MLOps 공부 시작해보기
♻️ MLOps의 정의와 전체 Workflow를 설명하고, MLOps에 대한 개발 원칙을 소개합니다.
MLOps 공부 시작해보기
KEYWORDS
MLOps란, MLOps 프레임워크, MLOps 파이프라인, MLOps 예시, MLOps 입문, MLOps, Machine Learning Operation
MLOps 정의
- MLOps는 머신러닝 및 데이터 과학을 DevOps에 포함시키기 위한 DevOps 방법론의 확장을 의미합니다.
- Machine Learning Engineering(MLE)
- 머신러닝 및 전통적 소프트웨어 엔지니어링의 과학적 원리, 도구, 기술을 사용하여 복잡한 컴퓨팅 시스템을 설계하고 구축하는 것입니다.
- 데이터 수집에서 모델 구축에 이르기까지 모든 단계를 포괄하여, 제품이나 소비자가 모델을 사용할 수 있도록 하는 것을 뜻합니다.
MLOps 역사
- 2000년대 초반에는 SAS, SPSS, FICO와 같은 공급업체의 라이선스 소프트웨어를 사용하여 머신러닝 솔루션을 구현했습니다.
- 오픈 소스 소프트웨어의 등장과 데이터의 가용성으로 Python 또는 R 을사용하여 머신러닝 모델을 학습하기 시작했습니다.
- 컨테이너화 기술이 등장하면서 Docker 컨테이너와 Kubernetes를 사용하여 확장 가능한 방식으로 모델을 배포하게 됩니다.
- 최근에는 이러한 솔루션이 모델 실험, 학습, 배포 및 모니터링의 전체 반복을 포괄하는 ML 배포 플랫폼으로 진화하고 있습니다.
 An evolution of the MLOps 1
An evolution of the MLOps 1
ML 프로젝트 설계하기
- How costly are wrong predictions?
- 문제는 무엇인가? 최종 사용자를 위해 어떤 목적으로 무엇을 하려고 하는가?
- 왜 중요한가?
- 최종 사용자는 누구인가?
- Machine Learning Canvas
- ML 프로젝트를 구조화하고 프로젝트를 실현하기 위한 핵심 요구 사항을 지정하는데 도움이 됩니다.
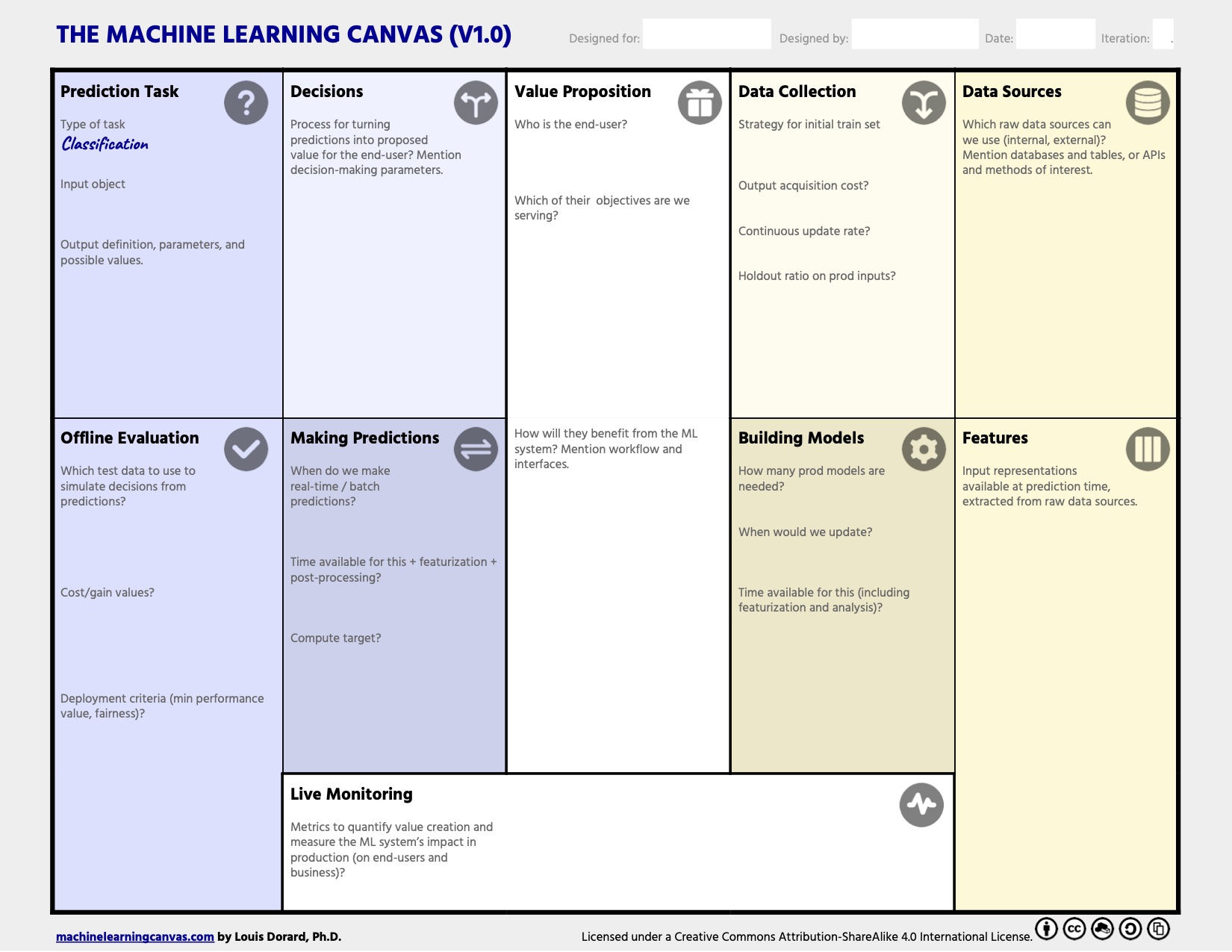 Machine Learning Canvas by Louis Dorard 1
Machine Learning Canvas by Louis Dorard 1
ML Workflow
- DevOps의 확장 기능인 MLOps는 ML 모델을 설계, 구축 및 Production에 배포하는 것과 관련된 효과적인 프로세스를 수립합니다.
1. Data Engineering + 2. ML Model Engineering + 3. Code Engineering
- 데이터 수집 및 데이터 준비
- ML 모델 학습 및 제공
- ML 모델을 최종 제품에 통합
1. Data Engineering
- 데이터 통합, 데이터 과학, 데이터 발견 및 분석, BI 사용 사례를 위해 원천 데이터를 탐색, 결합, 정리 및 큐레이팅 된 데이터 셋으로 변환하는 작업입니다.
- 리소스와 시간 측면에서 가장 비용이 많이 드는 단계입니다.
- 해당 과정의 데이터 오류는 다음 단계인 데이터 분석으로 전파되기 때문에 이를 방지하는 것이 중요합니다.
- 과정
- 데이터 수집 ㅣ Spark, HDFS, CSV 와 같은 프레임워크 형식을 통해 데이터를 수집함, 합성 데이터 생성 및 데이터 보강도 포함될 수 있습니다.
- 데이터 소스 식별: 데이터를 찾아 데이터 출처를 문서화
- 공간 추정 및 공간 위치 생성: 저장 공간 확인 및 충분한 보관 공간의 작업 공간 생성
- 데이터 수집 및 백업: 쉽게 조작가능한 형식으로 변환, 항상 데이터 사본으로 작업 후 원본은 손상되지 않도록 보관
- 개인 정보 보호 준수: 익명 처리
- 메타 데이터 카탈로그: 크기, 형식, 별칭, 마지막 수정 시간 및 액세스 제어 목록에 대한 기본 정보 문서화
- 테스트 데이터: 테스트 세트 샘플링, 데이터 스누핑 방지를 위한 열람 금지
- 탐색 및 검증 ㅣ 데이터 내용 및 구조에 대한 정보를 얻기 위한 데이터 프로파일링 과정입니다.
- 해당 단계의 출력은 값의 최대, 최소, 평균값과 같은 메타 데이터 집합입니다.
- 해당 검증을 통해 데이터 셋을 스캔하여 오류를 발견할 수 있습니다.
- RAD 도구 사용: Jupyter 노트북을 통한 EDA 및 실험 기록 보관
- 속성 프로파일링: 각 속성에 대한 메타 데이터 생성 (이름, 기록 수, 데이터 유형, 수치적 측정, 누락된 값, 분포 유형)
- 데이터 정리 ㅣ 특정 속성을 다시 포맷하고 누락된 값을 대체하는 등의 데이터 오류를 수정하는 과정입니다.
- 적용하고 싶은 변환 함수를 식별합니다.
- 이상치를 수정하거나 제거합니다.
- 누락된 값을 채우거나 행/열을 삭제합니다.
- 데이터 재구성: 열 이동을 통한 레코드 필드 생성, 레코드 필드 결합, 레코드 셋 제거를 통한 데이터 셋 필터링, 집계 및 피벗 활용
- 데이터 라벨링 ㅣ 각 데이터 포인트를 특정 카테고리에 할당 시키는 작업입니다.
- 데이터 분할 ㅣ ML 모델을 생성하는 핵심 머신 러닝 단계에서 사용할 수 있도록 데이터를 훈련, 검증, 테스트 데이터 셋으로 분할합니다..
- 데이터 수집 ㅣ Spark, HDFS, CSV 와 같은 프레임워크 형식을 통해 데이터를 수집함, 합성 데이터 생성 및 데이터 보강도 포함될 수 있습니다.
2. ML Model Engineering
- 머신러닝 알고리즘을 작성하고 실행하는 단계입니다.
- 과정
- 모델 학습 ㅣ ML 모델을 학습하기 위해 학습 데이터에 머신러닝 알고리즘을 적용하는 프로세스를 뜻합니다.
- Feature Engineering 과 Hyper-parameter Tuning 과정이 포함될 수 있습니다.
- 모델 엔지니어링은 반복적인 과정을 포함할 수 있으며 다음과 같은 Workflow를 포함합니다.
- 모든 ML 모델 정의 코드는 코드 검토를 거쳐 버전 관리 되어야합니다.
- 표준 매개변수를 사용하여 다양하고 많은 ML 모델을 학습합니다.
- 성능을 측정하고 비교하며 교차 검증을 통해 성능 측정의 평균과 편차를 계산합니다.
- ML 모델의 오류 유형을 분석하고, 가장 유망한 3~5개 모델을 택하여 앙상블 방법을 고려합니다.
- 모델 평가 ㅣ ML 모델을 Production에서 최종 사용자에게 제공하기 전, 훈련된 모델이 원래 명시된 목표를 충족하는지 확인하기 위해 검증하는 과정입니다.
- 모델 테스트 ㅣ Hold Backtest Dataset을 사용하여 최종 Model Acceptance Test를 수행합니다.
- 모델 패키징 ㅣ 최종 ML 모델을 비즈니스 애플리케이션에서 사용할 수 있도록 모델을 설명하는 특정 형식으로 내보냅니다.
- PMML, PFA, ONNX
- 모델 학습 ㅣ ML 모델을 학습하기 위해 학습 데이터에 머신러닝 알고리즘을 적용하는 프로세스를 뜻합니다.
ML Architecture Style
- 모델 학습
- 오프라인 학습 (배치/정적 학습) ㅣ 이미 수집된 데이터 셋으로 학습합니다.
- Production 환경에 배포 후, ML 모델은 재학습될 때까지 일정하게 유지됩니다.
- 온라인 학습 (동적 학습) ㅣ 모델은 새로운 데이터(데이터 스트림) 이 도착하면 정기적으로 재학습 됩니다.
- 오프라인 학습 (배치/정적 학습) ㅣ 이미 수집된 데이터 셋으로 학습합니다.
- 모델 예측
- 일괄 예측 ㅣ 배포된 ML 모델은 과거 입력 데이터를 기반으로 일련의 예측을 수행합니다.
- 실시간 예측 ㅣ 요청 시점에 사용 가능한 입력 데이터를 사용하여 실시간으로 예측을 생성합니다.
- 모델 학습
ML Model Architecture Patterns
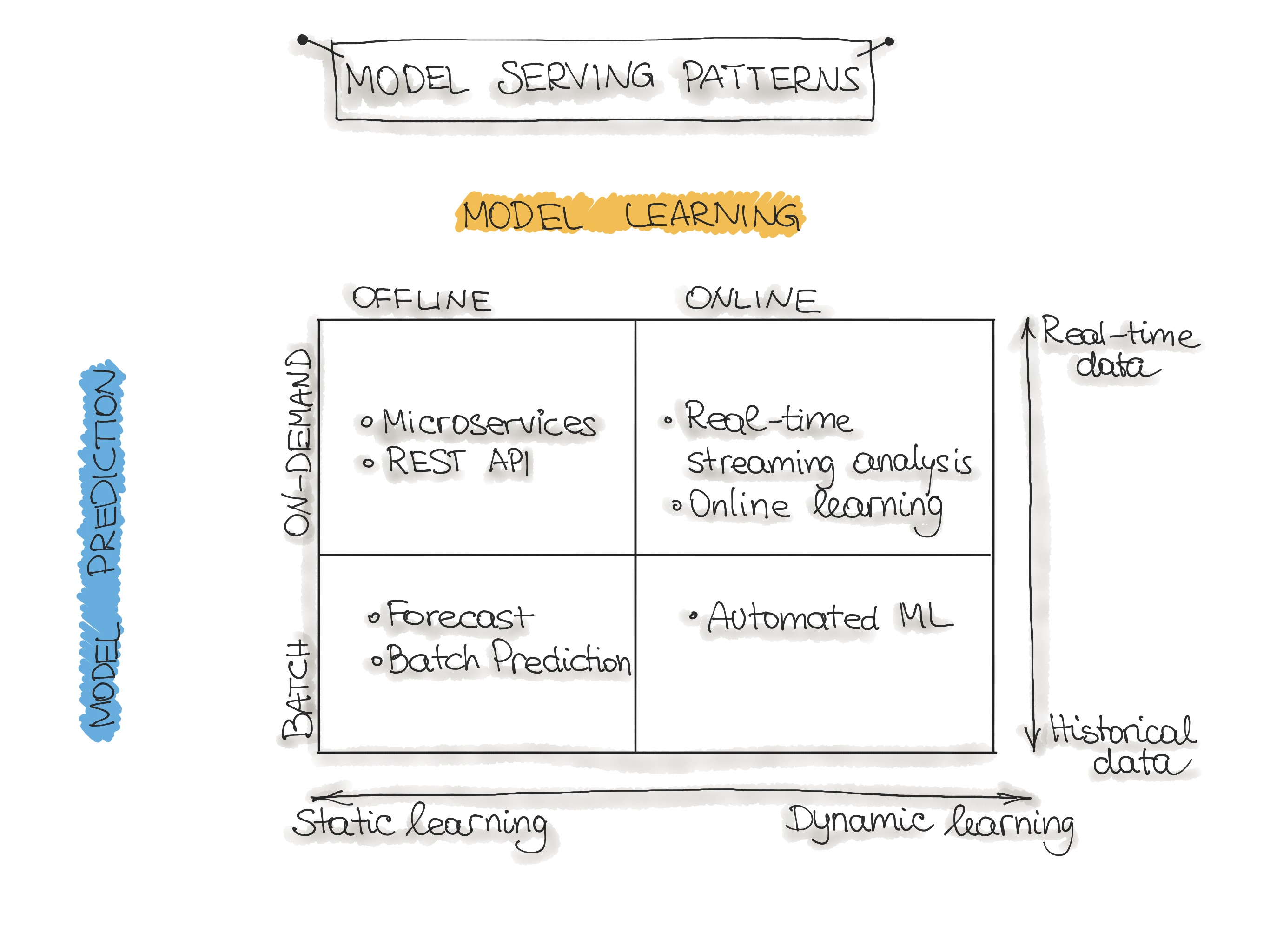 Model Serving Patterns 1
Model Serving Patterns 1
- Forecast
- 머신러닝 시스템을 만드는 가장 쉬운 방법이므로 학술 연구 및 실험에 사용됩니다.
- 일반적으로 사용 가능한 데이터 셋을 가져와 ML 모델을 학습한 후, 해당 모델을 다른 데이터에서 실행하면 ML 모델이 예측을 수행합니다.
- Production 시스템에는 일반적으로 부적합합니다.
- Micro Service
- 입력 데이터를 가져와 입력 데이터 포인트에 대한 예측을 출력합니다.
- 해당 모델은 과거 데이터에 대해 오프라인으로 학습되지만, 실시간 데이터를 사용하여 예측합니다.
- 예측(배치 예측)과의 차이점은 ML 모델이 거의 실시간으로 실행되고 모든 데이터들을 한 번에 처리하는 대신 한 번에 하나의 레코드를 처리한다는 것입니다.
- 마이크로서비스는 실시간 데이터를 사용하여 예측을 수행하지만 모델은 다시 학습되고 Production 시스템에 다시 배포될 때 까지 일정하게 유지됩니다.
- 학습된 모델을 배포 가능한 서비스로 래핑하기 위한 아키텍쳐
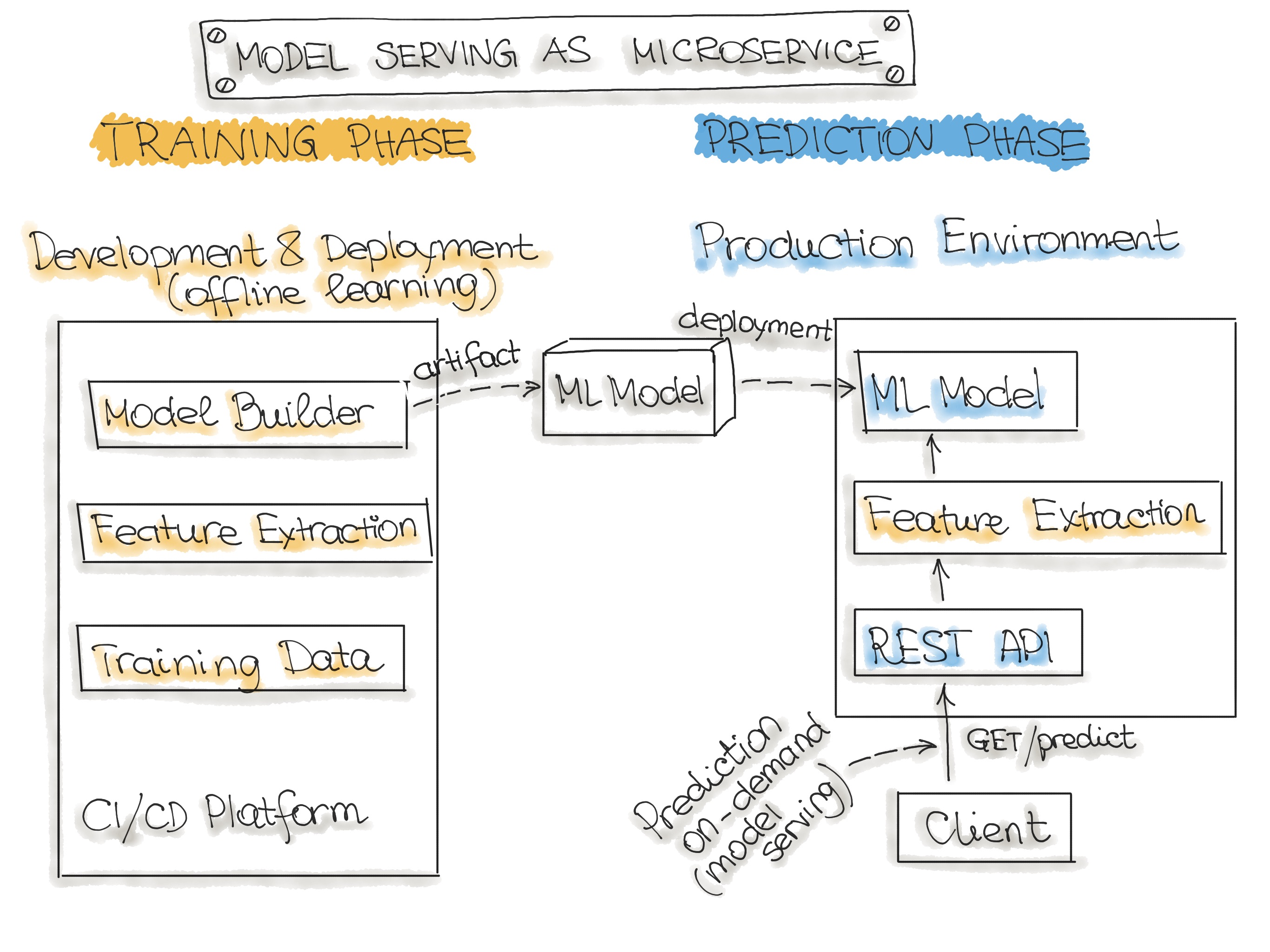 Model Serving Microservices 1
Model Serving Microservices 1
- Online Learning
- 실시간 스트리밍 분석, 증분 학습
- ML 학습 알고리즘은 단일 데이터 포인트 또는 미니 배치라고 하는 소규모 그룹으로 데이터 스트림을 지속적으로 수신합니다.
- 데이터가 도착하는 대로 즉시 학습하므로 ML 모델은 새 데이터로 점진적으로 재학습 되며 해당 모델은 마이크로서비스에 즉시 사용할 수 있습니다.
- 빅데이터 시스템의 람다 아키텍쳐와 잘 맞습니다.
- 일반적으로 입력 데이터는 이벤트 스트림이고, ML 모델은 시스템에 입력되는 데이터를 가져와 예측을 제공하고 이러한 새 데이터에 대해 다시 학습합니다.
- Kubernetes 클러스터 또는 이와 유사한 서비스에서 서비스로 실행됩니다.
- AutoML
- Online Learning의 정교한 버전이며, 자동화된 머신러닝을 뜻합니다.
- 모델을 업데이트 하는 대신, Production에서 전체 ML 모델 학습 파이프라인을 실행하여 즉석에서 새로운 모델을 생성합니다.
3. Code Engineering
- 학습이 끝난 머신러닝 모델을 모바일 및 데스크톱 애플리케이션과 같은 비즈니스 애플리케이션의 일부로 배포합니다.
- 과정
- 모델 Serving ㅣ Production 환경에서 ML Model Artifact를 처리합니다.
- 모델 성능 모니터링 ㅣ 이전에 보지 못한 데이터를 기반으로 ML 성능을 관찰하는 프로세스입니다.
- 이전 모델 성능과의 예측 편차와 같은 ML 특정 신호에 주목해야 합니다.
- 해당 신호를 모델 재학습의 Trigger로 활용할 수 있습니다.
- 이전 모델 성능과의 예측 편차와 같은 ML 특정 신호에 주목해야 합니다.
- 모델 성능 로깅 ㅣ 모든 추론 요청은 로그 레코드로 생성됩니다.
Model Serving Pattern
- ML 모델을 Production 환경에 통합하고 배포하는 방법입니다.
- 종류
- Model-as-Service
- ML 모델을 독립적인 서비스로 래핑합니다.
- 애플리케이션이 REST API나 gRPC를 통해 요청할 수 있습니다.
- Model-as-Dependency
- ML 모델을 패키징하여 소프트웨어 애플리케이션 내에서 종속성으로 사용합니다.
- 특정 메서드를 호출하여 예측 값을 가져올 수 있습니다.
- Precompute
- 사전 계산된 예측 결과를 데이터베이스에 저장합니다.
- 들어오는 데이터 배치에 대한 예측을 사전 계산하여 저장된 결과를 활용합니다.
- Model-on-Demand
- ML 모델이 필요할 때마다 사용 가능한 종속성으로 취급합니다.
- 메세지 브로커 아키텍처를 통해 예측 요청을 처리합니다.
- Hybrid-Serving
- 위의 여러 패턴을 조합하여 사용할 수 있는 방식입니다.
- Model-as-Service
배포 방식
- Docker 컨테이너화
- ML 모델을 Docker와 같은 컨테이너 기술을 사용하여 패키징합니다.
- 독립적으로 실행 가능한 환경에서 모델을 운영할 수 있습니다.
- 서버리스 함수 배포
- 클라우드 서비스(AWS, Google Cloud 등) 을 통해 ML 모델을 서버리스로 배포하는 방법을 설명합니다.
- 코드와 종속성을 하나의
.zip파일로 패키징하여 클라우드 함수로 쉽게 배포할 수 있습니다.
- ML 모델의 기능 제공
- REST API 형태로 기능을 제공하여 외부 애플리케이션이 모델의 예측 결과를 쉽게 사용할 수 있게합니다.
- 도커와 클라우드
- Kubernetes와 같은 오케스트레이션 도구를 사용하여 도커 컨테이너에서 ML 모델을 관리하고 배포할 수 있습니다.
ML Model Serialization Formats
- ML 모델 배포 시 활용가능한 형식입니다.
개발 언어에 독립적입니다.
- 종류
- Amalgamation
- ML 모델과 필요한 모든 코드를 하나의 패키지로 묶는 방법입니다.
- 독립 실행형 프로그램으로 컴파일 가능하며, SKompiler 같은 도구를 활용해 Scikit-learn 모델을 SQL 쿼리, Excel 수식 등으로 변환할 수 있습니다.
- 간단하고 이식성이 뛰어나며, 로지스틱 회귀와 같은 간단한 ML 알고리즘에 유리합니다.
- PMML Predictive Model Markup Language
- XML 기반의 모델 표현 형식 (
.pmml확장자) - 모든 ML 알고리즘을 지원하지 않으며, 일부 오픈 소스 툴에서는 사용 제한이 있습니다.
- XML 기반의 모델 표현 형식 (
- PFA Portable Format for Analytics
- PMML을 대체하기 위해 설계되었습니다.
- JSON 형식의 텍스트 문자열로 스코어링 엔진을 설명합니다.
- ONNX Open Neural Network eXchange
- ML 프레임워크와 무관한 파일 형식입니다.
- 다양한 대형 기술 회사에서 지원하며, ML 모델을 ONNX 형식으로 직렬화하면 여러 도구에서 사용할 수 있습니다.
- 대부분의 딥러닝 도구가 ONNX를 지원합니다.
- Amalgamation
MLOps 원칙
- MLOps는 기술 부채를 피하는 것을 목표로 하며, 이는 머신러닝 애플리케이션에서 발생할 수 있는 어려움을 최소화하려는 노력을 의미합니다.
- 최적의 MLOps 경험은 머신러닝 자산이 모든 소프트웨어 자산과 일관되게 처리되는 것이 라고 정의되며, 이는 CI/CD 환경 내에서 이루어집니다.
- MLOps를 통해 머신러닝 모델은 이를 감싸는 서비스 및 이를 소비하는 서비스와 함께 배포되어야 하며, 일관된 Release 프로세스의 일환으로 진행됩니다.
자동화 Automation
- 수동 프로세스 ㅣ 초기 머신러닝 구현 단계에서 데이터 과학자들이 수작업으로 진행하는 단계입니다.
- 주로 Jupyter Notebook과 같은 Rapid Application Development(RAD) 도구를 사용합니다.
- ML 파이프라인 자동화 ㅣ 모델 학습의 자동 실행을 포함하는 단계입니다.
- 새 데이터를 사용할 수 있을 때마다 모델 재학습 프로세스 자동화, 데이터 및 모델 검증 단계 포함
- CI/CD 파이프라인 자동화 ㅣ 생산 환경에서 ML 모델의 빠르고 신뢰할 수 있는 배포를 위한 단계입니다.
- 데이터, ML 모델, ML 교육 파이프라인 구성 요소를 자동으로 빌드, 테스트 및 배포
- MLOps 자동화 단계
- 개발 및 실험 ㅣ 파이프라인 소스 코드: 데이터 추출, 검증, 준비, 모델 훈련 및 테스트
- 파이프라인 지속적 통합 ㅣ 배포할 파이프라인 구성 요소: 패키지 및 실행 파일
- 파이프라인 지속적 배포 ㅣ 새로운 모델 구현이 포함된 배포된 파이프라인
- 자동 트리거링 ㅣ 모델이 모델 레지스트리에 저장된 훈련된 모델
- 모델 지속적 배포 ㅣ 예측 서비스를 위한 배포된 모델
- 모니터링 ㅣ 라이브 데이터의 모델 성능 데이터를 수집
- MLOps 구성 요소
- Source Control ㅣ 코드, 데이터 및 ML 모델 아티팩트의 버전 관리를 담당합니다.
- Test & Build Services ㅣ CI 도구를 사용하여 모든 ML 아티팩트의 품질을 보증하고 파이프라인을 위한 패키지와 실행 파일 빌드를 담당합니다.
- Deployment Services ㅣ CD 도구를 사용하여 파이프라인을 대상 환경에 배포합니다.
- Model Registry ㅣ 이미 훈련된 ML 모델을 저장하는 레지스트리입니다.
- Feature Store ㅣ 입력 데이터를 학습 파이프라인과 모델 서비스 동안 사용할 수 있는 Feature로 전처리합니다.
- ML Metadata Store ㅣ 모델 훈련의 메타 데이터를 추적합니다 (모델 이름, 파라미터, 훈련 데이터, 테스트 데이터 및 메트릭 결과).
- ML Pipeline Orchestrator ㅣ ML 실험의 단계를 자동화 합니다.
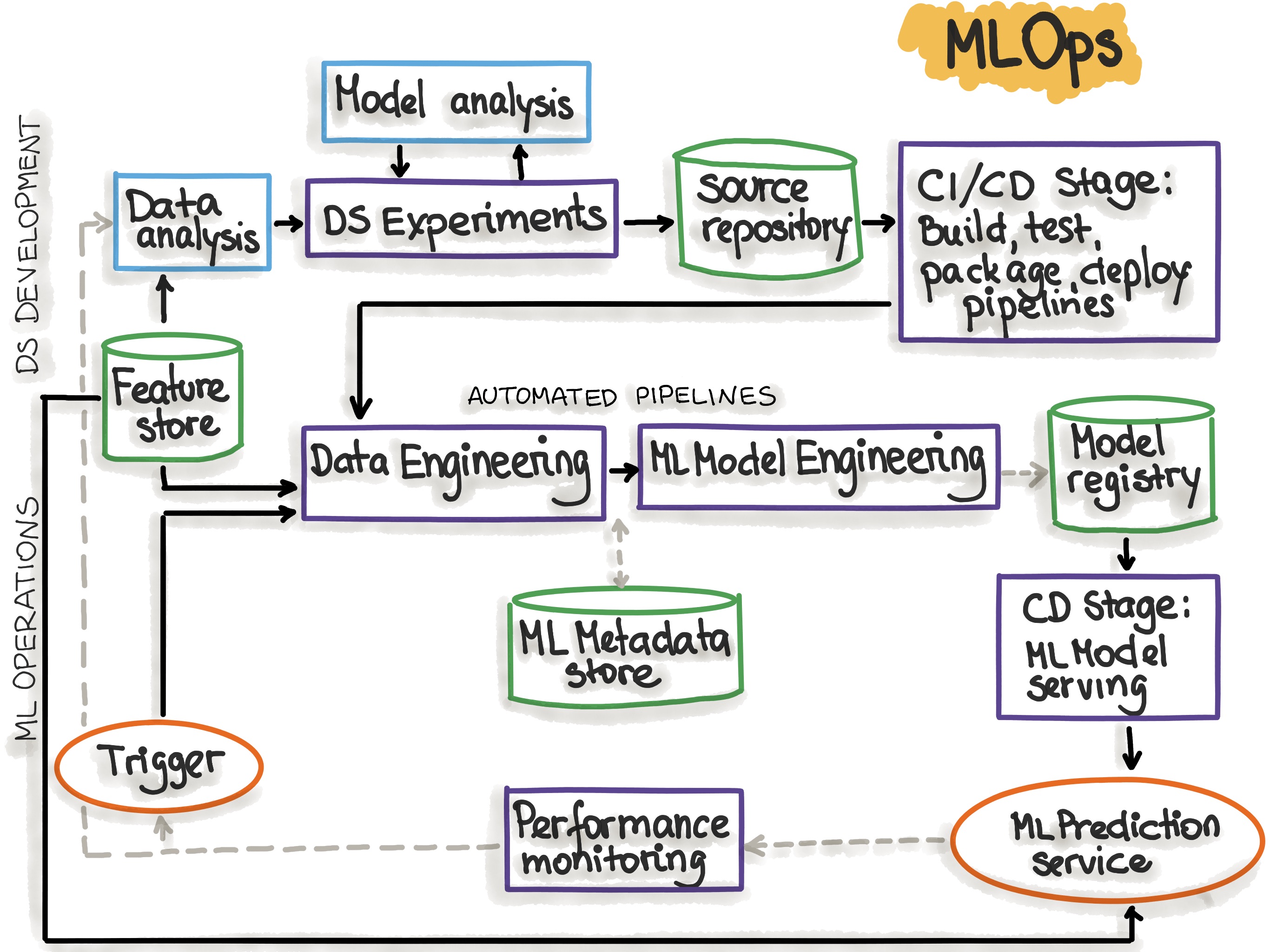 MLOps Phasen 1
MLOps Phasen 1
지속적 배포 Continuous Deployment
- ML Asset 정의 ㅣ ML 모델, 매개 변수 및 하이퍼파라미터, 학습 스크립트, 학습 및 테스트 데이터의 집합을 뜻합니다.
- ML 아티팩트의 식별 ㅣ 이러한 ML 아티팩트 구성 요소, 버전 관리 및 종속성을 파악하고 관리하는 것이 중요합니다.
- 배포 대상 ㅣ ML 아티팩트는 (마이크로) 서비스 또는 인프라 구성 요소와 같은 다양한 곳에 배포될 수 있습니다.
- 배포 서비스 기능
- Orchestration(서비스 간 작업 조정), Logging(이벤트 및 오류 기록), Monitoring(성능 및 상태 추적), Notification
- 배포 관행
- 지속적 통합 (CI) ㅣ 코드와 구성 요소의 테스트 및 검증을 데이터와 모델의 테스트 및 검증 추가로 확장합니다.
- 지속적 배포 (CD) ㅣ ML 학습 파이프라인의 배포 자동화를 통해 다른 ML 모델 예측 서비스를 자동으로 배포합니다.
- 지속적 학습 (CT) ㅣ ML 시스템의 고유 속성으로, ML 모델을 자동으로 재학습하여 다시 배포합니다.
- 지속적 모니터링 (CM) ㅣ 비즈니스 메트릭과 연결된 생산 데이터 및 모델 성과 메트릭을 모니터링 하는 것입니다.
버전 관리 Versioning
- 버전 관리의 목표는 ML 학습 스크립트, ML 모델, 데이터 셋 추적을 위함입니다.
- ML Asset을 버전 제어 시스템(VCS) 으로 관리하여 모든 ML 모델과 데이터를 버전으로 추적합니다.
- 모델 변경의 일반적인 이유
- 새 학습 데이터/방법을 기반으로 모델을 재학습
- 자가 학습이 가능한 모델
- 시간이 지남에 따른 성능 저하 발생 가능성
- 새 애플리케이션에 모델 배포 필요
- 공격을 받을 수 있어 모델 수정 필요, 이전 버전으로 신속한 롤백 가능
- 기업 또는 정부 규정 준수를 위해 모델 및 데이터에 대한 감사
- 데이터는 제한된 관할권에만 존재할 수 있음, 데이터 소유권 문제 가능성
실험 추적 Experimental Tracking
- ML 개발은 매우 반복적이며 연구 중심적인 과정이기에, 실험 추적이 필요합니다.
- 방법
- 다양한 브랜치 사용 ㅣ 각 실험마다 별도의 (Git) 브랜치를 사용하여 여러 실험을 추적합니다.
- 모델 결과 ㅣ 각각의 브랜치에서 학습된 모델이 생성되며, 선택된 메트릭에 따라 해당 모델들이 비교됩니다.
- 도구
- DVC Git의 확장으로 머신러닝 프로젝트를 위한 오픈 소스 버전 관리 시스템입니다.
- 실험을 낮은 충돌로 브랜칭 할 수 있도록 지원합니다.
- Weights and Biases (wandb) ㅣ 실험의 하이퍼파라미터와 메트릭을 자동으로 추적하는 라이브러리입니다.
- DVC Git의 확장으로 머신러닝 프로젝트를 위한 오픈 소스 버전 관리 시스템입니다.
테스트 Testing
- 모든 테스트는 모델이 Production 환경에 도달하기 전에 수행되어야 하며, 모델의 성능도 운영 환경에서 지속적으로 모니터링해야 합니다.
- 방법
- 피쳐 및 데이터 테스트
- 데이터 검증 ㅣ 자동으로 데이터와 특징의 스키마 및 도메인을 검사합니다.
- 피쳐 중요도 테스트 ㅣ 새로운 특징이 예측력을 더하는지 확인하기 위해 여러 검사를 수행합니다. (상관계수 계산, 모델 학습 등)
- 정책 준수 테스트 ㅣ 특징 및 데이터 파이프라인이 GDPR 등 정책을 준수하는지 확인합니다.
- 신뢰할 수 있는 모델 개발을 위한 테스트
- ML 알고리즘 훈련 검증 ㅣ 손실 지표와 비즈니스 영향 지표 간의 관계를 확인합니다.
- 모델 노후 테스트 ㅣ 모델이 최신 데이터를 포함하고 있는지 여부를 확인합니다.
- 모델 성과 검증 ㅣ 트레이닝 및 테스트 데이터 세트를 분리하여 질적 평가를 수행합니다.
- 공정성/편향/포용성 테스트 ㅣ 다양한 데이터 카테고리를 포함하여 편향을 조사합니다.
- ML 인프라 테스트
- 재현성 ㅣ 동일한 데이터로 훈련했을 때 동일한 모델이 생성되는지를 검증합니다.
- ML API 사용 테스트 ㅣ 스트레스 테스트 및 유닛 테스트로 API의 안정성을 검사합니다.
- 통합 테스트 ㅣ 전체 ML 파이프라인을 지속적으로 테스트하여 각 단계가 올바르게 진행되는지 확인합니다.
- 피쳐 및 데이터 테스트
모니터링 Monitoring
ML 모델이 배포된 후에는 모델이 기대하는 성능을 낼 수 있도록 지속적으로 모니터링해야 합니다.
모니터링 활동 체크리스트 2
- 종속성 변화 모니터링 ㅣ 전체 파이프라인에서 데이터 버전 변화, 소스 시스템 변화, 종속성 업그레이드 등을 알려줍니다.
- 데이터 불변성 모니터링 ㅣ 학습 단계에서 지정된 스키마와 일치하지 않는 데이터 발생 시 알려줍니다.
- 학습 및 서빙 특징의 일치 여부 확인 ㅣ 서로 다른 물리적 위치에서 생성된 특징들이 동일한지 확인합니다.
- 서빙 트래픽 샘플을 기록하여 통계(최소, 최대, 평균, 결측치 비율 등)를 계산합니다.
- 모델 수치 안정성 모니터링 ㅣ NaN이나 무한대 값 발생 시 알려줍니다.
- 컴퓨팅 성능 모니터링 ㅣ 성능 저하가 급격히 발생하거나 서서히 진행되는 경우 알려줍니다.
- GPU 메모리 사용량, 네트워크 트래픽, 디스크 사용량 등 시스템 사용 메트릭을 수집하여 클라우드 비용 추정에 유용합니다.
- 모델 낡음 모니터링 ㅣ 모델의 나이를 측정하고, 오래된 모델은 성능 저하 경향이 있습니다.
- 피처 생성 프로세스 모니터링 ㅣ 정기적으로 피처 생성을 다시 실행합니다.
- 예측 품질 저하 모니터링 ㅣ 예측 품질의 급격한 저하 또는 서서히 진행되는 성능 저하에 대한 알림을 줍니다.
- 예측의 통계적 편향을 측정하고, 라벨이 제공되는 경우 실시간으로 예측 품질 측정합니다.
- 모델 평가 지표 모니터링 ㅣ 모델의 정밀도, 재현율, F1 점수를 추적하는 모델 재학습 트리거의 역할을 합니다.
재현성 Reproducibility
- ML Workflow에서의 재현 가능성은 데이터 처리, 모델 학습, 모델 배포의 모든 단계가 동일한 입력을 가질 때 동일한 결과를 생성해야 함을 뜻합니다.
- 단계
- 데이터 수집 ㅣ 데이터를 항상 백업하기, 데이터 셋의 스냅샷을 저장하기 (클라우드 저장소 활용), 데이터 소스에 타임스탬프를 추가하기, 데이터 버전 관리 사용
- 피쳐 엔지니어링 ㅣ 피쳐 생성 코드는 버전 관리하에 두기, 데이터 수집 단계의 재현 가능성 요구
- 모델 학습 / 모델 빌드 ㅣ 피쳐 순서를 항상 동일하게 유지하기, 정규화와 같은 피쳐 변환을 문서화하고 자동화하기, 하이퍼파라미터 선택을 문서화하고 자동화 하기
- 모델 배포 ㅣ 소프트웨어 버전과 종속성이 실제 환경에서 일치해야 함, Docker와 같은 컨테이너 사용하기, 사양 문서화 하기, 학습/배포에 동일한 프로그래밍 언어 사용 하기
ML 수명 주기 ML Lifecycle
- 머신러닝 어플리케이션 개발을 위한 산업 간 표준 프로세스 (CRISP-ML(Q))
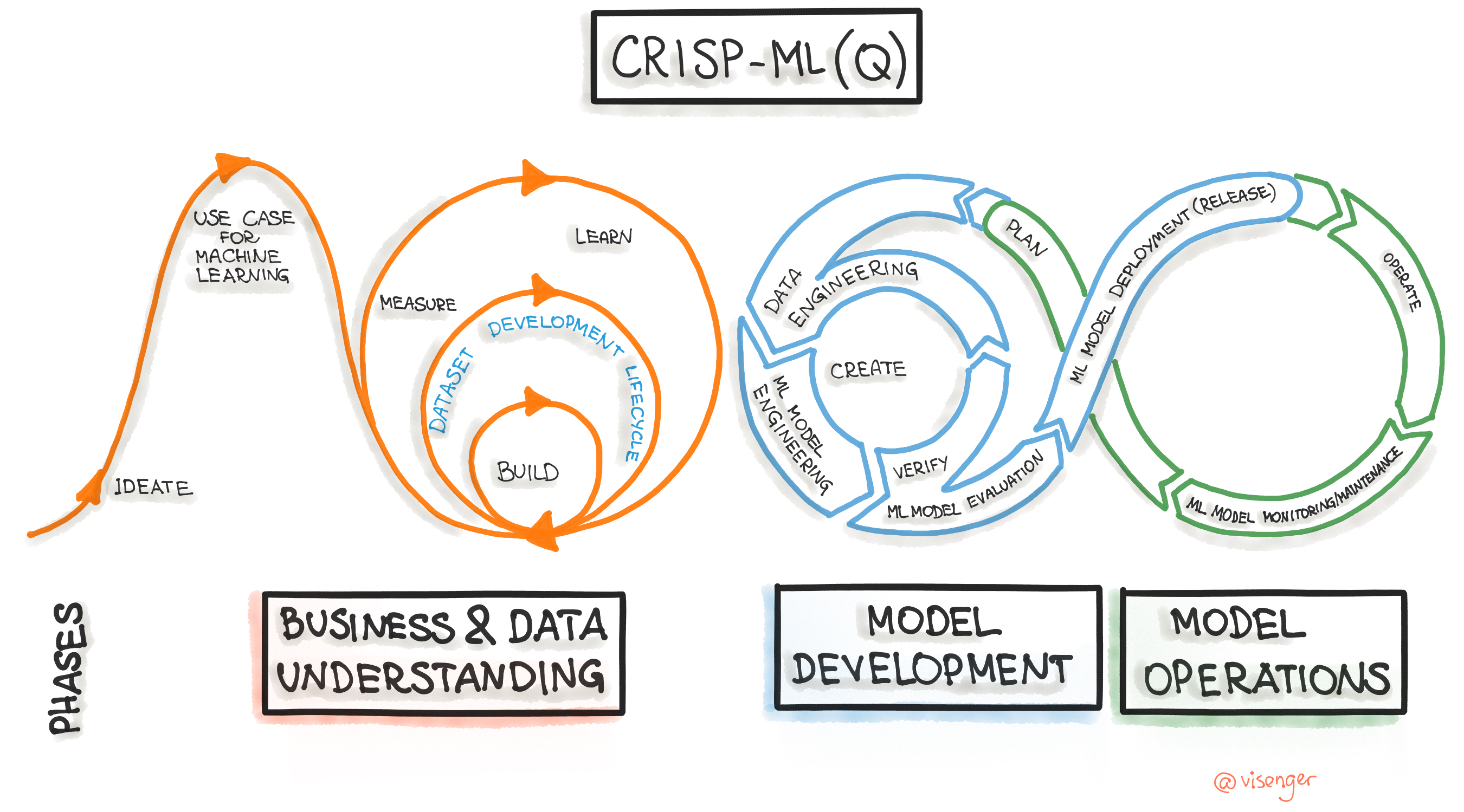 CRISP Machine Learning Process 1
CRISP Machine Learning Process 1
- 단계
- 비즈니스 및 데이터 이해
- ML 어플리케이션의 범위, 성공 기준 및 데이터 품질 검증을 식별하는 것, 프로젝트 실행 가능성을 보장
- 데이터 엔지니어링(데이터 준비)
- 데이터 선택, 정리, 피쳐 엔지니어링 및 데이터 표준화 작업
- 머신러닝 모델 엔지니어링
- Production에 배포할 하나 이상의 머신러닝 모델을 지정하는 것
- 머신러닝 어플리케이션을 위한 품질 보증(평가)
- 모델의 성능을 테스트 데이터에서 검증 함
- 배포
- 기존 소프트웨어 시스템에 ML 모델을 통합함
- 모니터링 및 유지관리
- 모델 성능 저하를 방지하기 위한 모델 성능 지속적 평가
- 비즈니스 및 데이터 이해
ML 거버넌스 Governance
ML 모델 거버넌스는 머신러닝 모델의 배포를 돕는 일련의 프로세스와 프레임워크를 포함하며, 법적 요구사항, 윤리적 기준, 품질 확보 등을 충족합니다.
과정
- 모델 저장/버전 관리
- 평가 및 설명가능성 ㅣ 모델 후보를 평가하기위해 쉐도우 배포 기법을 사용하여 성능을 비교합니다.
- 테스트 및 배포
- 보고서 작성 ㅣ 모델의 품질 보증을 위한 요약, 시각화 및 메트릭 강조를 포함하는 보고서를 작성합니다.
- 모델 레지스트리 ㅣ 모든 모델 버전을 저장하여 재현성과 책임을 보장합니다.
- 감사 ㅣ 모델 변경 사항은 모든 카테고리의 위험(사업, 재정, 법적)을 관리하기 위해 검토되고 승인되어야 합니다.
- 모니터링 ㅣ 모델 성능을 지속적으로 모니터링하고 관련 메트릭을 독립적으로 수집하여 보고합니다.
ML 모델 거버넌스와 규제
- EU는 AI에 대한 최초의 법적 프레임워크 초안을 발표했습니다.
- 허용 불가능한 위험 ㅣ 인간의 안전, 생계, 인권에 중대한 위험을 초래하는 AI 소프트웨어는 금지됩니다.
- 높은 위험 ㅣ 철저한 요구 사항이 적용됩니다(강건성, 보안, 정밀성, 문서와, 로그 기록, 위험 평가 및 완화).
- 제한된 위험 ㅣ 투명성 의무가 존재합니다.
- 최소 위험 ㅣ 규제가 없습니다.
- 해당 규제는 EU 내에서 AI 서비스를 제공하는 모든 기업에 적용되며, GDPR과 유사한 범위를 보여줍니다.
MLOps와 모델 거버넌스 통합
- 규제의 강도 측면
- 비즈니스 도메인, ML 모델 위험 범주, 비즈니스 위험에 의해 결정됩니다.
- EU의 새 규정은 높고 위험한 시스템에 적용될 수 있으며, 비 규제 분야에도 영향을 미칠 수 있습니다.
- AI 시스템의 비즈니스 성공에 대한 영향
- AI 시스템이 상업적 성공에 크게 의존하는 경우, 관리 요구 사항도 더 엄격합니다.
- 기업의 AI 모델 수에 따라 달라질 수 있으며, 모델 수가 적다면 ML이 비즈니스에서 덜 중요하거나 기업이 ML 구현에 필요한 역량이 부족하다는 것을 나타냅니다.
재현성과 검증
- 두 번 같은 결과를 얻을 수 있는 능력이며, 머신러닝에서도 실험 절차를 명확히 하여 재현성을 보장해야 합니다.
- 재현에 필요한 메타데이터
- 알고리즘 종류, 특징 및 변환, 데이터 스냅샷, 하이퍼파라미터, 성능 지표, 소스 코드 관리에서 검증 가능한 코드, 훈련 환경
- 문서화
- 프로젝트 문서화는 투명성과 추적 가능성을 높여 기술 부채를 줄여줍니다.
- 비즈니스 맥락 설명, 알고리즘의 고급 설명, 모델 파라미터, 특성 선택 및 정의, 모델 재현을 위한 지침, 알고리즘 훈련 및 예측의 예시
- Toolkits
- 데이터 시트 ㅣ 데이터 수집 방식이나 윤리적 검토 절차의 이행 여부를 기록합니다.
- 모델 카드 ㅣ 모델 개발 정보, 가정 및 다양한 그룹에서의 모델 행동 기대값 제공
- 검증(Validation)
- ML 모델 검증은 다단계 과정으로 다양한 지표를 사용합니다.
- 성능 지표(정확도, F1 Score) 및 비즈니스 지표(KPI) 를 사용하여 비교하고, 개선 여부를 확인합니다.
- A/B 테스트와 같은 통계적 유의성을 확인합니다.
- 재현성 여부 검사와 모델 설명 가능성 또한 중요합니다.
- 모델 배포 후, 거버넌스 프로세스가 배포 및 운영 단계와 통합되어야 합니다.
Conclusion
- MLOps는 효과적인 머신러닝 운영에 필수적인 개념입니다.
- MLOps에 입문하려면 기본적인 DevOps와 데이터 엔지니어링 지식을 공부하고 이를 실제 프로젝트에 적용해보는 것이 좋습니다.
- MLOps 공부를 시작할 때는 아래 ML Engineer 로드맵을 참고하면 도움이 됩니다.
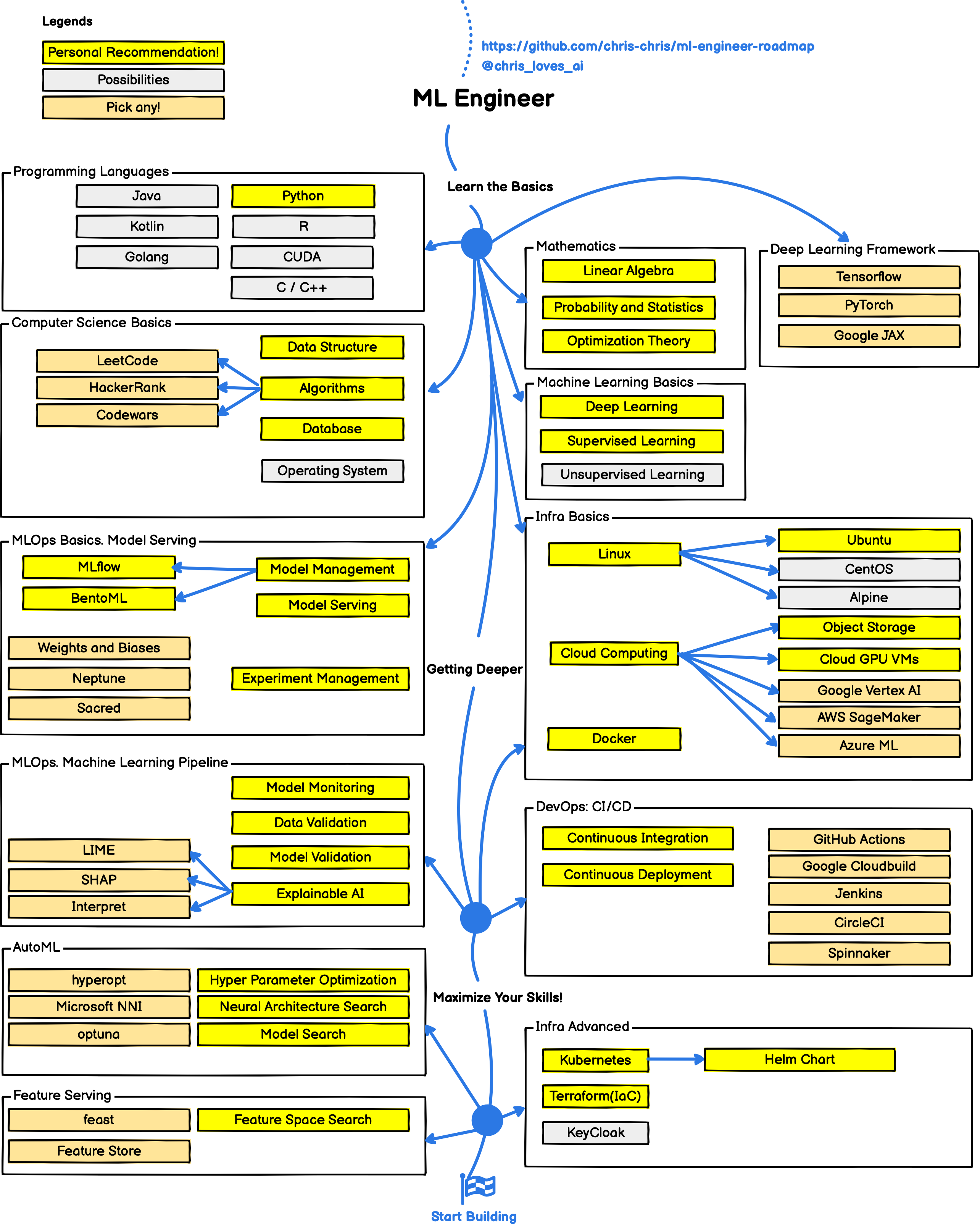 MLOps Engineer Roadmap 3
MLOps Engineer Roadmap 3
References
This post is licensed under CC BY 4.0 by the author.