 학습된 CNN을 특징 추출기로 사용하였으며, 이러한 모델은 오픈소스로 다운로드 후 바로 의료 이미지에 적용할 수 있습니다.
- 기존 손수 설계된 Feature 기반 기계 학습 시스템을 쉽게 확장할 수 있습니다.
- 최신 연구 동향
- End-to-end로 학습된 CNN이 의료 영상 해석에서 선호되는 접근법이 되었습니다.
- 전통적인 Hand-crafted 기계 학습 방법을 대체하였으며, 이는 현재 표준적인 관행입니다.
- 성공적인 딥러닝 방법의 핵심 요소
- 특정 작업과 응용 분야에 대한 완벽한 딥러닝 방법과 아키텍처를 도출하기는 어렵습니다.
- CNN이 대부분의 의료 영상 분석 대회에서 최고 성능 제공하지만 정확한 아키텍처가 좋은 솔루션을 제공하는 가장 중요한 결정 요인은 아닙니다.
- 전문 지식의 중요성
- 과제 해결에 대한 전문 지식을 활용하는 것이 단순히 CNN에 레이어를 추가하는 것보다 더 많은 이점을 제공합니다.
- 성공적인 연구 그룹은 딥러닝 네트워크 외부의 새로운 데이터 전처리 또는 증강 기술에서 차별화를 보였습니다.
- ex. CAMELYON16 챌린지에서 염색 정규화 전처리 단계 추가로 성능이 크게 향상했습니다. (AUC 0.92에서 0.99로)
- 데이터 증강 전략이 네트워크의 견고성을 향상시키는 데 필수적입니다.
- 특화된 모델 구조 디자인
- 고유한 작업 특정 특성을 통합하는 아키텍처 설계가 단순한 CNN보다 더 나은 결과를 제공합니다.
- 여러 뷰를 활용한 네트워크와 다중 스케일 네트워크 등이 이러한 예시에 포함됩니다.
- 미래 가능성
- 비지도 학습 ㅣ 매우 큰 규모의 라벨이 없는 데이터를 사용할 수 있습니다.
- Variational Auto Encoder(VAE)
- 생성적 적대 신경망(GANs)
- 설명 가능성(Explainable AI, XAI) ㅣ ‘블랙 박스’로 설명되지 않는 딥러닝 문제를 해결하기 위한 다양한 기법들이 연구되고 있습니다.
- 역전파, Captioning 작업, Bayesian 통계와의 결합을 통해 신뢰할 수 없는 예측을 할 때 이를 파악하는 능력입니다.
- 주요 연구 성과
- Esteva et al. (2017), Gulshan et al. (2016) ㅣ 딥러닝을 활용한 이미지 분류에서 의학 전문가를 능가하는 경우도 있음을 보였습니다.
- 2D RGB 이미지 분류에 초점을 맞췄으며, 이는 기존 컴퓨터 비전 (ex. ImageNet) 과 유사한 작업입니다.
- ResNet 및 VGG-Net 과 같은 잘 연구된 네트워크 아키텍처를 사용할 수 있어 성능이 우수합니다.
- Esteva et al. (2017), Gulshan et al. (2016) ㅣ 딥러닝을 활용한 이미지 분류에서 의학 전문가를 능가하는 경우도 있음을 보였습니다.
Challenges
- 대규모 데이터셋 부족
- PACS 시스템 ㅣ 서양 병원의 방사선과에서 사용된 PACS 시스템은 수백만 장의 이미지를 저장하고 있어 데이터 양의 상당한 축적이 가능합니다.
- Labeling(Annotation) 어려움 ㅣ PACS 시스템은 방사선 의사가 작성한 자유 텍스트 보고서를 저장하고 있으나 이를 자동화된 방식으로 정확한 레이블로 전환하는 것은 매우 복잡합니다.
- 전문가가 직접 이미지를 라벨링하는 경우, 비용과 시간이 많이 소모됩니다.
- 단층 촬영 이미지 분할을 위해 3D 슬라이스별 주석을 달아야 하는 경우가 많으며, 이는 매우 많은 시간을 필요로 합니다.
- 라벨 노이즈 문제 ㅣ 라벨링된 데이터가 존재한다 해도, 도메인 전문가 간에 의견이 일치하지 않는 경우가 있습니다.
- LIDC-IDRI 데이터셋에서는 네 명의 방사선 의사가 독립적으로 단층 촬영 이미지를 주석 달았으나 완전히 일치하지 않는 단층 촬영 개수가 세 배는 더 많았습니다.
- 이진 분류의 한계 ㅣ 의료이미지에서는 정상 대 비정상, 객체 대 배경과 같은 이진 분류가 자주 사용됩니다.
- 그러나 이는 종종 비정상의 여러 하위 범주가 매우 드문 경우 이진 예측이 실패하게 됩니다.
- 클래스 불균형 ㅣ 특정 질병 이미지가 상대적으로 적은 경우, 클래스 불균형 문제가 발생합니다.
- 유방암 검사 프로그램은 대부분 정상 유방 촬영 이미지만을 보유하고 있다는 문제가 있습니다.
- 추가 정보 통합 ㅣ 의료진은 환자의 역사, 나이, 인구 통계 정보 등 이미지를 넘어 많은 데이터를 활용합니다.
- 이를 딥 러닝 네트워크에 통합하는 연구가 있지만, 아직 충분한 성능을 보이지 못했습니다.
- 의료 영상 분석의 도전 과제
- 3D 흑백이나 다중 채널 이미지와 같은 대부분의 의료 영상에서는 사전 훈련된 네트워크나 아키텍처가 존재하지 않아 새롭게 개발된 네트워크가 필요합니다.
- 의료 영상에는 비등방성 복셀 크기, 다양한 채널 간의 작은 등록 오류, 다양한 강도 범위와 같은 고유한 문제가 있습니다.
- 분류 문제로 제기할 수 없는 작업들도 종종 존재하며, 이 경우 비딥러닝 방법(Counting, Segmentation, Regression)으로 후처리가 필요합니다.
References
Litjens, Geert, et al. “A survey on deep learning in medical image analysis.” Medical image analysis 42 (2017): 60-88. ↩︎
Garg, Arunim, and Vijay Mago. “Role of machine learning in medical research: A survey.” Computer science review 40 (2021): 100370. ↩︎ ↩︎2 ↩︎3 ↩︎4 ↩︎5 ↩︎6 ↩︎7
uganyadevi, S., V. Seethalakshmi, and Krishnasamy Balasamy. “A review on deep learning in medical image analysis.” International Journal of Multimedia Information Retrieval 11.1 (2022): 19-38. ↩︎ ↩︎2
Abdou, Mohamed A. “Literature review: Efficient deep neural networks techniques for medical image analysis.” Neural Computing and Applications 34.8 (2022): 5791-5812. ↩︎ ↩︎2
Anthimopoulos, Marios, et al. “Lung pattern classification for interstitial lung diseases using a deep convolutional neural network.” IEEE transactions on medical imaging 35.5 (2016): 1207-1216. ↩︎
Havaei, Mohammad, et al. “Brain tumor segmentation with deep neural networks.” Medical image analysis 35 (2017): 18-31 ↩︎