VLM 이해해보기 | Vision-Language Model
😎 Vision Language Model(VLM)의 개념과 장점들을 소개합니다.

KEYWORDS
VLM 모델, VLM 이란, VLM 모델 종류, VLM SOTA, VLM Survey, Vision Transformer
Original Paper Review | An introduction to vision-language modeling
Abstract
- Vision-Language Models(VLMs)은 텍스트 데이터와 함께 시각 정보를 통합하여 대형 언어 모델(LLMs)을 확장합니다.
- VLMs는 고수준 텍스트 설명을 바탕으로 이미지를 생성할 수 있습니다.
- Challenges
- VLMs의 신뢰성을 개선하는 데는 상당한 어려움이 존재합니다.
- 언어는 이산적(불연속적) 개념으로 작동하는 반면, 시각은 복잡하고 고차원 공간에서 작동하기 때문에 개념을 직접적으로 번역하기 어렵습니다.
Introduction
- Llama와 ChatGPT와 같은 최신 언어 모델 발전으로 이들 모델은 다양한 작업에서 높은 능력을 보이고 있습니다.
- 처음에는 텍스트 중심이었던 모델들이 이제 시각적 입력까지 처리하게 되면서 새로운 응용 분야가 열리고 있습니다.
- 언어와 시각을 연결하는 데는 여전히 Challenge들이 존재합니다.
- 공간 관계 이해의 어려움.
- 개수 세기 문제 및 추가 데이터 주석 필요.
- 속성과 순서에 대한 이해 부족.
- 프롬프트 설계 문제와 결과물에서의 환각 현상.
The families of VLMs
- VLMs(Vision-Language Models)는 컴퓨터 비전과 자연어 처리를 연결하기 위해 Transformer 구조를 주로 활용합니다.
Training Paradigms
- 대조 학습(Contrastive Training) ㅣ 긍정 및 부정 예시 Pair을 사용하여 모델이 긍정 Pair에는 유사한 표현을, 부정 Pair에는 다른 표현을 학습하도록 합니다.
- 마스킹(Masking) ㅣ 데이터의 마스킹된 부분을 재구성하는 방식입니다.
- 생성형(Generative) ㅣ
VLMs는 스스로 이미지나 텍스트(캡션)를 생성할 수 있으며, 이러한 모델은 기능이 복잡하여 일반적으로 학습 비용이 더 많이 듭니다.
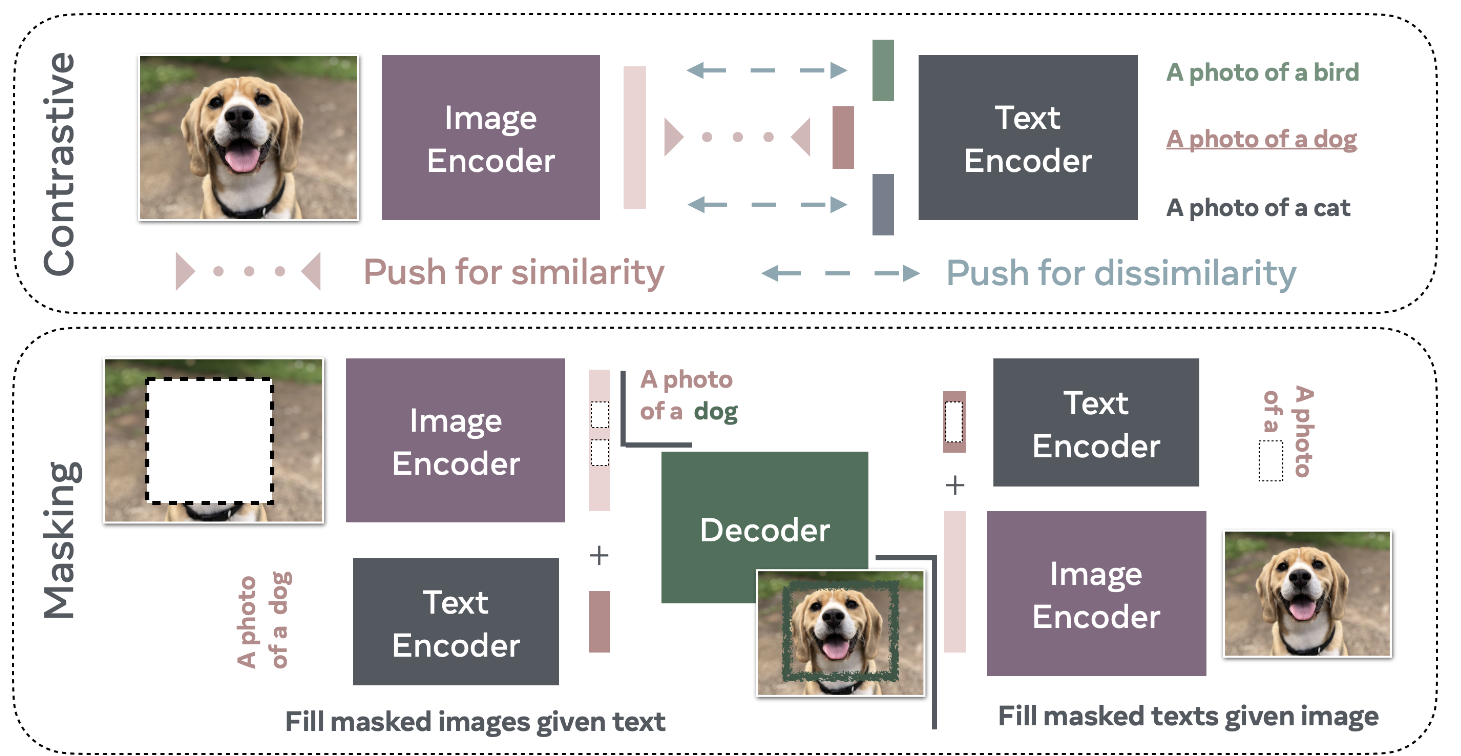
 The training paradigms of VLMs 1
The training paradigms of VLMs 1
Pretrained Backbones
- 주로 기존 대형 언어 모델(ex. Llama)을 사용하여 이미지 인코더와 텍스트 인코더 간의 연결을 만듭니다.
- 이 방법은 모델을 처음부터 학습시키는 것보다 일반적으로 자원 소모가 적습니다.
Early Works
- Transformer 기반의 양방향 인코더 표현 (BERT) (2019)
- visual-BERT, ViL-BERT ㅣ 텍스트와 함께 시각 데이터를 통합하여 이해도를 높입니다.
- 이러한 모델은 두 가지 주요 작업으로 학습됩니다:
- 마스킹 모델링 작업은 입력에서 누락된 부분을 예측하여 모델이 누락된 정보를 학습하도록 돕습니다.
- 문장-이미지 예측 작업은 텍스트 캡션이 이미지의 내용을 설명하는지를 예측하여 언어와 시각 정보 간의 연결을 강화합니다.
1. Contrastive-based VLMs
Energy-Based Models (EBMs)
- EBM은 모델 \(E_\theta\)를 학습하여 관측된 데이터에는 낮은 에너지를, 보지 못한 데이터에는 높은 에너지를 할당합니다.
- 목표는 실제 데이터(낮은 에너지)와 노이즈 또는 관측되지 않은 데이터(높은 에너지)를 구분하는 것입니다.
- 에너지 함수는 \(E_\theta (x)\)로 정의되며, 여기서 \(x\)는 입력 데이터, \(\theta\)는 모델의 파라미터입니다.
Boltzmann Distribution
모델에서 입력 \(x\)에 대한 확률 밀도 함수(Probability Density Function)는 다음과 같습니다. \(p_\theta (x) = \frac{e ^{- E_\theta (x)}}{Z_\theta},\)
- where
- \(E_\theta (x)\) ㅣ the energy of input \(x\).
- \(Z_\theta = \sum_x e^{-E_\theta (x)}\) ㅣ the normalization factor ensuring \(p_\theta (x)\) sums to 1 over all \(x\).
- where
Maximum Likelihood Objective
- 학습 목표는 모델 예측과 실제 데이터 간의 불일치(Discrepancy)를 최소화하는 것입니다. \(arg \min_\theta E_{x \sim P_D} (x) [- \log p_\theta (x)]\)
Gradient of the Gradient
목표 함수의 Gradient는 다음과 같이 계산됩니다. \(\frac{\partial E_{x \sim P_D}(x)[-\log p_\theta(x)]}{\partial \theta} = E_{x^+ \sim P_D}(x) \frac{\partial E_\theta(x^+)}{\partial \theta} - E_{x^- \sim P_\theta}(x) \frac{\partial E_\theta(x^-)}{\partial \theta},\)
where
- \(x^{+} \sim P_D (x)\) = samples from the real data distribution.
- \(x^{-} \sim P_D (x)\) = samples from the model’s distribution.
- 첫 번째 항은 모델이 실제 데이터에 적합하도록 조정하고, 두 번째 항은 부정 샘플과 구분하는 데 도움을 줍니다.
Noise Contrastive Estimation (NCE)
- 모델 분포를 근사하기 위해 노이즈 분포에서 샘플링을 사용합니다.
NCE는 이진 분류 문제로 정의됩니다.
- 실제 데이터는 \(C=1\), 노이즈는 \(C=0\)으로 예측합니다.
NCE 손실 함수
\(L_{NCE}(\theta) := - \sum_{i} \log P(C_i = 1 | x_i; \theta) - \sum_{j} \log P(C_j = 0 | x_j; \theta),\)- where \(x_i\) = samples from real data distribution.
- \(x_j \sim p_n (x)\) 는 노이즈 분포에서 추출한 샘플로, 일반적으로 무작위 노이즈 프로세스에서 생성됩니다.
Contrastive Language–Image Pre-training(CLIP)
- 이미지와 해당 텍스트(캡션)의 공통 표현을 학습하기 위함입니다.
- 학습 방법
- 대조 학습 메커니즘으로 InfoNCE 손실을 사용합니다.
- 긍정 예시 ㅣ 이미지와 그에 해당하는 올바른 캡션 쌍.
- 부정 예시 ㅣ 같은 이미지와 미니 배치 내의 다른 이미지 캡션들.
- 공유 표현 공간
- CLIP은 이미지와 캡션을 유사한 벡터 공간으로 매핑하여 함께 처리할 수 있게 합니다.
- 학습 데이터
- 인터넷에서 수집한 4억 개의 캡션-이미지 쌍으로 초기 학습되었습니다.
- 성능
- CLIP은 탁월한 제로샷 분류 능력을 보입니다.
- 이는 명시적으로 학습되지 않은 카테고리도 분류할 수 있음을 의미합니다.
- ResNet-101 CLIP은 지도 학습된 ResNet 모델과 유사한 성능을 보였으며, Zero-shot 분류 정확도는 76.2%를 달성했습니다.
- CLIP은 탁월한 제로샷 분류 능력을 보입니다.
- 변형
- SigLIP은 이진 교차 엔트로피를 포함한 NCE 손실 함수를 사용합니다.
- CLIP보다 작은 배치 크기에서 Zero-shot 성능이 더 우수합니다.
- 잠재 언어-이미지 사전학습 (Latent Language Image Pretraining, Llip)은 이미지에 다양한 캡션을 적응시키는 데 중점을 둡니다.
- Cross-attention module을 통해 이미지 인코딩을 다양한 캡션과 더 잘 연결하여 분류 및 검색 작업에서 성능을 향상시킵니다.
- SigLIP은 이진 교차 엔트로피를 포함한 NCE 손실 함수를 사용합니다.
2. Masking
- 마스킹은 특정 데이터 포인트가 모델 출력에 영향을 미치지 않도록 하는 기법입니다.
- Denoising Autoencoder와의 관계
- Denoising Autoencoder와 유사하게, 마스킹은 공간적 구조를 가진 데이터의 누락된 부분을 예측하는 작업을 포함합니다.
- 이미지 인페인팅 기법과도 연결되며, 이미지의 일부를 재구성하는 방식입니다.
Masked Language Modeling (MLM)
- 2019년 BERT가 도입한 방식으로, 문장에서 누락된 단어를 예측하는 마스킹 접근법을 사용하여 Transformer 네트워크에서 효과적입니다.
Masked Image Modeling (MIM)
- 대표적인 예시로 MAE (2022)와 I-JEPA (2023)가 있으며, 이미지 표현 학습에 마스킹 기법을 적용합니다.
VLMs with Masking Objectives
- FLAVA (2022)
- 텍스트와 이미지를 통해 표현을 학습하기 위해 마스킹 기법을 활용했습니다.
- 이미지와 텍스트에 별도의 인코더를 두어 학습 중에 마스킹을 적용하고, 다층 데이터 융합을 가능케 했습니다.
- 여러 센서 모달리티에서 최첨단 성능을 달성했습니다.
- MaskVLM (2023)
- 픽셀 및 텍스트 토큰 공간에 직접 마스킹을 적용하여 사전 학습된 모델에 대한 의존성을 줄였습니다.
Information Theoretic Perspective on VLM
- VLM이 학습된 표현의 관련성을 극대화하면서 불필요한 정보를 최소화하는 Rate-distortion problem를 해결하여 효율적으로 정보를 인코딩하는 방법을 다룹니다.
\(\text{arg min}_{p(z|x)} I(f(X); Z) + \beta \cdot H(X|Z),\)- where
- \(I(f(X); Z)\) = 입력 데이터 \(f(X)\)와 표현 \(Z\) 간의 관련성을 측정하는 상호 정보.
- \(\beta\) = 두 번째 항의 영향을 결정하는 trade-off parameter.
- where
- 위 목표를 bound하는 또 다른 방정식은 다음과 같습니다.
\(L = - \sum_{x \in D} E_{p(f)} p(Z|f(x)) [\log q(z) + \beta \cdot \log q(x|z)],\)- where
- \(q(z)\) = 학습된 표현의 분포
- \(D\) = 표현을 생성하기 위해 사용되는 데이터셋
- where
- 이 방정식은 의미 있는 표현을 얻는 것과 원래 입력에서 중요한 세부 정보를 유지하는 것 사이의 균형을 강조합니다.
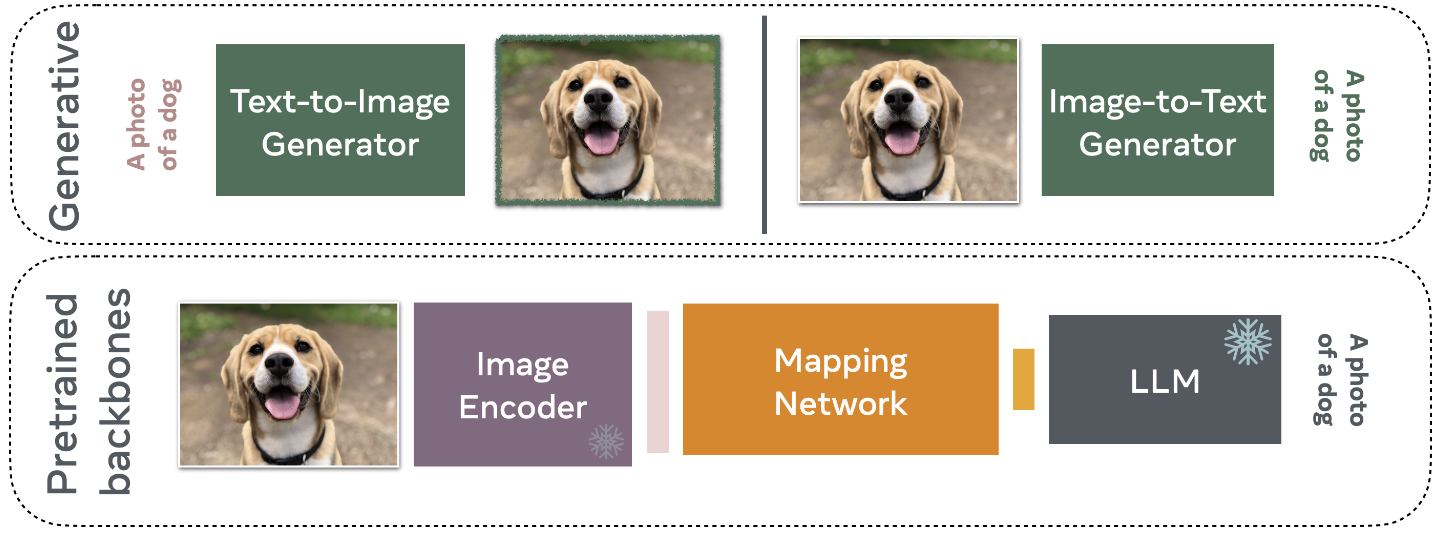
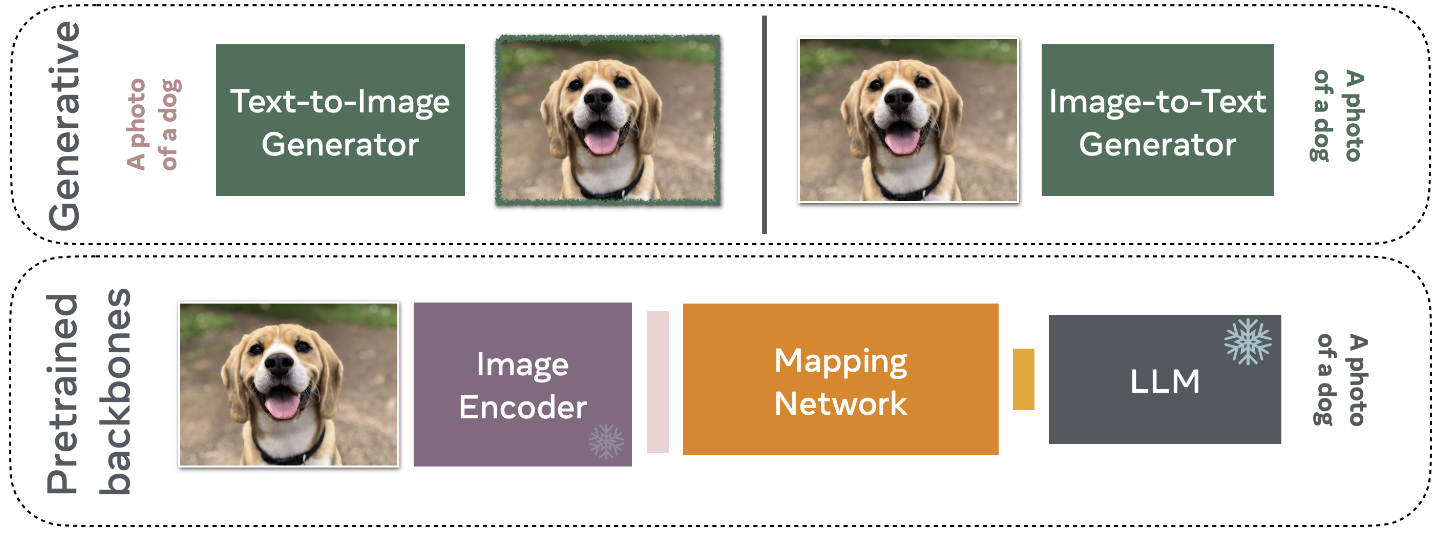
3. Generative-based VLMs
- 주로 Latent representations (잠재 표현, 추상적 특징)을 다루는 이전 모델과 달리, 생성 모델은 텍스트와/또는 이미지를 직접 생성합니다.
CoCa
- CoCa는 이미지 캡션 생성과 같은 작업을 위해 전체 텍스트 인코더와 디코더를 학습합니다.
- 손실 함수 ㅣ 새로운 생성 손실과 대조 손실을 사용하여 추가 모듈 없이도 새로운 multi-modal 이해 작업을 수행할 수 있습니다.
- 사전 학습 ㅣ ALIGN(대체 텍스트가 포함된 18억 개 이미지)과 JFT-3B(대체 텍스트로 처리되는 29,500개 이상의 클래스)와 같은 데이터셋을 활용합니다.
CM3Leon
- 텍스트-이미지 및 이미지-텍스트 생성을 위한 기초 모델.
- Tokenization ㅣ 텍스트와 이미지의 교차 처리를 가능하게 하는 특수 토큰을 사용합니다.
- Training Process
- 1단계 (Retrieval-Augmented Pretraining) ㅣ CLIP 기반 인코더를 사용해 입력 시퀀스에 관련된 multi-modal 문서를 추가하고 다음 토큰 예측을 통해 학습을 수행합니다.
- 2단계 (Supervised Fine-tuning) ㅣ 다중 작업 지시 조정을 통해 모달리티 간 콘텐츠 생성 및 처리를 가능하게 하여 다양한 작업에서 성능을 향상시킵니다.
Chameleon
- 텍스트와 비텍스트 콘텐츠가 섞인 상황에서 생성과 추론을 위한 혼합 모달 기초 모델을 도입합니다.
- Architecture ㅣ 처음부터 텍스트와 이미지를 모두 토큰 기반 표현으로 사용하는 통합된 구조를 활용합니다.
- Early-Fusion Strategy ㅣ 텍스트와 이미지 모달리티를 처음부터 공통 표현 공간으로 매핑하여 최적화 문제를 해결하며 견고한 생성 및 추론 능력을 제공합니다.
Using Generative Text-to-image Models for Downstream Vision-language Tasks
Stable Diffusion과 Imagen 같은 최근 모델의 발전으로 이 시스템들은 텍스트 프롬프트에 따라 이미지를 생성할 수 있습니다.
일반적으로 이미지 생성 모델로 알려져있으며, 별도의 재학습 없이도 분류와 캡션 예측 작업을 수행할 수 있습니다.
- Classification via Bayes' Theorem
이미지 \(x\) 와 텍스트 클래스 집합 \((c_i)^n _{i=1}\)이 주어졌을 때, 모델은 베이즈 정리를 사용해 이미지를 분류할 수 있습니다.
\(p_\theta(c_i | x) = \frac{p(c_i) p_\theta(x | c_i)}{\sum_{j} p(c_j) p_\theta(x | c_j)},\)where
- \(p (c_i)\) ㅣ 클래스 \(c_i\)의 Prior probability.
- 분모는 모든 클래스에 대한 Likelihood을 합산하여 확률을 정규화합니다.
- Generative Classifiers
- Analysis by Synthesis으로 알려진 이 접근법은 나이브 베이즈와 선형 판별 분석과 같은 생성 모델을 기반으로 한 초기 기법과 연결됩니다.
- 계산 비용이 많이 들지만 생성 분류기는 더 큰 Effective Robustness을 제공하여, CLIP과 같은 판별 모델보다 Out-of-distribution 시나리오에서 더 잘 작동합니다.
- 이러한 분류기는 모양 편향이 증가하고 인간의 판단과 더 잘 일치합니다.
- 또한, 라벨이 없는 테스트 데이터만을 사용해 판별 모델과 공동으로 적응할 수 있어 다양한 작업에서 성능이 향상됩니다.
VLMs from Pretrained Backbones
- Vision-Language Models(VLMs)의 학습에는 매우 비용이 많이 들며, 방대한 계산 자원(수백에서 수천 개의 GPU)과 대규모 데이터셋(수억 개의 이미지와 텍스트 쌍)이 필요합니다.
- 비용을 줄이기 위해 연구자들은 VLMs를 처음부터 구축하는 대신, 기존의 LLMs과 Visual Feature Extractor를 활용하는 데 집중하고 있습니다.
- 학습된 모델을 활용함으로써 연구자들은 텍스트와 이미지 모달리티 간의 매핑을 학습하려고 하며, 이를 통해 LLMs가 시각적 질문에 적은 계산 자원으로 응답할 수 있게 됩니다.
Frozen
- Frozen은 시각적 특징을 텍스트 임베딩으로 변환하는 경량화된 매핑 네트워크를 통해 비전 인코더와 LLM을 연결하는 선도적인 모델입니다.
- Architectures
- Vision Encoder ㅣ NF-ResNet-50을 처음부터 학습시킵니다.
- Language Model ㅣ 사전 학습된 Transformer (70억 개의 파라미터)를 “Frozen” 시켜 미리 학습된 특징을 보존합니다.
- Training Objective ㅣ Conceptual Captions 데이터셋을 기반으로 간단한 텍스트 생성 목표를 사용합니다.
- 기능
- 시각적 및 언어적 요소의 빠른 작업 적응과 효율적인 결합을 보여주며, Multi-modal LLMs의 중요한 발전을 나타냅니다.
The Example of MiniGPT
- MiniGPT-4는 텍스트와 이미지 입력을 모두 받아들이며, 단순한 Linear Projection Layer을 통해 이미지와 텍스트 표현을 정렬하여 텍스트 출력을 생성합니다.
- 대규모 데이터셋 (500만 개의 이미지-텍스트 쌍)을 사용하여 4개의 A100 GPU로 짧은 시간(10시간) 내에 학습됩니다.
- Instruction-tuning Phase에서는 고도로 선별된 데이터로 400번의 Training Step을 거칩니다.
Other Popular Models using Pretrained Backbones
- Qwen-VL 및 Qwen-VL-Chat은 비전 표현을 LLM 입력 공간에 정렬하며, 압축을 위한 Transformer 층을 사용합니다.
- 이미지를 처리하여 텍스트를 생성하는 비전-언어 모델 BLIP-2는 이미지와 텍스트 임베딩을 매핑하는 경량화된 컴포넌트(Q-Former)를 사용하며, 학습 속도를 높이기 위해 사전 학습된 모델을 활용합니다.