정형데이터에는 딥러닝이 부적절한 이유 | Tabular Data, Deep Learning
📊 정형 데이터에 딥러닝이 적절하지 않은 이유와 Tree 기반 모델의 장점을 알아봅시다.
정형데이터에는 딥러닝이 부적절한 이유 | Tabular Data, Deep Learning
KEYWORDS
정형데이터 딥러닝, 정형데이터 특징, 정형데이터란, 정형데이터 모델, 정형데이터 딥러닝 모델, Tabular Data, Tree-based Model
Original Paper Review | Why do tree-based models still outperform deep learning on typical tabular data?
Introduction
- 이미지나 텍스트와 같은 비정형 데이터에는 CNN, RNN, Transformer, … 과 같은 딥러닝 모델이 다양하게 활용되고 있으며 이들은 강력한 성능을 보입니다.
- 하지만 여러 AI 대회나 논문에서 알 수 있듯, Tabular 데이터 (표 형태 데이터) 분석/예측에 딥러닝을 사용하는 경우는 매우 드물며 Tree 기반 모델들이 SOTA를 달성하는 경우가 많습니다.
- 이번 포스팅에서는 정형 데이터에서 Tree 기반 모델이 딥러닝 모델에 비해 월등한 성능을 내는 이유를 분석한 논문을 살펴보고자 합니다.
딥러닝과 Inductive Bias
- Inductive bias는 모델이 어떤 가정을 데이터로부터 학습할 것인지 결정하는 데 영향을 미치므로, 딥러닝은 데이터에 Inductive Bias를 부여하고 어떤식으로 학습할지에 대한 방향을 설정합니다.
- 이미지 데이터를 딥러닝으로 다룰 때, 데이터의 Locality를 모델에 반영하기 위해 Convolution이나 ViT의 Patch Embedding과 같은 구조를 활용합니다. 반면, 정형 데이터는 Feature 간의 차이가 크고(Heterogeneous), 데이터 양도 적으며 Extreme Value를 가지는 경우가 많기에 딥러닝으로 불변성(Invariance)을 찾기가 힘듭니다.
- 논문에서는 Tabular 데이터에 대한 Inductive Bias는 Tree 기반 모델에 있다고 말합니다.
Tree 기반 모델과 딥러닝 모델 비교 실험
- Deep Models ㅣ MLP, Resnet, FT_Transformer
- Tree-based Models ㅣ Random Forest, Gradient Boosting Trees, XGBoost
- 저자는 총 45개의 Tabular 데이터로 구성된 Medium-size 데이터 셋으로 다양한 비교 실험을 진행했습니다.
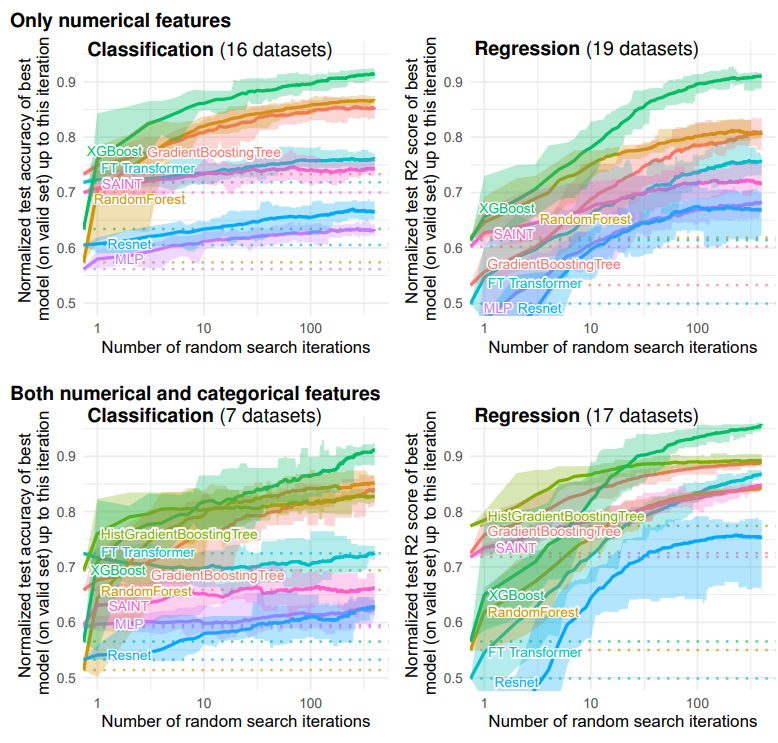
- 전반적으로 Tree 기반 모델들이 딥러닝 모델들에 비해 성능이 높습니다.
- 하이퍼 파라미터 튜닝은 신경망 기반 모델을 좋게 만들 수 없을 뿐더러, Tree 기반 모델들은 모든 Random Search 단계에서 좋은 성능을 보였습니다.
- 또한, Categorical 변수들 뿐만 아니라 Numerical 변수들도 신경망을 약화시킵니다. (Numerical 변수만 사용한 경우에도 Tree 기반 모델이 뛰어남)
- 이러한 원인은 오버피팅과 같은 단순한 문제에서 오는 것이 아닌, 딥러닝의 Inductive Bias가 Tabular 데이터에 적합하지 않기 때문입니다.
해석 1. Tabular 데이터는 경계면이 Smooth 하지 않으며, 딥러닝 모델은 과하게 Smoothing 되어 있기 때문이다.
- 저자는 Gaussian Kernel을 이용하여 학습데이터의 Output을 Smoothing 시킨 후 Kernel의 Length Scale에 따른 모델 성능을 비교했습니다.
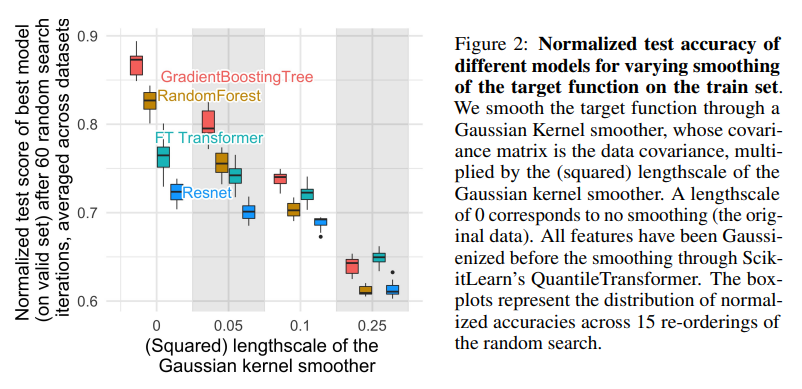
- Length Scale이 커질수록 더 Output이 Smoothing 되었음을 의미하며, Output이 더 Smooth 해짐에 따라 Tree 기반 모델이 딥러닝 모델들에 비해 성능이 더 급격하게 감소합니다.
- 해석하자면, 정보량이 거의 없는 Smooth한 변수들이 이미 딥러닝 모델에 더 많은 영향을 주고 있었으며, 딥러닝 모델들이 학습하는 경계면이 과하게 Smoothing 되어 있다는 것입니다.
“The target functions in our datasets are not smooth, and that neural networks struggle to fit these irregular functions compared to tree-based models.”
“Neural networks are biased to overly smooth solutions”
해석 2. MLP는 Tabular 데이터의 정보량이 적은 Feature에 취약하다.
- Tabular 데이터의 feature를 제거함에 따른 GBT(Gradient Boosting Trees) 의 분류 성능을 살펴본 것입니다.
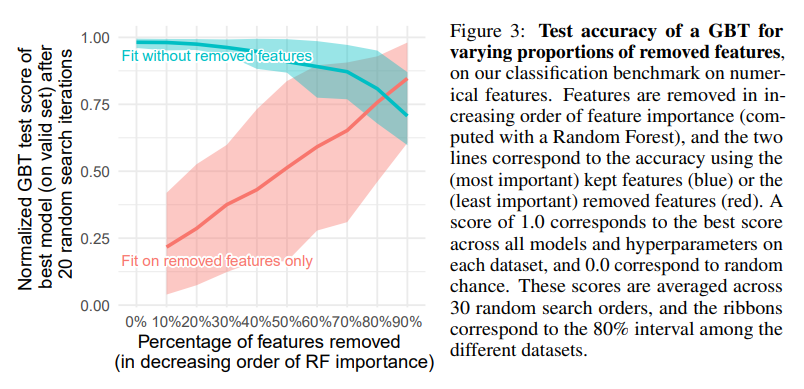
- Feature 들은 Random Forest로 계산된 Feature Importance를 기준으로 제거되며,
파란선은 Importance가 낮은 Feature들을 먼저 제거한 경우이고빨간선은 Importance가 높은 Feature들을 먼저 제거한 경우 입니다. 파란선을 보면 절반정도의 Feature를 제거해도 GBT의 성능은 크게 악화되지 않으며,빨간선을 보면 Importance가 낮은 Feature들로 학습한 경우 성능이 좋지 않음을 확인할 수 있습니다.- Tree 기반 모델(Gradient Boosting Tree, Random Forest)과 딥러닝 모델(FT Transformer, Resnet)을 비교합니다.
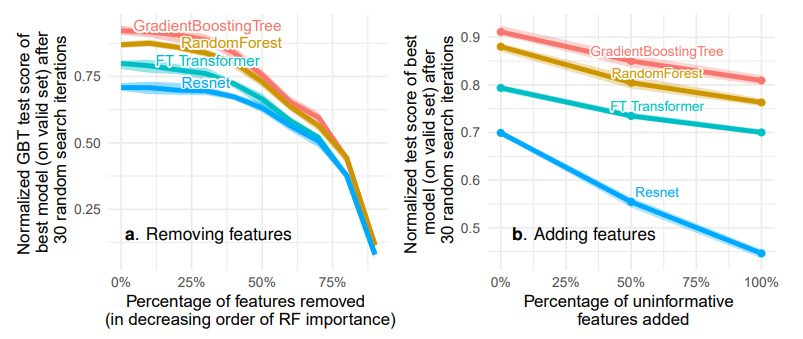
- 좌측 그림은 정보량이 없는(Importance가 낮은) Feature들을 순서대로 제거한 결과이며, 이때 MLP와 Tree 기반 모델들의 성능 차이가 줄어듭니다.
- 우측 그림은 정보량이 많은 Feature들을 순서대로 추가하여 학습하면 MLP와 Tree 기반 모델들의 성능 차이가 커집니다.
- 따라서, MLP는 Tree 기반 모델들에 비해 과하게 Smoothing 되기 때문에 Heterogeneous 한 데이터에 적합하지 않아 성능이 저조하다는 사실을 알 수 있습니다.
- 두 실험 모두 Tree 기반 모델들이 가장 좋은 성능을 보입니다.
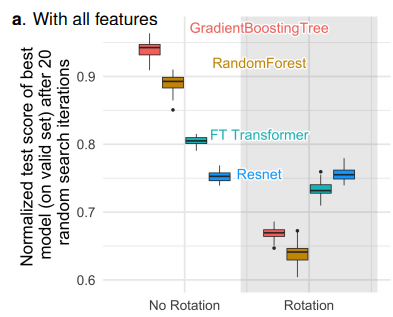
해석 3. 데이터는 회전 Rotation 에 Invariant 하지 않다.
- 딥러닝 모델은 학습 및 테스트 과정에서 데이터의 Feature에 회전을 적용해도 결과가 변경되지 않습니다(Rotationally Invariant 함).
- 하지만 Tree 기반 모델들은 이러한 회전에 대해 Invariant 하지 않습니다. 즉, 데이터의 방향에 포함된 정보가 손실 될 가능성이 있습니다.
- 아래 Figure를 보면, Feature들을 회전했을 때 딥러닝 모델들에 비해 Tree 기반 모델들의 성능이 더 크게 떨어집니다.
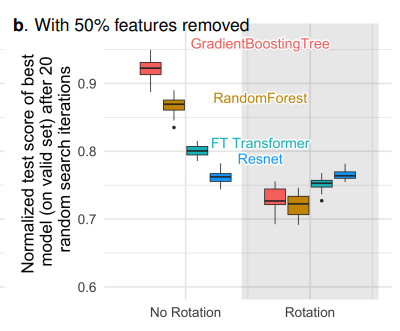
- 정보량이 적은 Feature을 절반정도 제거한 뒤 회전한 결과입니다. 앞선 경우에 비해서 Tree 기반 모델들의 성능 감소가 덜합니다.
- 이는 정보량이 상대적으로 많은 Feature들을 회전하는 것이 전체를 회전하는 것 보다는 낫다는 것을 의미합니다.
결론
- 딥러닝이 모든 데이터에 대해 항상 우월한 것은 아닙니다. 데이터 셋에 맞는 모델을 사용하는 것이 중요합니다. :)
Reference
- Grinsztajn, Léo, Edouard Oyallon, and Gaël Varoquaux. “Why do tree-based models still outperform deep learning on typical tabular data?.” Advances in neural information processing systems 35 (2022): 507-520.
This post is licensed under CC BY 4.0 by the author.