RNN에 Attention 더하기 | Aaren
⏰ 순환 신경망(RNN)을 통해 Attention 알고리즘을 해석하고 개선하려는 논문을 소개하겠습니다.
KEYWORDS
Attention as an RNN, Attention, RNN, Aaren, Transformer, BPTT
Original Paper Review | Attention as an RNN
Introduction
- 시퀀스 모델링(Sequence Modeling)과 Transformer
- Transformer 모델은 시계열 데이터를 예측할 수 있는 시퀀스 모델링 구조를 가지지만, 추론(Inference) 단계에서 계산 비용이 높아 모바일과 같은 기기에서는 활용도가 낮습니다.
- 메모리와 계산 측면에서 이차적 확장성(Quadratic Scaling)을 가지므로, 자원 제한 환경(ex. 배터리 기반 디바이스)에서는 적합하지 않습니다.
- 토큰 갯수에 비례하는 선형 메모리가 필요하므로, 새 토큰 입력에 대해 효율적으로 출력을 업데이트할 수 없다는 한계가 있습니다.
- 모든 이전 시점의 토큰을 캐시해야 하며, 특히 컨텍스트가 긴 데이터에서
- 본 논문은 Attention 메커니즘을 효율적인 추론이 가능한 일종의 순환 신경망(Recurrent Neural Network, RNN)으로 설명합니다 1.
- Attention as RNN ㅣ Attention 알고리즘이 Many-to-one 출력을 효율적으로 처리하는 RNN 중 한 유형으로 해석될 수 있습니다.
- Transformers as RNN Variants ㅣ 기존 Transformer 모델도 RNN의 변형으로 해석될 수 있지만, 새로운 토큰에 대한 출력 업데이트에 한계가 있습니다.
- 새로운 Attention 계산 방법 ㅣ Parallel Prefix Scan 알고리즘을 활용하여 Attention 출력을 다대다 Many-to-many RNN 출력으로 계산할 수 있습니다.
- Aaren 모듈 ㅣ Transformer의 병렬 학습 이점을 유지하면서 RNN의 토큰 업데이트 능력을 가진 새로운 Attention 기반 모듈, Aaren을 소개합니다.
- Aaren
- Transformer처럼 병렬 학습이 가능합니다.
- 전통적인 RNN처럼 새로운 토큰으로도 효율적인 업데이트가 가능하며, 추론(Inference)
- Aaren은 강화 학습, 이벤트 예측, 시계열 분류 및 예측 등 네 가지 주요 Task의 38개 데이터셋에서 Transformer와 유사한 성능을 내면서도 추론 속도와 메모리 면에서 더 효율적임을 보였습니다.
Background
순환 신경망 Recurrent Neural Network, RNN
- RNN은 순차적인 시계열 데이터를 처리하기 위해 설계된 시퀀스 모델(Sequence Model)입니다.
- RNN은 Hidden State를 아래와 같이 반복적으로(재귀적으로) 계산합니다.
\(h_t = f_\theta(h_{t-1}, x_t),\)- where
- \(h_t\) ㅣ 시간 \(t\)에서의 Hidden State
- \(h_{t-1}\) ㅣ 이전 시간 단계에서의 Hidden State
- \(x_t\) ㅣ 시간 \(t\)에서의 입력 토큰(Input Token)
- \(f_\theta\) ㅣ 파라미터가 \(\theta\)인 신경망 함수
- where
- LSTM과 GRU는 일반적인 RNN 유형이며, 일정한 크기의 Hidden State를 유지하면서 메모리 효율적으로 추론을 할 수 있습니다.
- 하지만, 기존의 RNN은 본질적으로 반복적/재귀적 구조와 병렬 처리가 불가능하다는 단점이 있습니다.
 Many-to-many RNN
Many-to-many RNN
Attention 알고리즘
- Attention 알고리즘은 다양한 컨텍스트 토큰(Context Token)으로부터 특정 쿼리 토큰(Query Token)의 정보를 검색할 수 있게합니다.
\(\text{Attention}(Q, K, V) = \text{softmax}(QK^T)V,\)- where
- \(Q = X_QW_q\) ㅣ 쿼리 토큰에서 유도된 쿼리 행렬(Query Matrix)
- \(K = X_CW_k\) ㅣ 컨텍스트 토큰에서 유도된 키 행렬(Key Matrix)
- \(V = X_CW_v\) ㅣ 컨텍스트 토큰에서 유도된 값 행렬(Value Matrix)
- \(W_q, W_k, W_v \in \mathbb{R}^{d \times d}\) ㅣ 학습 가능한 가중치 행렬
- Softmax 함수는 내적 결과를 정규화하여 가중 평균을 계산합니다.
- where
- 특징
- Non-iterative 설계를 통해 GPU 병렬 처리에 유리합니다.
- Transformer는 Self-attention 알고리즘을 활용하여, 쿼리가 컨텍스트와 일치합니다.
- Performance Cost
- Attention은 토큰 수에 대한 2차 계산 비용(Quadratic Computation Cost)을 가지므로, 새로운 토큰이 추가됨에 따라 업데이트가 비효율적이게 됩니다.
Attention as RNN
- 본 논문은 어텐션 메커니즘을 특별한 형태의 순환 신경망(RNN)으로 볼 수 있다고 이야기합니다. 1.
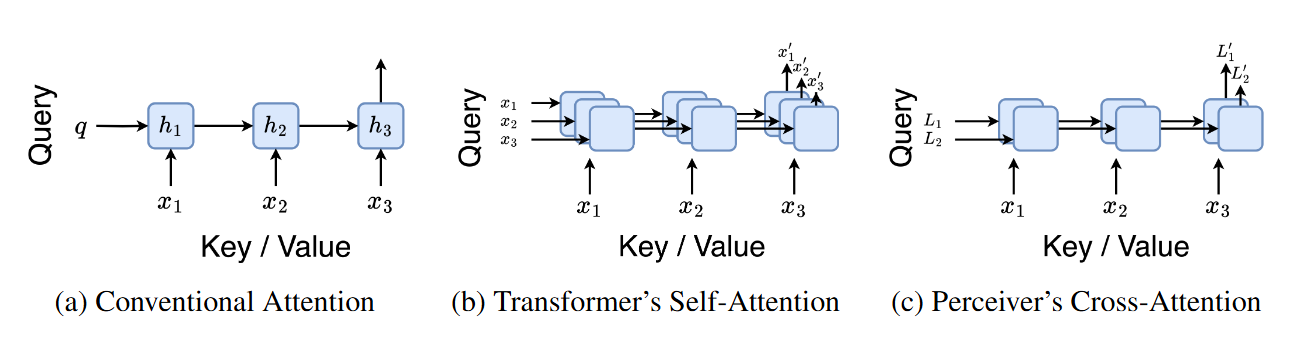
- \((a)\) 기존 Attention 계산 방법을 나타내며, Many-to-one RNN과 비슷합니다.
- 여러(Many) 컨텍스트 토큰을 처리하여 하나의(One) 최종 출력을 생성하는 방식입니다.
- \((b)\) 트랜스포머의 Self-attention 방법을 나타내며, 입력 토큰들이 RNN의 Initial Hidden State로 사용됩니다.
\((c)\) Perceiver의 Cross-attention을 보여주며, 컨텍스트에 의존적인 잠재 변수(Latent Variable)를 Initial Hidden State로 사용하여 RNN과의 연관성을 유지합니다.
- Attention의 효율성 활용하기
- Attention을 Many-to-many RNN으로 처리할 수 있는 새 방법을 제안합니다.
- 이는 Parallel Prefix Scan 알고리즘을 활용하여 새로운 토큰을 순차적으로 처리하면서도 계산 비용이 낮게 유지되도록 합니다.
- Aaren(Attention as a Recurrent Neural Network)
- Transformer처럼 병렬 학습이 가능합니다.
- 기존 RNN과 유사하게 추론 시 새로운 토큰을 효율적으로 업데이트하며, 일정한 메모리로 처리가 가능합니다
- 다양한 데이터와 Task에서 Transformer와 유사한 성능을 내면서도 시간과 메모리 측면에서 더 효율적일 것이라고 기대해볼 수 있습니다.
Attention as a (Many-to-one) RNN
Attention Mechanism
- Attention은 모델이 출력을 생성할 때, 입력의 중요한 부분에 집중(Attention)할 수 있게 해줍니다.
쿼리 벡터 \(q\)에 대하여, \(N\)개의 컨텍스트 토큰 \(x_1^N\)을 관련된 키 \(k_i\)와 값 \(v_i\)를 사용하여 처리합니다.
Output Formula
- Attention 출력 \(o_N\)은 아래와 같이 표현됩니다.
- where \(s_i = \text{dot}(q, k_i)\).
- 분자 ㅣ \(\hat{a}_N = \sum_{i=1}^{N} \exp(s_i) v_i\).
- 각각의 \(v_i\)에 점수의 지수를 곱하여 가중합을 계산합니다.
- 분모 ㅣ \(\hat{c}_N = \sum_{i=1}^{N} \exp(s_i)\).
- 가중치가 1이 되도록 정규화합니다.
- 분자 ㅣ \(\hat{a}_N = \sum_{i=1}^{N} \exp(s_i) v_i\).
- 재귀적(Recursive) 계산
- Attention은 Rolling Sum 방식으로 순차적으로 계산될 수 있습니다.
For \(k = 1, \ldots, N\),
\[\hat{a}_k = \hat{a}_{k-1} + \exp(s_k) v_k,\] \[\hat{c}_k = \hat{c}_{k-1} + \exp(s_k)\]
- 이 방법은 수치적으로 불안정할 수 있습니다.
- Attention은 Rolling Sum 방식으로 순차적으로 계산될 수 있습니다.
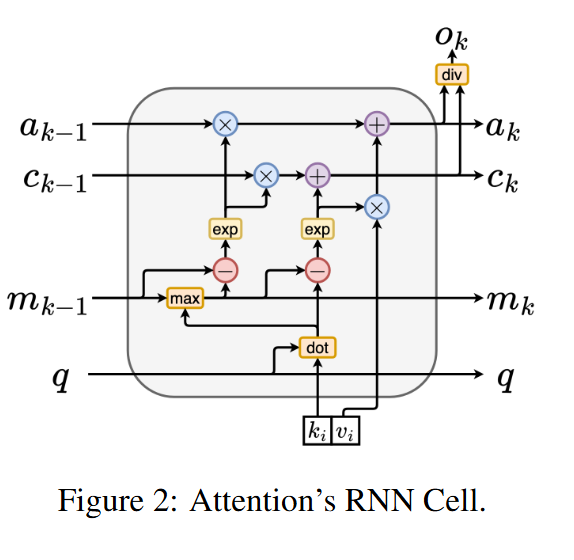
안정적인 방법
수치적 안정화를 위해, 누적 최댓값(Cumulative Maximum) \(m_k = \max_{i \in \{1, \ldots, k\}} s_i\)를 활용합니다.
\[a_k = \sum_{i=1}^{k} \exp(s_i - m_k) v_i\] \[c_k = \sum_{i=1}^{k} \exp(s_i - m_k)\]따라서, 업데이트 방식은 아래와 같습니다.
\[a_k = a_{k-1} \exp(m_{k-1} - m_k) + v_k \exp(s_k - m_k),\] \[c_k = c_{k-1} \exp(m_{k-1} - m_k) + \exp(s_k - m_k),\] \[m_k = \max(m_{k-1}, s_k).\]
Attention as RNN
- 각 RNN Cell은 Input과 Output을 계산합니다.
- Inputs ㅣ \((a_{k-1}, c_{k-1}, m_{k-1}, q)\)
- Outputs ㅣ \((a_k, c_k, m_k, q)\)
- Initial State는 \((a_0, c_0, m_0, q) = (0, 0, 0, q)\)로 설정됩니다.
- 각 RNN Cell은 Input과 Output을 계산합니다.
- 계산 방법
- Attention은 아래의 방식으로 실행됩니다.
- 순차적(Sequentially) ㅣ 토큰 별로 \(O(1)\) 메모리를 사용하여 처리합니다.
- 병렬적(In Parallel) ㅣ 전체 컨텍스트를 \(O(N)\) 메모리로 처리합니다.
- 블록 방식(Block-wise) ㅣ 토큰을 청크 단위로 \(O(b)\) 메모리로 처리합니다.
- Attention은 아래의 방식으로 실행됩니다.
- Transformer 기반의 기존 모델은 Attention 층이 순환 상태로 작동하는 RNN으로 이해해볼 수 있습니다.
- 이러한 관점은 RNN의 속성을 활용하여 효율적인 계산을 할 수 있게 합니다.
Attention as a (Many-to-many) RNN
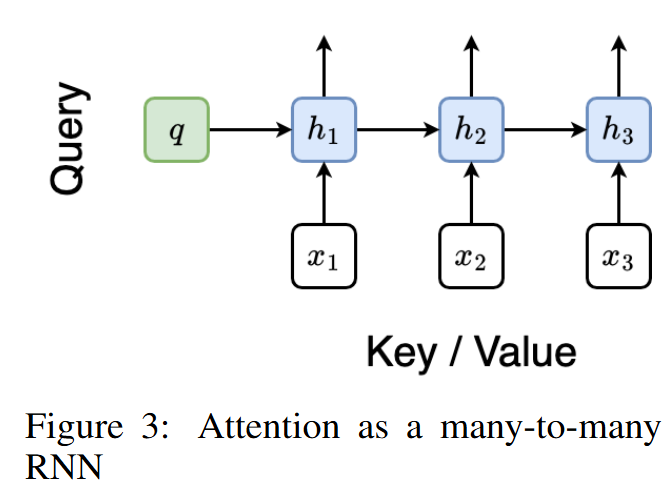
- Many-to-many RNN으로 Attention을 병렬적으로 계산하는 방법을 소개합니다.
- Associative Operator \(\oplus\)를 활용하여 Parallel Prefix Scan 알고리즘으로 \(N\)개의 Prefix 계산을 수행합니다.
Attention 출력의 계산은 아래와 같이 이루어집니다.
\[o_i = \text{Attention}(q, x_{1:i}) \quad \text{for } i = 1, \ldots, N.\] \[\text{Attention}(q, x_{1:k}) = o_k = a_k \cdot c_k,\]- where
- \[a_k = \sum_{i=1}^{k} \exp(s_i - m_k)v_i\]
- \(a_k\) ㅣ 컨텍스트 토큰의 중요도
- \(s_i\) ㅣ 쿼리 \(q\)와 키 \(k_i\)의 Dot Product
- \(v_i\) ㅣ 각 Key에 연결된 Value
- \(m_k = \max_{i \in \{1, \ldots, k\}} s_i\) ㅣ 수치적 불안정(Numerical Instability)를 방지
- where
- \[c_k = \sum_{i=1}^{k} \exp(s_i - m_k)\]
- \(c_k\) ㅣ Attention 값을 Scaling하여 정규화합니다.
- 병렬 계산(Parallel Computation)
- 앞서 제안된 Associative Operator \(\oplus\) 세개의 변수를 결합하고 평가합니다.
- \(m_A\) ㅣ 집합 A에서의 최대 점수
- \(u_A = \sum_{i \in A} \exp(s_i - m_A)\) ㅣ 컨텍스트에서 발견된 총 중요도
- \(w_A = \sum_{i \in A} \exp(s_i - m_A)v_i\) ㅣ 컨텍스트에서 집계된 값
- 앞서 제안된 Associative Operator \(\oplus\) 세개의 변수를 결합하고 평가합니다.
- 출력
Associative Operator를 적용하면 아래와 같이 계산됩니다.
\[\{(m_{1,\ldots,k}, u_{1,\ldots,k}, w_{1,\ldots,k})\}_{k=1}^N = \{(m_k, u_k, w_k)\}_{k=1}^N.\]최종적인 Many-to-many Attention 출력입니다.
\[\text{Attention}(q, x_{1:k}) = o_k = a_k \cdot c_k.\]
Aaren
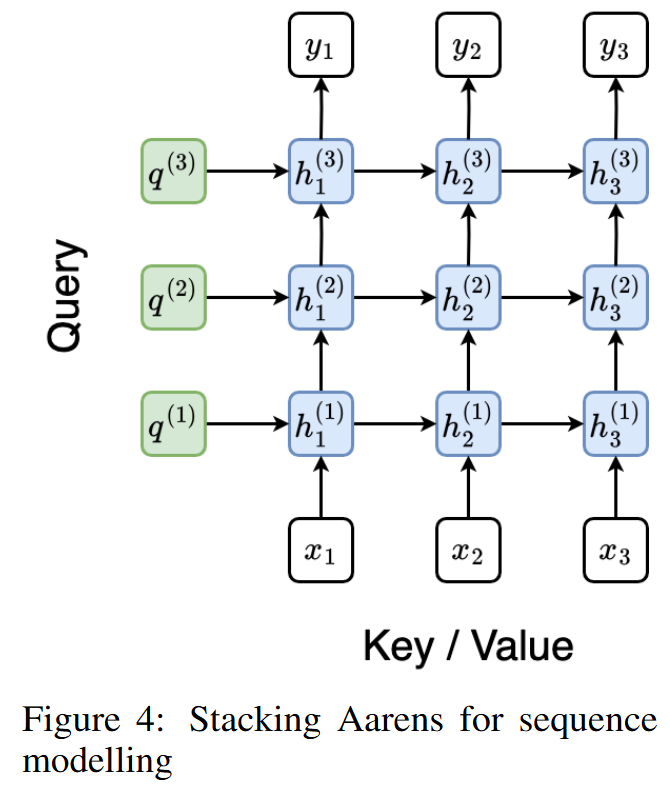
- RNN으로서의 Attention
- Aaren은 순환 신경망(RNN)으로서의 어텐션(Attention as a Recurrent Neural Network)을 의미하며, Many-to-many RNN 방식의 Attention 알고리즘을 기반으로 개발되었습니다.
- 입력과 출력
- Input ㅣ \(N\)개의 컨텍스트 토큰 입력을 받습니다.
- Output ㅣ \(N\)개의 출력을 생성하며, \(i\)번째 출력은 처음 \(i\)개의 입력으로부터 계산된 것입니다.
- 각 출력은 해당 시점까지의 이전 입력 정보를 집계합니다.
- Aaren은 층(Stack) 구조로 쌓을 수 있어 여러 층(Layer)으로 확장할 수 있습니다.
각 토큰에 대해 각각의 Loss를 계산합니다.
- Query Mechanism
- Aaren에서 쿼리 토큰 \(q\)는 단순한 입력 토큰 중 하나가 아니며, 역전파(Backpropagation)를 통해 학습되어 모델의 Adaptability를 높이는 역할을 합니다.
- Transformer가 사용하는 Self-attention과 다르게, Many-to-many RNN 연산을 활용하여 더 효율적으로 작동합니다.
- Transformer는 추론 시 선형 메모리를 요구하지만, Aaren은 상수 메모리만을 요구합니다.
- 모든 이전 시점들의 토큰들을 저장할 필요가 없어 더 빠르게 데이터를 처리할 수 있습니다.
- 작동 방식
- 초기화(Initialization) ㅣ Initial State는 \(h(0)\)로 표현되며, 입력 토큰 \(( h(0)_1, h(0)_2, \ldots, h(0)_N )\)는 입력 값 \((x_1, x_2, \ldots, x_N)\)에 대응합니다.
- 재귀 연산(Recursion) ㅣ 각 출력은 이전 시점의 Hidden State와 현재 시점의 입력 토큰을 사용하여 다음 시점의 Hidden State를 계산합니다.
- Aaren이 이전 출력과 현재 쿼리를 재활용하여 Hidden State를 업데이트하는 것입니다.
Aaren의 효율성
- 메모리 복잡도(Memory Complexity)
- Transformer (KV 캐싱 사용) ㅣ 추론 시 토큰 수에 비례하여 메모리 사용량이 선형적으로 증가합니다.
- Aaren ㅣ 토큰 수와 상관없이 상수 메모리만을 사용하여 메모리 효율성이 뛰어납니다.
시간 복잡도(Time Complexity)
Transformers ㅣ 토큰을 처리하는 데 필요한 누적 시간 복잡도는 \(O(N^2)\)입니다.
\(O(1 + 2 + ... + N) = O\left(\frac{N(N + 1)}{2}\right) = O(N^2)\)
- 순차적으로 정수가 더해지기 때문에 Quadratic Complexity를 가집니다.
Aaren ㅣ 토큰을 처리하는 데 필요한 누적 시간 복잡도는 \(O(N)\)으로, Transformer에 비해 선형적인 시간 효율성을 보입니다.
파라미터 수
- Transformer와 비교하여 Aaren은 Initial Hidden State \(q\)를 학습하기 때문에 조금 더 많은 파라미터가 필요합니다.
- Transformers 파라미터 ㅣ 3,152,384
- Aaren 파라미터 ㅣ 3,152,896
- 메모리나 시간 효율성에서 얻는 이점에 비하면 미미한 수준의 차이입니다.
- Transformer와 비교하여 Aaren은 Initial Hidden State \(q\)를 학습하기 때문에 조금 더 많은 파라미터가 필요합니다.

Conclusion
- 본 논문은 Attention이 특정 유형의 RNN으로 해석될 수 있음을 보여주면서, Parallel Prefix Scan 알고리즘을 활용하여 새 토큰을 효율적으로 업데이트할 수 있는 Many-to-many Attention 계산 방법을 제안하였습니다.
- Aaren은 Transformer와 유사하게 병렬 학습이 가능하며, 추론 시 일정한 메모리(Constant Memory)만을 요구하여 전통적인 RNN과 유사한 효율성을 보입니다.
- Aaren은 강화 학습, 이벤트 예측, 시계열 분류, 시계열 예측 등 네 가지 영역의 총 38개 데이터셋에서 검증되었으며, Transformer와 유사한 성능을 유지하면서도 시간/메모리 효율성 측면에서 더 우수한 결과를 보여주었습니다.